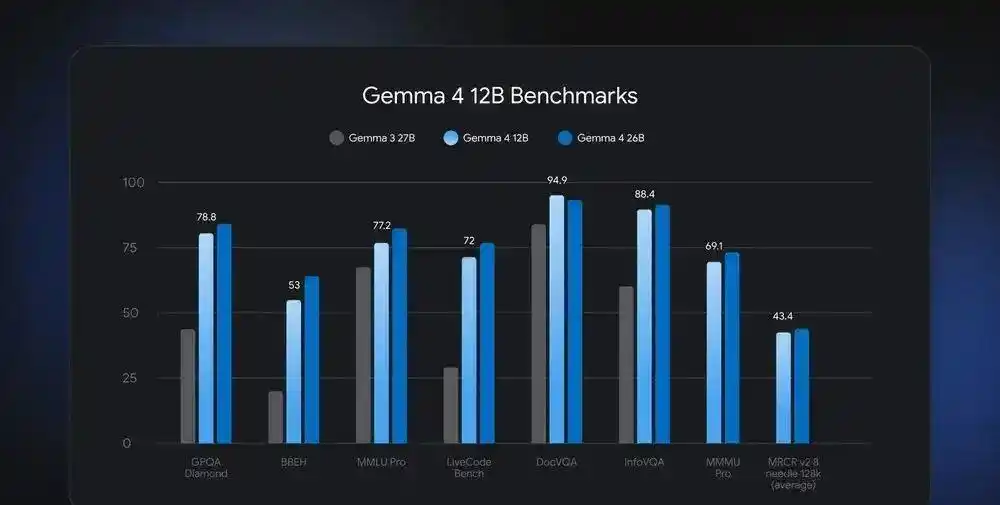
Gemma 4 12B是谷歌DeepMind于2026年6月4日发布的120亿参数统一多模态模型,最大突破在于通过无编码器架构实现仅需16GB内存的消费级笔记本即可本地运行完整多模态AI能力(支持文本、图像、音频输入及复杂推理)。其性能达到同系列260亿参数MoE模型的92%水平,但显存占用减少约50%,并首次在中等规模模型中集成原生音频处理能力,标志着端侧多模态智能体技术的关键落地。

Gemma 4 12B核心特点
1. 无编码器统一架构
- 抛弃传统多模态编码器:视觉与音频信号直接注入语言模型主干,无需独立视觉/音频编码器预处理,彻底消除“先编码再融合”的延迟与内存开销。
- 轻量级嵌入模块替代视觉处理:仅含单次矩阵乘法、位置嵌入和归一化操作,大幅简化视觉信息处理流程。
- 音频信号端到端直连:原始音频经线性投影直接映射至文本Token维度空间,无需专用音频编码器。
2. 端侧友好设计
- 16GB内存硬性门槛:主流消费级笔记本(如RTX 4060/4070游戏本或M系列16GB Mac)即可流畅运行,无需专业级硬件。
- 256K超长上下文支持:可一次性处理超长文档、完整代码库或数小时会议录音,远超多数端侧模型限制。
- 多Token预测(MTP)草稿器:默认集成MTP加速技术,利用空闲计算周期预测后续Token,推理速度提升数倍。
Gemma 4 12B核心优势
1. 性能与成本平衡
- 92%旗舰级性能:在GPQA Diamond、MMLU Pro等基准测试中,综合能力接近26B MoE模型,但显存占用不足后者一半。
- 本地化部署成本锐减:相比依赖云端API的方案,彻底规避数据隐私风险与Token计费成本,尤其适合敏感场景。
- 4-bit量化后8GB内存可运行:通过量化技术进一步降低门槛,覆盖更多入门级设备。
2. 开发生态友好性
- Apache 2.0完全开源:允许自由商用、修改与分发,无附加条款限制,显著降低企业合规风险。
- 全栈工具链支持:兼容LM Studio、Ollama、llama.cpp、MLX等主流本地推理框架,微调支持Unsloth高效LoRA适配。
- 多模态联合微调便捷性:因视觉/音频/文本共享权重,单次前向传递即可同步更新所有模态能力。
3. 智能体工作流原生支持
- 内置“思考”模式:生成答案前自动规划推理步骤,显著提升复杂任务(如数学证明、代码调试)的可靠性。
- 端到端多模态智能体:可直接调用工具链完成跨模态任务闭环(如“分析图表数据并生成语音报告”)。
Gemma 4 12B技术原理
1. 架构创新核心
- 统一嵌入空间设计:将文本、图像块、音频片段全部映射至同一语义向量空间,使语言模型主干能自主完成跨模态对齐。
- 动态计算资源分配:根据输入模态复杂度自适应调整计算路径,避免传统编码器的固定开销。
2. 高效推理机制
- MTP草稿器工作流:
- 草稿模型批量预测多个Token作为候选;
- 主模型并行验证候选Token,接受一致部分并修正分歧点;
- 质量零损失前提下提升吞吐量。
- KV缓存共享优化:草稿模型复用主模型的注意力缓存,避免重复计算,进一步压缩延迟。
3. 训练策略关键点
- 多模态联合监督微调:在指令微调阶段同步优化文本、视觉、音频任务,避免模态割裂。
- 强化学习质量对齐:通过多模态奖励模型优化生成结果的跨模态一致性与逻辑连贯性。
Gemma 4 12B应用场景
1. 端侧智能体应用
- 离线多模态助手:在无网络环境下实现文档解析(扫描PDF提取图表)、会议录音转写与摘要生成。
- 隐私敏感场景:医疗、金融等领域的本地化数据处理,避免敏感信息上传云端。
2. 开发者工具集成
- AI增强型IDE插件:在VS Code等环境中实时分析代码库上下文,结合图像/语音指令生成修复方案。
- 轻量级智能体开发:基于Google AI Edge Gallery快速构建端侧Agent,支持工具调用与多步规划。
3. 消费级设备赋能
- 笔记本本地AI工作站:普通用户可直接运行多模态任务(如用手机拍摄商品图生成描述文案)。
- 教育场景即时交互:学生通过语音提问+图像输入获取解题思路,全程离线保障响应速度。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...