LFM2.5-1.2B是Liquid AI推出的12亿参数轻量级AI模型家族,专为边缘设备与本地部署优化设计,最大特点是仅需约900MB内存即可在普通智能手机上流畅运行,同时通过创新的”思考链”机制实现高质量推理。该模型家族包含Base版、Instruct版、Thinking版等多类变体,在数学推理、工具调用等任务中性能甚至超越参数量更大的模型(如Qwen3-1.7B),成为端侧AI落地的关键技术突破。
LFM2.5-1.2B模型定位与核心特点
1. 端侧部署的极致优化
- 超低资源占用:
运行时内存占用控制在900MB以内,可在主流智能手机和边缘设备上离线运行,无需联网或依赖云端算力。 - 混合架构设计:
采用专为CPU/NPU优化的LFM2架构,结合线性注意力机制与权重压缩技术,在资源受限环境中保持高效推理,移动NPU上解码速度达82 token/s。
2. Thinking版的核心创新
- 先思考、后作答机制:
LFM2.5-1.2B-Thinking版本在输出答案前主动构建结构化思考路径,通过隐式推理链提升逻辑严谨性,显著减少直接生成导致的错误。 - 关键能力跃升:
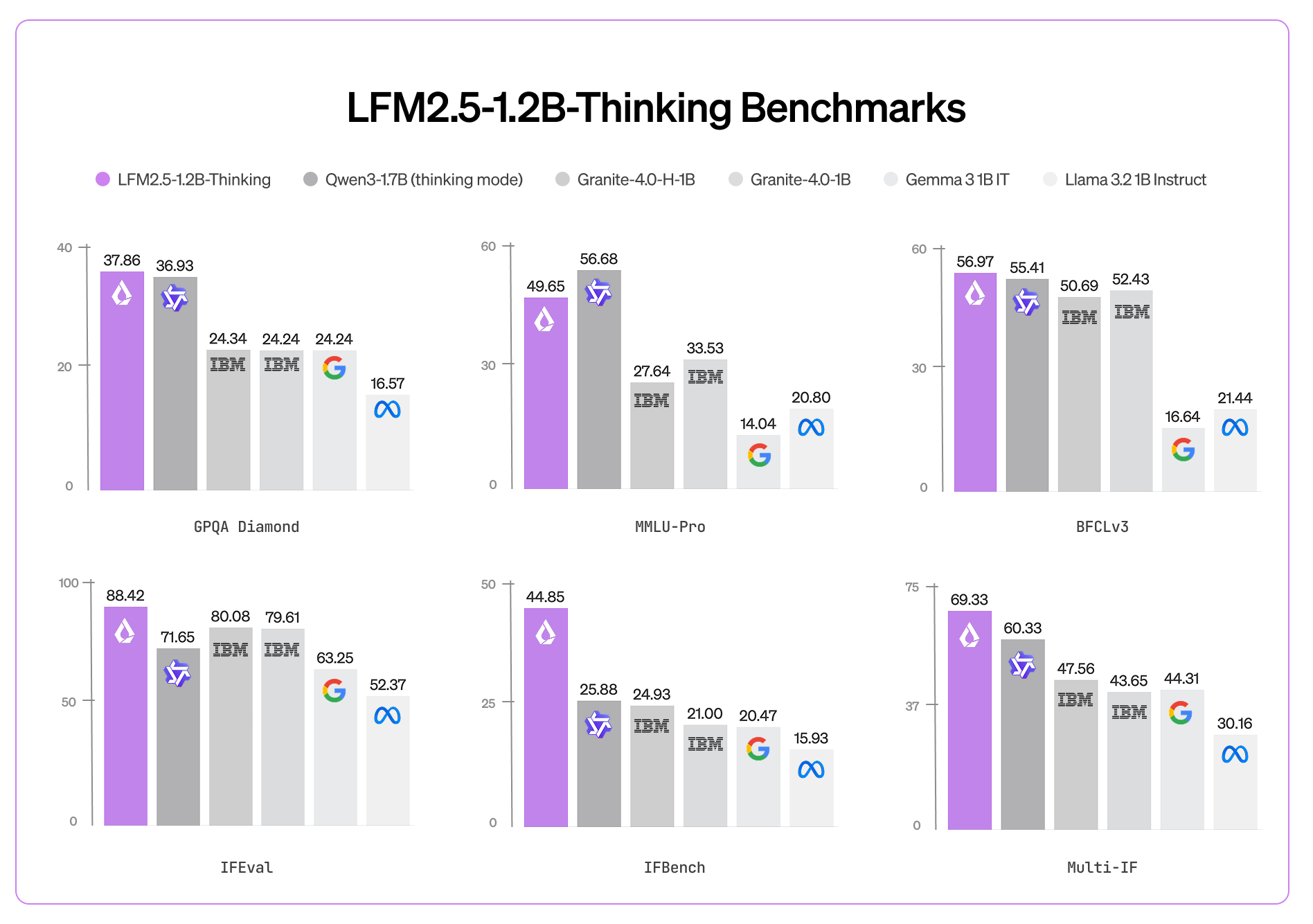
相比Instruct版,数学推理(MATH-500基准从63分→88分)、指令执行(Multi-IF从61分→69分)、工具调用(BFCLv3从49分→57分)均实现大幅进步。
LFM2.5-1.2B表现与基准测试
1. 推理能力对标大模型
- 参数效率优势:
尽管参数量比Qwen3-1.7B少40%,但在多项推理基准中全面反超,例如MMLU Pro得分达44.35,显著高于Llama-3.2-1B Instruct等同类10亿级开源模型。 - 多模态扩展能力:
- 视觉语言版(LFM2.5-VL-1.6B):支持文档理解、UI读取等任务,专为边缘环境优化。
- 音频语言版(LFM2.5-Audio-1.5B):音频反tokenizer速度比前代快8倍,适用于实时语音对话与ASR场景。
2. 量化部署的实用表现
- 存储与速度平衡:
Q4_K_M量化版本模型仅占680MB磁盘空间,推理时显存需求降至1.9GB以下,吞吐量达190 token/s。 - 质量分水岭:
Q5_K_S量化在代码生成与文本摘要任务中保持95%以上原始质量,而Q4_K_M开始出现可察觉的逻辑偏差,推荐生产环境优先选择Q5_K_M。
LFM2.5-1.2B应用场景与部署实践
1. 典型适用场景
- 离线智能助手:
在无网络环境中提供写作辅助、知识问答、代码生成等服务,数据全程本地处理,零隐私泄露风险。 - 边缘设备中枢:
部署于树莓派+USB NPU开发板,作为传感器数据摘要、异常描述生成的实时决策节点。 - 教育与开发工具:
学生编程学习机中的实时代码解析助手,或开发者本地调试的轻量级推理引擎。
2. 快速部署方案
- Ollama一键部署:
通过ollama pull lfm2.5-thinking:1.2b下载模型,3分钟内完成本地服务搭建,支持Mac/Windows/Linux全平台。 - 关键参数调优:
- 降低
num_ctx至2048可提速12%(适合短对话) - NPU设备保持
num_gpu=1以避免PCIe带宽瓶颈。
- 降低
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...