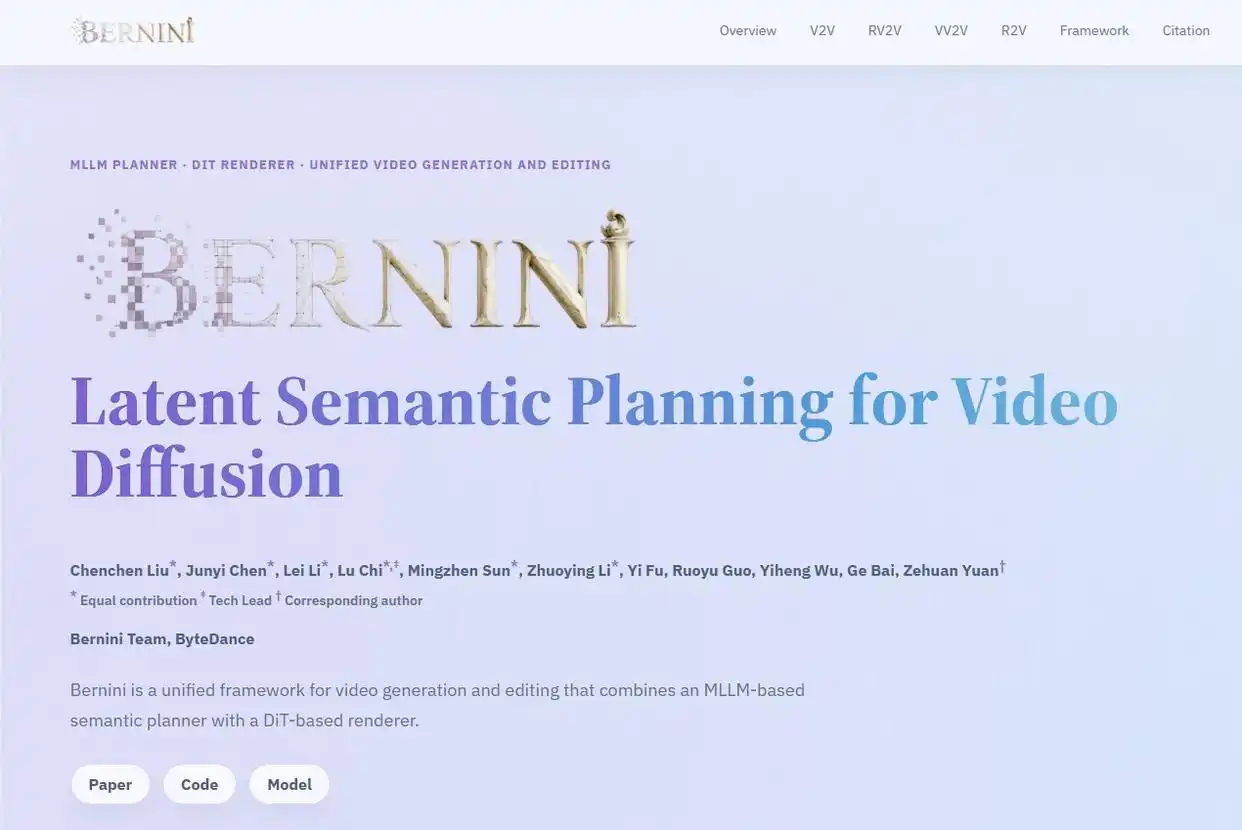
Bernini是字节跳动于2026年6月正式开源的统一视频生成与编辑框架,首创“语义规划+视觉渲染”的两阶段解耦架构,通过让AI先理解指令逻辑再生成画面,显著提升视频编辑的可控性与稳定性,解决传统模型因指令理解偏差导致的主体变形、背景漂移等核心痛点。
将AI视频创作从“试错式生成”推进到“精准可控编辑”阶段,直接服务于广告创意、影视预演等专业场景。
Bernini核心特点
1. 任务统一性
- 单一框架覆盖全流程:支持文本生成视频、图像生成视频、视频编辑、多参考引导植入等任务,无需切换不同模型。
- 多模态输入兼容:可同时处理文本指令、源视频、参考图片/视频,实现跨模态精准对齐。
2. 编辑精准度
- 语义级控制能力:支持对镜头视角、焦点、主体动作、环境材质的独立编辑,例如仅修改视频中的天气而保留人物动作。
- 边界与透视稳定:编辑后主体边缘无断裂、场景透视逻辑连贯,避免传统模型“一改全崩”的问题。
3. 轻量化与效率
- 推理速度优化:在A100 GPU上生成16秒视频仅需12秒,较同类模型提速约30%。
- 低资源适配:提供Bernini-R(第二阶段模型)简化版,可在消费级显卡运行基础任务。
Bernini核心优势
1. 可控性突破
- 减少“玄学”依赖:传统AI视频需反复调整提示词,而Bernini通过语义规划层预先验证指令可行性,编辑成功率提升50%以上。
- 细节保留能力:修改局部内容时,自动保留非编辑区域的原始细节(如背景、未改动角色),避免信息丢失。
2. 多参考一致性
- 跨元素精准融合:可将多张无关参考图(如不同角度的商品图)组合到同一视频角色中,材质、光影自然统一。
- 动态时序对齐:参考图植入后能跟随镜头移动保持透视稳定,适用于屏幕内容替换等场景。
3. 开源生态优势
- 完整技术栈开放:推理代码、模型权重及训练方案全部开源,支持社区二次开发。
- 工业级兼容性:已适配PyTorch 2.4+、CUDA 12.4+,提供Diffusers集成方案,降低企业接入门槛。
Bernini技术原理
1. 两阶段解耦架构
- 语义规划层(MLLM-based Planner):
多模态大模型在ViT嵌入空间解析输入,生成不限定像素的“语义草图”,明确规划内容结构、编辑区域及保留要素,避免直接生成像素导致的语义偏差。 - 视觉渲染层(DiT-based Renderer):
基于Diffusion Transformer将语义草图转化为视频,编辑任务中注入源视频VAE特征,确保非编辑区域细节完整。
2. 关键技术创新
- SA-3D RoPE位置编码:
为不同输入片段(源视频、参考图、目标输出)添加专属时空标记,解决多参考输入时的坐标混淆问题。 - Chain-of-Thought推理:
Planner在潜在空间执行分步逻辑推导(如“先识别主体→再调整动作”),提升复杂指令的解析准确率。 - 三阶段训练流程:
Planner预训练→Renderer预训练→轻度联合微调,保留预训练优势的同时避免过拟合。
Bernini应用场景
1. 广告与电商
- 动态产品展示:上传商品多角度参考图,自动生成360°旋转视频,支持一键替换背景/材质。
- 精准广告植入:将海报或商品无缝嵌入视频中的屏幕、招牌区域,随镜头移动保持透视一致。
2. 影视与游戏
- 分镜预演优化:导演输入草图+文本指令,快速生成镜头运动、角色动作的动态预览,缩短前期制作周期。
- 角色一致性维护:通过参考图修复续集电影中演员外貌变化问题,确保跨作品形象统一。
3. 企业服务
- 会议内容可视化:将录音转文字的结果自动生成带动态图表的解说视频,支持修改数据后实时更新画面。
- 本地化内容生产:输入外语视频+本地参考图,一键替换场景中的文字、标识等元素,适配不同地区版本。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...