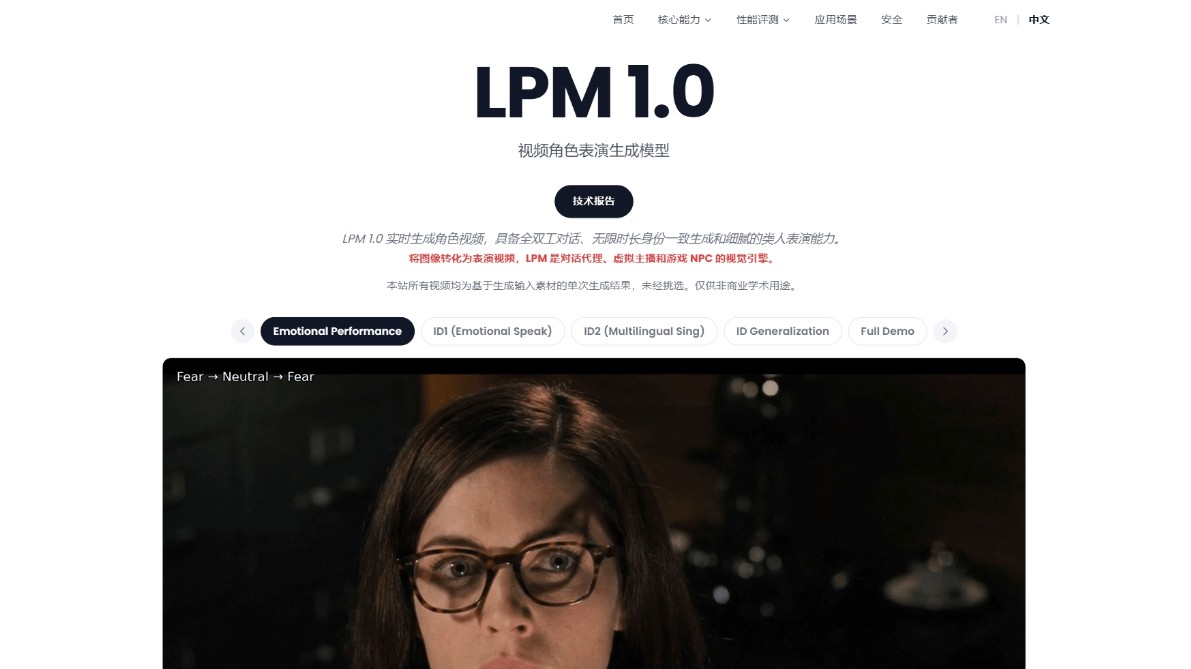
Gemini 3 Flash是谷歌推出的轻量级高性能多模态大模型,核心定位是以速度与成本效率为核心优化目标,在保持接近旗舰模型推理能力的同时,响应速度达到前代Gemini 2.5 Pro的3倍,且完成任务的token消耗量降低约30%。
该模型被设为Gemini应用和全球搜索AI模式的默认引擎,专为高频交互场景设计,尤其适合实时编码、多模态内容解析及“口述即原型”的快速开发任务。

Gemini 3 Flash核心特点与技术突破
1. 速度与成本的双重优化
- 极速响应能力:
首字响应时间(TTFT)显著缩短,在同等任务下输出速度达289 tokens/秒,较Gemini 2.5 Pro提升3倍,接近传统搜索引擎的交互体验。 - token效率提升:
通过动态计算资源分配机制,处理复杂任务时平均减少30%的token消耗,大幅降低高频调用场景的长期使用成本。
2. 多模态能力的实用化落地
- 全模态输入支持:
可直接解析文本、图像、音频、视频及代码,例如上传匹克球短视频获取技巧指导,或通过手绘草图生成交互式3D模型。 - 氛围编程(Ambient Programming):
用户仅需口述需求即可生成可运行的应用原型,无需编程基础。例如描述”一个记录每日步数的App”,模型会自动生成基础功能代码并提供迭代建议。
3. 长上下文与工程化适配
- 100万token上下文窗口:
支持处理超长文档或复杂项目代码库,显著优于同期竞品。 - 生产级输出质量:
生成的代码结构规范、JSON格式严格合规,可直接集成到开发流程中,减少人工修正成本。
Gemini 3 Flash表现与基准测试
1. 关键能力指标
- 多模态推理:
MMMU Pro测试中取得81.2%准确率,超越Gemini 2.5 Pro(78.5%)及同期GPT-5.2(79.1%),在图像-文本跨模态理解任务中表现突出。 - 代码能力:
SWE-Bench Verified得分78%,超过Gemini 3 Pro的76.2%,证明其在轻量模型中仍具备强工程实用性。 - 科学推理:
GPQA Diamond(博士级科学知识测试)准确率达90.4%,接近人类专家水平。
2. 与竞品模型的对比
- 速度优势:
在实时交互任务中,响应速度约为Claude 3 Sonnet的2.1倍、GPT-4 Turbo的1.8倍。 - 成本效率:
完成相同任务的token消耗量比Gemini 2.5 Pro低30%,而输出质量差距小于5%,适合大规模部署。
Gemini 3 Flash应用场景
1. 开发效率提升
- 实时代码辅助:
开发者输入自然语言描述,模型1秒内输出完整代码,且能精准识别逻辑漏洞。 - 跨文件项目解析:
可一次性解析包含5个类文件的Python项目,快速定位类调用关系并提供优化建议。
2. 内容创作与交互设计
- 多方案快速生成:
输入设计需求后,一次性输出4种高质量SVG矢量图方案,供设计师筛选优化,避免传统单次生成的随机性。 - 交互式原型构建:
通过自然语言描述生成可实时调整参数的Web应用,从需求到可交互原型仅需几分钟。
3. 搜索与信息处理
- AI模式深度整合:
在谷歌搜索中直接调用模型解析复杂查询,例如上传会议录音自动生成带时间戳的摘要,并提取关键行动项。 - 实时数据增强:
结合网络搜索提供动态信息,如查询”最新AI芯片进展”时,自动附加权威来源链接与对比表格。
Gemini 3 Flash定位与后续演进
1. 在Gemini体系中的角色
- 主力级轻量模型:
谷歌明确将其定位为“高频任务的主力机型”,而非仅用于简单问答的边缘模型。Gemini高级总监图尔西·多希指出,其性价比优势使企业能将AI大规模嵌入批量处理流程。 - 与Pro版本的分工:
Flash负责快速响应、日常任务,Pro版本专注深度推理与复杂规划,形成互补生态。
2. 技术演进方向
- 后续版本升级:
2026年5月发布的Gemini 3.5 Flash在速度、智能体任务及成本控制上进一步优化,但3 Flash作为基础架构仍被广泛沿用。 - 硬件协同优化:
专为谷歌自研TPU芯片设计,推理效率较依赖英伟达GPU的竞品提升40%,为后续TPU 8代的规模化部署奠定基础。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...