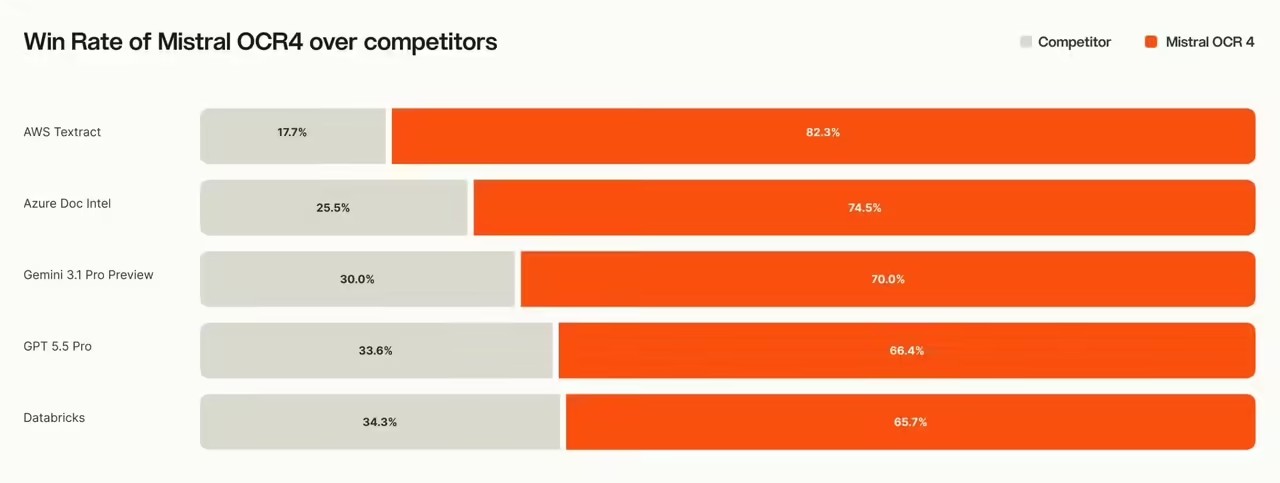
OCR 4是Mistral AI推出的最新文档内容识别模型,专为高精度、多语言文档处理设计。解决传统 OCR 在复杂文档结构、多语言混排及下游任务适配中的局限性,输出质量经人类评估优于 GPT-5.5 Pro、Gemini 3.1 Pro 等主流模型,在 OmniDocBench 基准测试中得分 93.07 分。
OCR 4核心特点
1. 超广语言覆盖能力
- 支持横跨 10 个语族的 170 种语言,包括低资源语言(如斯瓦希里语、藏语),且对多语言混排文档(如中英日混杂的合同)识别鲁棒性显著提升。
2. 小型化与任务聚焦
- 采用 轻量级架构设计,模型体积远小于通用大模型,但专精于文档识别任务,避免通用模型在文档结构解析中的冗余计算。
- 输出同时提供文本内容、文本区域边框坐标、区域分类标签(如标题/正文/表格)及置信度评分,直接支持下游结构化处理。
3. 人类偏好优化
- 训练过程中引入人类反馈强化学习(RLHF),使输出文本更符合人类阅读习惯(如标点修正、段落分隔逻辑),在人工评估中 显著优于竞品模型。
OCR 4技术原理
1. 端到端文档理解架构
- 统一编码-解码框架:
输入文档图像后,模型通过视觉编码器提取多尺度特征,直接生成结构化文本与布局信息,跳过传统 OCR 的“检测-识别-后处理”多阶段流程,减少误差累积。 - 区域感知注意力机制:
在解码阶段动态关联文本内容与空间位置,确保表格、分栏等复杂布局的区域归属准确性(如避免跨栏文本拼接错误)。
2. 关键技术创新
- 语义分块对齐:
将识别结果按语义单元(如句子、列表项)自动分块,天然适配 RAG(检索增强生成)系统的语义检索需求,无需额外后处理。 - 动态置信度校准:
基于局部图像质量(如模糊度、光照不均)实时调整置信度阈值,低质量区域输出更保守的置信评分,降低误识别风险。
OCR 4核心功能
1. 高精度文档内容提取
- 精准识别扫描件、PDF 图像页、手写笔记等非结构化文档,对模糊、倾斜、低分辨率文本的容错率优于传统 OCR。
- 保留原始排版逻辑:自动区分标题、正文、表格、页眉页脚,并输出结构化数据(如 JSON 格式)。
2. 下游任务直接支持
- RAG 语义分块:输出按语义划分的文本块,可直接用于知识库构建。
- 智能体结构化输入:为 AI Agent 提供带区域标签的文本流,支持精准定位关键信息(如合同中的金额字段)。
- 连接器结构化内容:生成标准化 API 可解析的数据,无缝对接 ERP、CRM 等企业系统。
3. 灵活部署选项
- API 调用:基础定价 每千页 4 美元,批处理任务享 50% 折扣。
- 本地化部署:支持私有化模型实例,满足金融、政务等敏感数据场景需求。
OCR 4适用人群
1. 企业级文档自动化场景
- 金融/法律机构:快速提取合同、票据中的关键字段(如金额、日期),避免人工录入错误。
- 政务部门:处理多语言户籍档案、历史文献数字化,支持低资源语言识别。
- 医疗行业:解析手写病历与扫描报告,保留医学术语准确性。
2. 开发者与技术团队
- RAG 系统构建者:直接获取语义分块结果,省去自研分块逻辑。
- AI Agent 开发者:利用区域分类标签实现精准信息定位(如“提取表格第三行数据”)。
- 低代码平台集成方:通过 API 快速嵌入文档处理能力,无需深度学习专业知识。
3. 局限性与规避建议
- 不适用于实时视频流识别:专注静态文档处理,动态场景需搭配专用模型。
- 复杂手写体精度有限:对潦草手写签名等场景,建议结合人工复核流程。
- 超大规模处理成本:单页成本高于开源方案(如 Tesseract),需权衡精度与预算。
最后想说:OCR 4 的核心突破在于 “小型模型+文档专项优化+人类偏好对齐” ,通过端到端架构消除传统 OCR 的流程断层,尤其适合需高精度结构化输出的企业级文档处理。对于开发者,其原生支持 RAG 分块与区域标签的能力可大幅降低下游开发成本;对于企业用户,170 种语言覆盖与人类级输出质量能显著提升文档自动化系统的可靠性。若仅需基础文字提取,开源方案(如 Tesseract)仍更具成本优势。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...