
MMAE是腾讯混元联合上海交通大学、南洋理工大学、天津大学、北京大学、复旦大学等机构推出的全球首个面向自然语言指令驱动音频编辑任务的大规模多任务评测基准。系统性评估AI模型对已有音频进行精准定向编辑的能力,而非从零生成音频。实测表明,当前主流模型在关键指标”精确匹配率”(EMR)上的平均表现不足5%,揭示AI音频编辑技术仍处于早期阶段,距离实用化有显著差距。
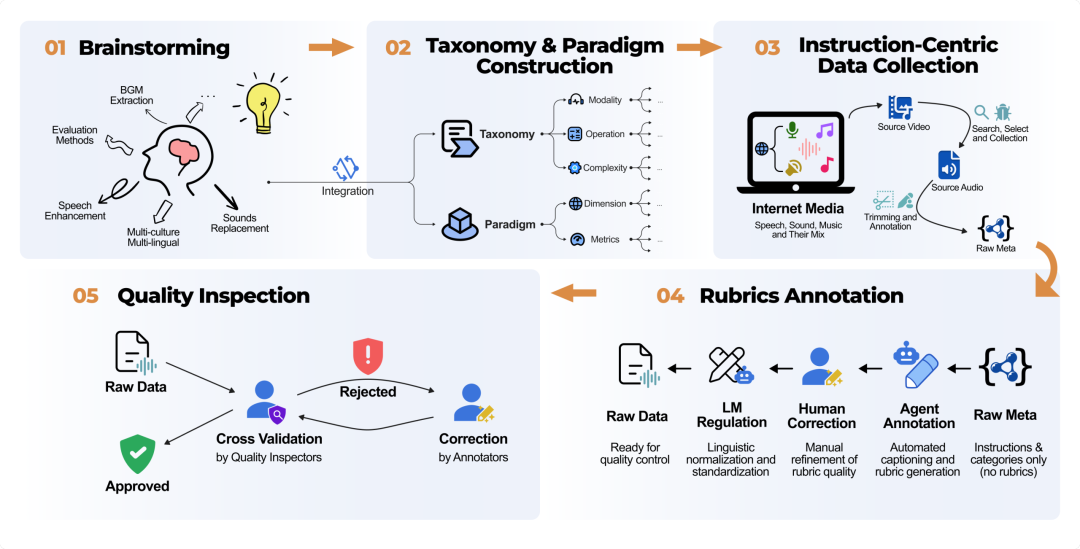
MMAE核心定义
1. 解决的核心问题
- 传统音频AI研究聚焦于从文本生成全新音频,但实际生产场景更需要基于原始音频的精准定向编辑能力。
- 此前领域内缺乏统一评测体系,现有测试多局限于单一声音类型或简单操作(如仅支持”添加/删除”),无法反映真实复杂场景需求。
2. 关键突破方向
- “编辑而非重做”范式:要求模型仅修改指令指定的部分,同时严格保留原始音频的非目标区域,对声学建模精度、语义对齐能力提出更高要求。
- 真实场景导向:所有测试样本均来自真实录音场景(非人工合成数据),覆盖日常对话、环境音效、乐器演奏等复杂声学环境。
MMAE核心特点
1. 多维立体化评测框架
- 7种音频模态组合:涵盖纯环境音效、纯音乐、纯语音及三者交叉混合形态,适配综艺录音、影视片段等真实多声源场景。
- 6级任务难度梯度:从基础单步替换(如”添加海鸥叫声”)延伸至多跳推理任务(如”调低水最多玻璃杯的敲击音调”,需理解物理规律),全面探测模型能力边界。
- 8类精细化操作类型:包含局部操作(添加/删除/替换/提取/局部改变)与全局操作(背景更换/前景更换/全局改变),覆盖90%以上实际编辑需求。
2. 严格量化评估机制
- 2000个高保真测试样本:平均时长14.46秒,指令平均14个词,确保测试贴近真实工作流。
- 17741项细粒度评分项:采用拆解式rubric评分,将每道题分解为独立检查点(如”背景是否替换为吉他音色?””男声音调是否降低?”),避免主观模糊评价。
- 核心指标EMR(精确匹配率):要求所有检查点100%达标才计为成功,显著高于传统宽松评测标准。
MMAE技术评测原理
1. 能力评估逻辑
- 指令-音频双向对齐:模型需同时理解文本指令的语义约束和原始音频的声学细节,例如指令”将背景音乐换成吉他演奏同款旋律”时:
- 旋律一致性:新背景需与原旋律节奏、调性匹配。
- 局部精准性:仅修改背景层,人声内容与环境音效必须保持不变。
- 声学保真度:避免引入杂音或破坏原始空间感。
2. 关键挑战识别
- 模态失衡问题:现有模型过度依赖文本语义,常忽略视频画面中的隐含音频线索。
- 编辑粒度失控:易出现过度修改非目标区域、关键约束遗漏(如未保持旋律一致性)等问题。
- 音质退化:编辑后音频常出现背景噪音增加、动态范围压缩等失真,难以满足专业制作要求。
MMAE功能价值
1. 技术诊断工具
- 精准定位能力短板:通过细分维度得分(如”多跳推理任务EMR仅1.2%”),明确模型在复杂逻辑理解或声学细节控制上的缺陷。
- 推动技术范式转型:引导研究方向从”生成优先”转向”编辑为本“,强调对已有内容的可控干预能力。
2. 行业标准构建
- 统一评估标尺:为学术界提供可复现的基准,避免各团队使用私有数据集导致的结果不可比问题。
- 开源生态支撑:配套发布标准化测试流程与评分工具,降低新模型验证门槛。
MMAE应用场景
1. 高价值落地场景
- 影视后期制作:快速替换特定场景音效(如将雨声改为雪声),避免重新录制整段音频。
- 播客内容优化:精准消除背景杂音、调整嘉宾音量,无需手动剪辑多轨道工程文件。
- 无障碍服务升级:为听障用户提供语音语速/音调自定义调整,同时保留原始情感表达。
2. 当前技术边界
(1)高效适用条件
- 指令高度结构化:当编辑目标能被明确拆解为原子操作(如”仅修改第5-8秒的鼓点节奏”)时,成功率显著提升。
- 专业领域预训练:在垂直领域(如音乐制作)使用领域专属数据微调后,EMR可提升至15%-20%。
(2)关键局限性
- 复杂逻辑处理薄弱:涉及物理规律或多步骤推理的任务,EMR普遍低于2%。
- 长音频编辑不稳定:超过30秒的音频因上下文窗口限制,易出现局部修改与整体连贯性冲突。
- 商业化落地门槛高:专业级应用需EMR超过85%,当前技术距此目标仍有数量级差距。
MMAE在于将AI音频编辑从”能否生成”的初级阶段,推进至”能否精准控制”的实用化门槛。它揭示了一个关键事实:当前技术能较好完成”从无到有”的音频生成,但在”从有到优”的定向编辑上仍极其脆弱。短期内,该基准将加速专业工具链的开发;长期看,突破5%的EMR瓶颈需结合多模态联合建模与声学物理规律注入,才能支撑影视制作、实时内容生产等高要求场景。现阶段,适用于指令明确、编辑范围局限的轻量级任务,但复杂创作仍需人工主导。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...