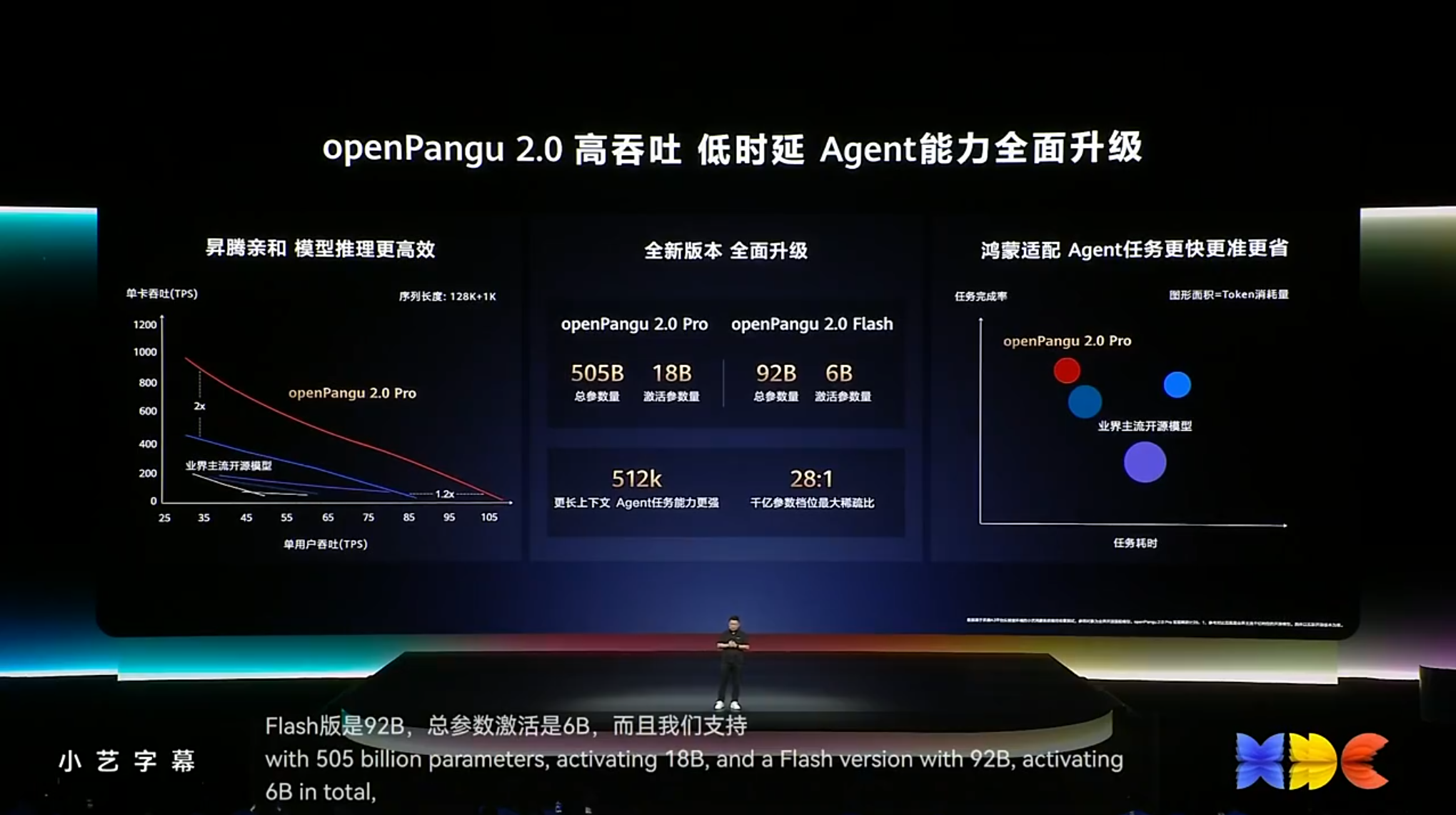

openPangu 2.0核心定义
1. 基本属性
- 开源性质:华为首次以“open”前缀命名,计划从2026年6月30日起分批开源7大核心组件(含预训练代码、后训练代码及训推算子),推动国产AI全栈生态共建。
- 双版本设计:
- Pro版:总参数量505B,激活参数量18B,面向复杂推理与企业级场景。
- Flash版:总参数量92B,激活参数量6B,专攻高并发、低时延的端侧部署。
2. 战略定位
- 拒绝参数竞赛:华为明确将技术重心从参数规模转向时延优化与吞吐率提升,以降低产业落地成本。
- 全栈协同载体:作为华为“芯片-框架-模型-终端”闭环的关键一环,深度绑定昇腾算力与鸿蒙OS,避免通用模型的碎片化问题。
openPangu 2.0核心特点与优势
1. 性能突破
- 吞吐率翻倍:单卡推理吞吐率达主流开源模型的2倍,512K长序列训练效率提升50%。
- 超低时延响应:Flash版仅需6B激活参数即可运行,适配智能客服、实时质检等“分秒必争”场景。
- 512K超长上下文:支持数十万字级文档处理,远超行业平均128K水平,适用于合同分析、长代码库理解等任务。
2. 产业适配性
- 垂直场景深度优化:针对制造、能源、金融等行业的任务完成率超90%,显著高于通用模型。
- 鸿蒙智能体(Agent)原生支持:在鸿蒙生态中执行任务时速度更快、精准度更高、资源消耗降低30%。
- 稀疏配比极致压缩:Pro版总参数505B但激活参数仅18B(稀疏比28:1),大幅降低运行负载与算力成本。
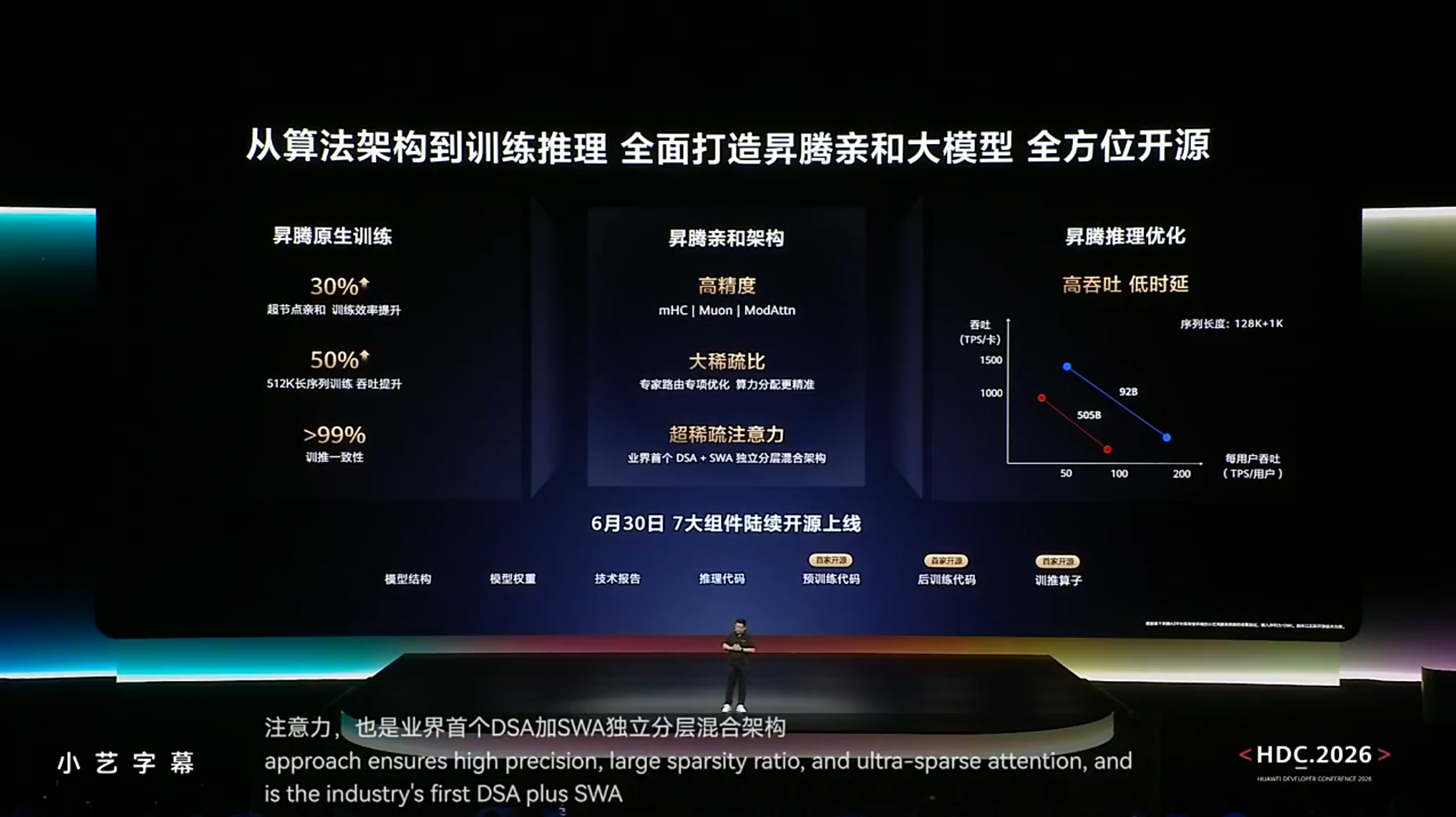
openPangu 2.0技术原理
1. 架构创新
- DSA+SWA独立分层混合架构:业界首个实现训练-推理一致性优化,减少硬件适配成本。
- 超稀疏注意力机制:通过>99%稀疏比的专家路由算法,仅激活必要参数模块,内存占用减少20%。
- 昇腾原生设计:采用mHC | Muon | ModAttn高精度架构,深度适配昇腾芯片指令集,避免通用模型的算力浪费。
2. 训练优化
- 动态负载均衡:专家路由专项优化算力分配,长序列训练吞吐提升50%。
- 超节点亲和训练:在昇腾集群上实现30%效率提升,支持512K上下文稳定训练。
- 训推一致性保障:训练与推理阶段采用统一算子库,避免部署时的性能衰减。
openPangu 2.0核心功能
1. 基础能力
- 超长文本理解:可解析512K tokens(约70万中文字符)的合同、代码库或科研论文。
- 高并发推理:Flash版支持每用户吞吐200 TPS(每秒事务处理量),满足实时业务需求。
- 多语言工业级支持:覆盖119种语言及方言,针对中文场景优化逻辑推理与行业术语理解。
2. 智能体(Agent)支持
- 跨应用任务闭环:直接调用鸿蒙生态内2000+智能体,完成复杂流程(如自动报销审批)。
- 资源高效调度:根据任务复杂度动态分配算力,简单查询仅需毫秒级响应,复杂分析自动切换深度模式。
openPangu 2.0应用场景
1. 高价值行业落地
- 智能制造:
- 实时质检系统响应速度提升200%,单条产线故障识别延迟压缩至50毫秒内。
- 钢铁冶炼工艺参数优化,能耗降低8%-12%。
- 能源管理:
- 矿山安全监测实现99.5%风险识别准确率,事故预警提前量达30分钟以上。
- 电网负荷预测误差率低于1.5%,支撑动态调度决策。
2. 国产化关键领域
- 气象预测:
- 全球10天精准预报速度比传统数值方法快10000倍,已被中央气象台纳入业务系统。
- 极端降水定位精度达5公里级,助力防灾“黄金时间”延长。
- 金融风控:
- 手写单据识别准确率从83.9%提升至91.0%,人工复核量减少70%。
- 实时反诈系统可在200毫秒内完成交易风险评估。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...