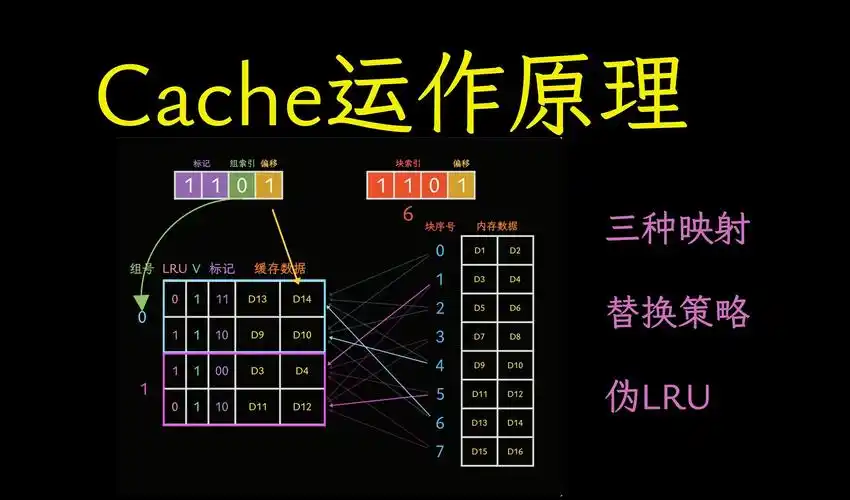
Qwen-VLA是阿里通义团队最新发布的通用机器人基础模型。
简单来说,如果之前的视觉模型是让AI拥有一双“眼睛”去理解世界,那么Qwen-VLA就是给这双眼睛配上了“灵活的手脚”,让AI不仅能看、能想,还能直接在物理世界中动手操作。

Qwen-VLA 是什么?
Qwen-VLA的全称是“视觉-语言-动作”(Vision-Language-Action)模型。它首次将机器人的操纵、导航、轨迹预测等复杂的异质任务,统一到了同一个大模型框架下。它打破了以往“一个机器人、一个任务就需要单独训练一个专用模型”的碎片化瓶颈,让机器人拥有了一个能跨场景、跨任务、跨形态的通用“大脑”。
Qwen-VLA核心优势
- 一个“大脑”适配多种机器人:以往不同形态的机器人往往需要单独训练。Qwen-VLA只需要你用文本描述一下当前机器人的身体特性和控制规则(即“身体感知提示”),同一个模型就能快速适配并指挥多种不同的硬件平台,无需重新训练。
- 极强的环境适应能力(泛化性强):即使真实场景的布局、光线、物体摆放位置发生变化,或者机器人本身被替换,Qwen-VLA 依然能保持稳定且优秀的操作成功率。在真实世界的机械臂实验中,面对这些陌生场景,它的平均成功率依然高达 76.9%。
- 动作自然流畅:得益于底层的技术创新,它生成的机器人动作不再是僵硬、顿挫的,而是像人类一样平滑、精准且连续。
Qwen-VLA技术原理
Qwen-VLA建立在通义千问强大的视觉语言大模型基础之上,其核心技术突破在于引入了基于扩散 Transformer(DiT)的动作解码器。
你可以这样理解它的工作流程:大模型作为“大脑”,负责理解视觉信息和语言指令,进行高层的思考和规划;而新增的 DiT 动作解码器则负责将这种规划“画”出来,生成平滑、连续的动作轨迹,最终转化为机器人可以执行的精准控制信号。
Qwen-VLA核心功能
- 统一的动作与轨迹预测:将原本割裂的操纵、导航、轨迹预测等任务,统一建模为同一个“动作预测”问题。
- 跨域能力迁移:让模型在视觉定位、空间推理等方面的能力,可以在不同的任务和不同的机器人之间自由迁移,学会了“拿杯子”的逻辑,也能举一反三应用到“拿苹果”上。
- 多源混合预训练:整合了机器人实际操作数据、人类第一视角演示、仿真合成数据等多种来源的数据进行预训练,兼顾了不同场景的能力学习。
Qwen-VLA适用场景
Qwen-VLA 为AI走进物理世界提供了强大的基础,主要适用于以下场景:
- 家庭服务机器人:指挥机器人完成收拾屋子、做饭、叠衣服等复杂的长链条家务。
- 工业与制造业:在流水线上进行精密的零件装配、物料搬运和自动化质检。
- 自动驾驶与物流:实现更精准的车辆轨迹预测、路径规划以及无人配送车的末端操作。
- 具身智能研发:为各类人形机器人、四足机器人提供统一的底层智能控制方案,大幅降低研发和训练成本。
Qwen-VLA的项目地址
项目官网:https://qwen.ai/blog?id=qwenvla
GitHub仓库:https://github.com/QwenLM/Qwen-VLA
arXiv技术论文:https://arxiv.org/pdf/2605.30280
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...