
人工智能算法主要分为基础机器学习算法、深度学习架构、优化与辅助算法三大类,其核心差异在于数据处理方式、适用任务类型及复杂度。小编以下按类别系统梳理常见算法及其关键特征,重点突出实际应用场景与技术本质。
基础机器学习算法
1. 监督学习算法
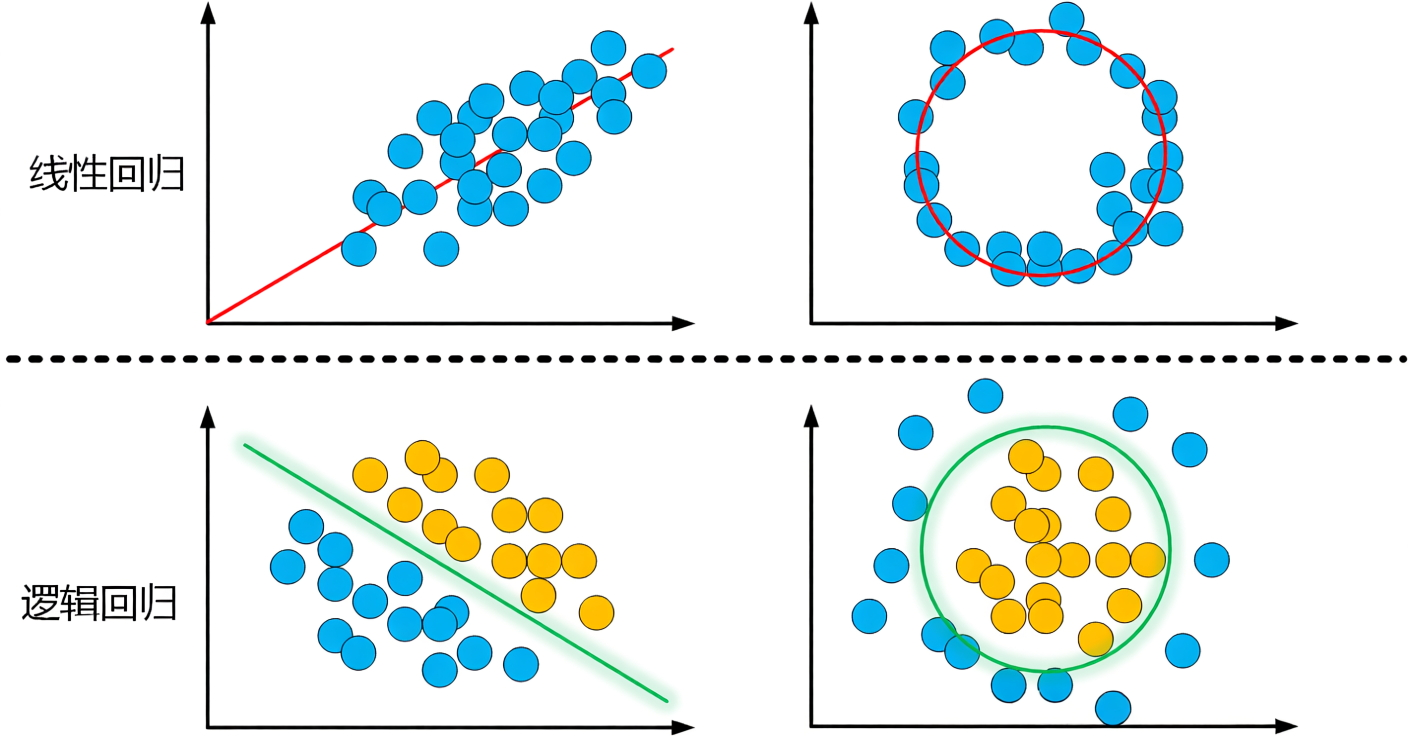
- 线性回归与逻辑回归:
- 线性回归通过拟合特征与连续目标变量的线性关系预测数值(如房价预测);逻辑回归则通过Sigmoid函数将线性组合映射为概率,适用于二分类任务(如垃圾邮件识别)。两者计算高效、可解释性强,但难以处理复杂非线性关系。
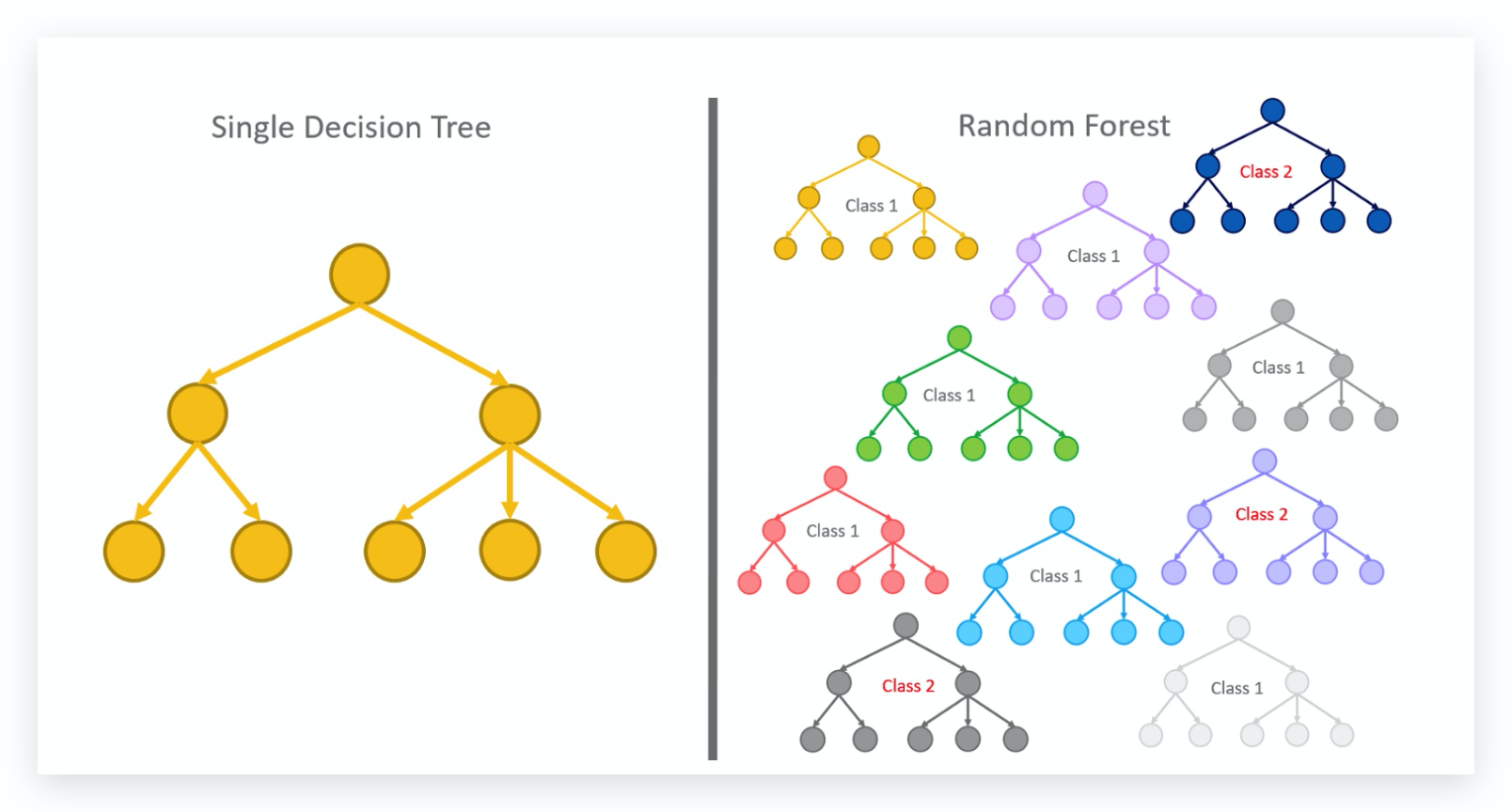
- 决策树与随机森林:
- 决策树基于特征划分构建树状规则,直观易理解但易过拟合;随机森林通过集成多棵决策树并引入特征/样本随机性,显著提升泛化能力,广泛用于信用评分、医疗诊断等需平衡准确性与鲁棒性的场景。
- 支持向量机(SVM):
- 通过最大化分类间隔寻找最优超平面,结合核函数可处理非线性问题,在小样本高维数据(如文本分类、早期图像识别)中表现优异,但对大规模数据计算成本高。
2. 无监督学习算法
- K均值聚类(K-Means):
- 通过迭代优化簇中心位置将数据划分为K个组,核心依赖欧氏距离度量相似性,适用于客户分群、图像压缩等任务,但需预先指定K值且对异常值敏感。
- 主成分分析(PCA):
- 通过线性变换提取数据方差最大的正交方向实现降维,保留关键信息同时减少计算复杂度,常用于数据可视化、噪声过滤及作为其他算法的预处理步骤。
3. 强化学习算法
- Q学习与深度Q网络(DQN):
- Q学习通过更新状态-动作价值表学习最优策略,DQN则用神经网络近似价值函数以应对高维状态空间,典型应用于游戏AI(如AlphaGo)、机器人控制等需序列决策的场景。
- 近端策略优化(PPO):
- 直接优化策略函数而非价值函数,通过限制单次更新幅度保证训练稳定性,是当前最主流的实用强化学习算法,广泛用于自动驾驶决策、工业控制等领域。
深度学习架构
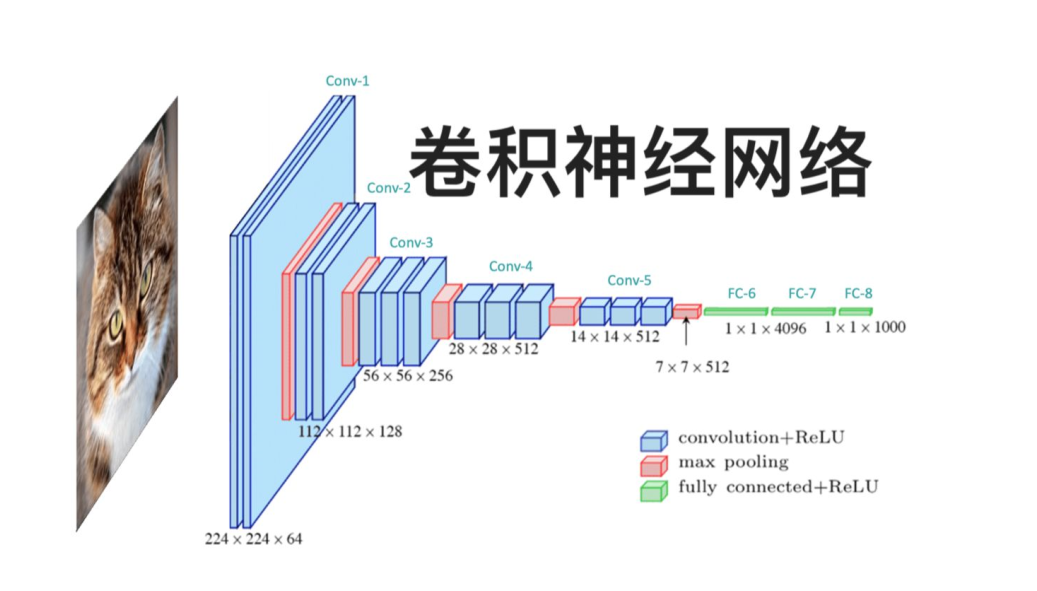
1. 卷积神经网络(CNN)
- 核心通过卷积层提取局部特征、池化层降低空间维度,参数共享机制大幅减少计算量。
- 典型应用:图像分类(ResNet)、目标检测(YOLO)、医学影像分析等,对网格状数据(如图像)具有天然优势。
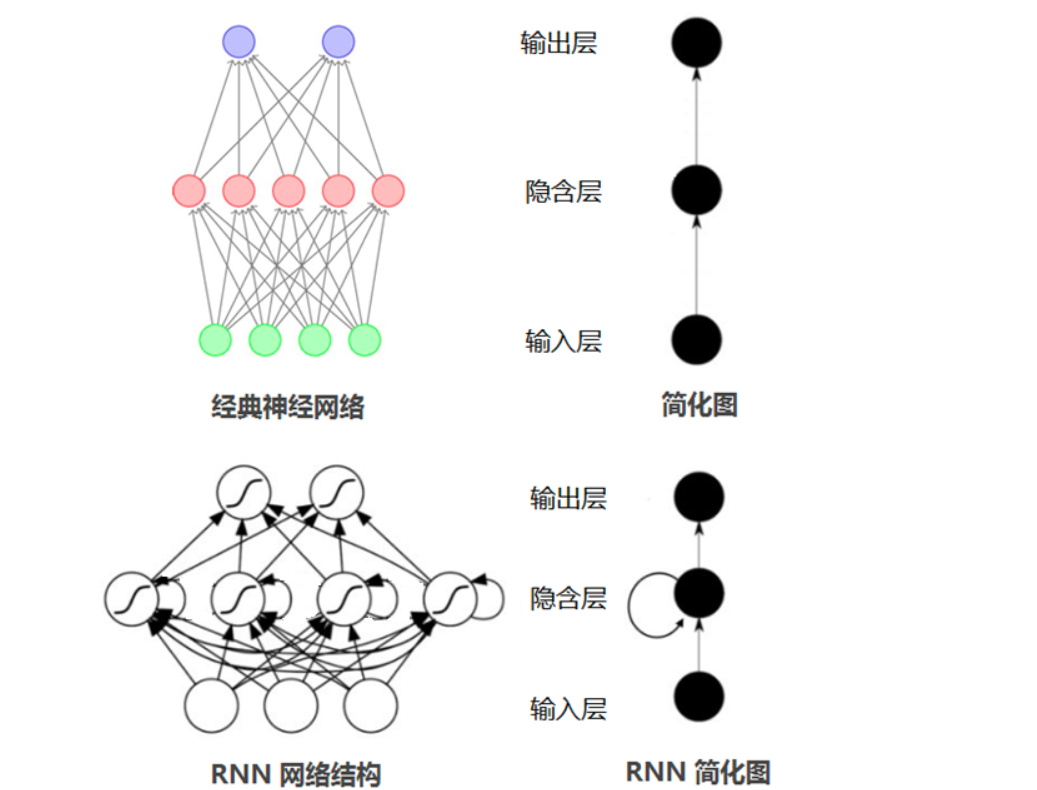
2. 循环神经网络(RNN)及其变体
- RNN通过隐藏状态传递序列历史信息,但易受梯度消失影响;LSTM和GRU通过门控机制缓解长程依赖问题。
- 典型应用:自然语言处理(机器翻译、文本生成)、时序预测(股票走势、天气预报),专精于序列数据建模。
4. 生成模型
优化与辅助算法
1. 集成学习方法
- Bagging(如随机森林):通过并行训练多个基模型并平均结果降低方差,提升稳定性。
- Boosting(如XGBoost、LightGBM):通过串行迭代聚焦难样本,逐步提升精度,在结构化数据竞赛中长期占据优势。
2. 概率与图模型
- 朴素贝叶斯:基于特征条件独立假设的贝叶斯定理,计算高效,适用于文本分类(如情感分析),但独立性假设在现实中常不成立。
- 隐马尔可夫模型(HMM):对隐含状态序列建模,曾广泛用于语音识别,现多被深度学习替代。
3. 进化与群体智能算法
- 遗传算法(GA):模拟生物进化,通过选择、交叉、变异操作优化解空间,适用于复杂优化问题(如路径规划)。
- 粒子群优化(PSO):基于群体协作的无梯度优化方法,收敛速度快,常用于神经网络超参数调优。
小编概况一下
- 任务匹配优先:
- 分类/回归任务优先考虑随机森林、XGBoost或神经网络;
- 图像/视频处理首选CNN,文本/时序数据首选Transformer或LSTM;
- 无监督探索可尝试K-Means或PCA。
- 数据与算力约束:
- 小规模数据集建议用传统机器学习算法(如SVM、决策树),避免深度学习的过拟合风险;
- 大规模数据且需高精度时,深度学习模型更具优势,但需充足算力支持。
- 可解释性需求:
- 金融、医疗等高风险领域需平衡准确性与可解释性,可选逻辑回归、决策树或可解释AI(XAI)技术;
- 生成类任务(如内容创作)可接受“黑箱”,优先选择生成模型。
算法选择的核心逻辑是:在明确任务目标、数据特性与资源限制的前提下,选择复杂度与问题匹配度最高的方案,而非盲目追求“最先进”模型。 实际应用中,特征工程的质量往往比算法本身对结果影响更大,需优先确保数据清洗与特征设计的合理性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...