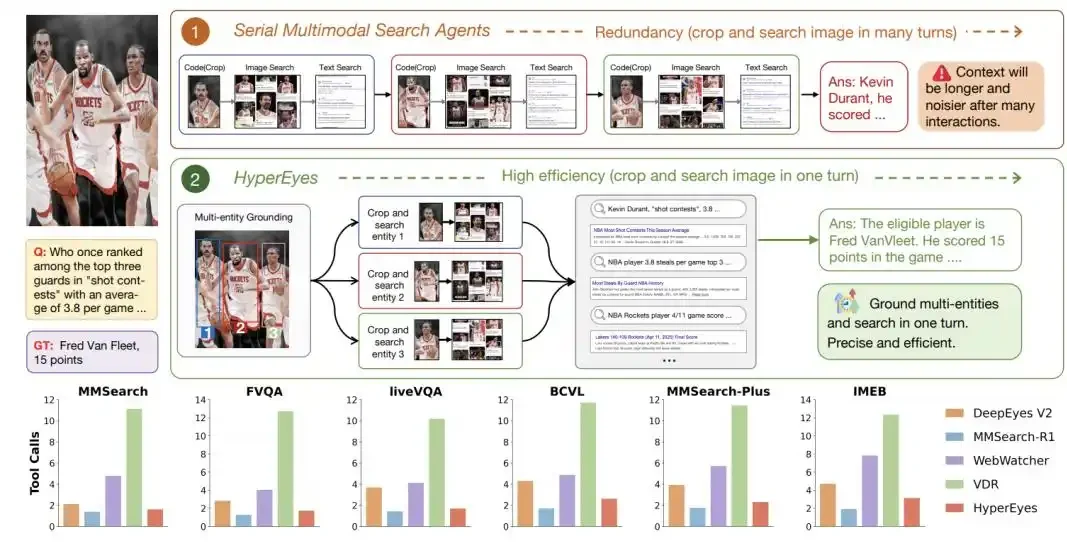
其核心突破在于将搜索逻辑从“搜得更深”转向“搜得更宽”,在准确率提升的同时显著降低延迟和错误传播风险。
HyperEyes技术原理
1. 动作空间重构:统一定位即搜索
- 传统模型将“视觉裁剪”和“网络搜索”分为独立步骤,需对每个目标逐一轮次调用。
- HyperEyes提出UGS方案,将视觉定位框直接作为检索动作的内嵌参数,使单次函数调用即可并发处理多个目标,从物理层面打通多目标并行通路。
2. 数据合成:零冗余并行行为种子库
- 针对开源社区缺乏并行搜索训练数据的问题,设计三阶段合成流水线:
- 多类图片拼接:生成需同时定位与检索的复杂视觉查询。
- 图谱随机游走:构造多约束交集问题并剔除捷径解。
- 渐进式拒绝采样(PRS):在严格轮次预算下提纯出3万条“零冗余”并行行为数据,解决监督微调(SFT)冷启动难题。
3. 双粒度效率感知强化学习
- 宏观轨迹层面(TRACE机制):
- 引入动态参考的成本效率奖励,以模型当前最优表现作为“自我超越”标尺。
- 仅当工具调用轮次低于历史最优时给予奖励,且标尺随训练过程自动收紧。
- 微观Token层面(OPD机制):
- 仅在轨迹失败时启动,调用235B教师模型为错误轨迹提供Token级稠密监督。
- 精准打捞正确中间步骤,避免“连坐惩罚”,同时保护高效行为不被覆盖。
HyperEyes核心功能与特色
1. 效率与准确率协同提升
- 工具调用轮次大幅降低:HyperEyes-30B平均仅需2.2轮,而传统模型VDR需11.6轮(降幅达81%)。
- 准确率显著超越开源模型:在6大基准测试中,HyperEyes-30B准确率达64.0%,比VDR高9.9个百分点;235B版本与闭源旗舰Gemini-3.1-Pro差距仅1.1%。
2. 错误隔离与强鲁棒性
- 传统串行模型存在错误级联风险:前置定位偏差会污染后续所有结果。
- HyperEyes的并行策略实现风险隔离:单个目标的检索错误不会影响其他目标,在真假证据混合测试中大幅规避幻觉陷阱。
3. 成本感知优化
- 提出成本感知评分(CAS),将准确率、Token消耗与工具调用轮次联合评估,量化为“单位延迟下的有效信息密度”。
- HyperEyes-30B的CAS得分达次优开源模型的7.6倍,证明其单位算力输出的信息密度极高。
HyperEyes典型应用场景
1. 高并发实时交互场景
- 电商平台视觉比价:用户上传含多商品的图片时,可同时检索所有商品价格与参数,避免逐一轮询导致的延迟。
- 内容社区信息检索:在小红书等平台,用户对复杂图片(如多人合影、多物品场景)的提问,能单次获取全部目标信息。
2. 复杂多实体分析任务
- 安防与低空监测:识别无人机群、多人行为时,避免串行定位导致的漏检或误判累积。
- 学术与专业研究:分析含多对象的科学图像,快速关联跨目标信息。
3. 资源受限环境
- 在算力有限的终端设备上,减少工具调用轮次可显著降低延迟与能耗,适用于移动端实时应用。
HyperEyes与传统方法的关键差异
表格
| 维度 | 传统串行模型 | HyperEyes |
|---|---|---|
| 交互逻辑 | N轮串行调用(延迟O(N)) | 单轮并行处理(延迟O(1)) |
| 错误处理 | 错误级联传播 | 风险隔离,单点错误不扩散 |
| 训练目标 | 仅关注最终答案准确率 | 兼顾效率与中间步骤质量 |
| 资源消耗 | Token与轮次随目标数线性增长 | 资源消耗基本恒定 |
HyperEyes的突破在于证明了准确率与效率并非此消彼长,而是可通过架构创新协同优化。
其技术路径为多模态智能体在电商、安防、内容平台等高并发场景的落地提供了新范式,尤其适合需实时响应多目标查询的业务需求。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...