SeedMusic 1.0 Preview是字节跳动在即梦AI平台上线的音乐生成功能,让无音乐基础的用户通过自然语言描述即可生成旋律自然、情感贴合的原创歌曲,并支持从歌词调整到人声克隆的全流程编辑。该版本深度适配中文语境与本土文化表达,通过10秒人声克隆、音符级编辑等技术,将专业级音乐创作能力下沉至普通用户,标志着AI音乐工具从“技术演示”向“大众可用”的关键突破。
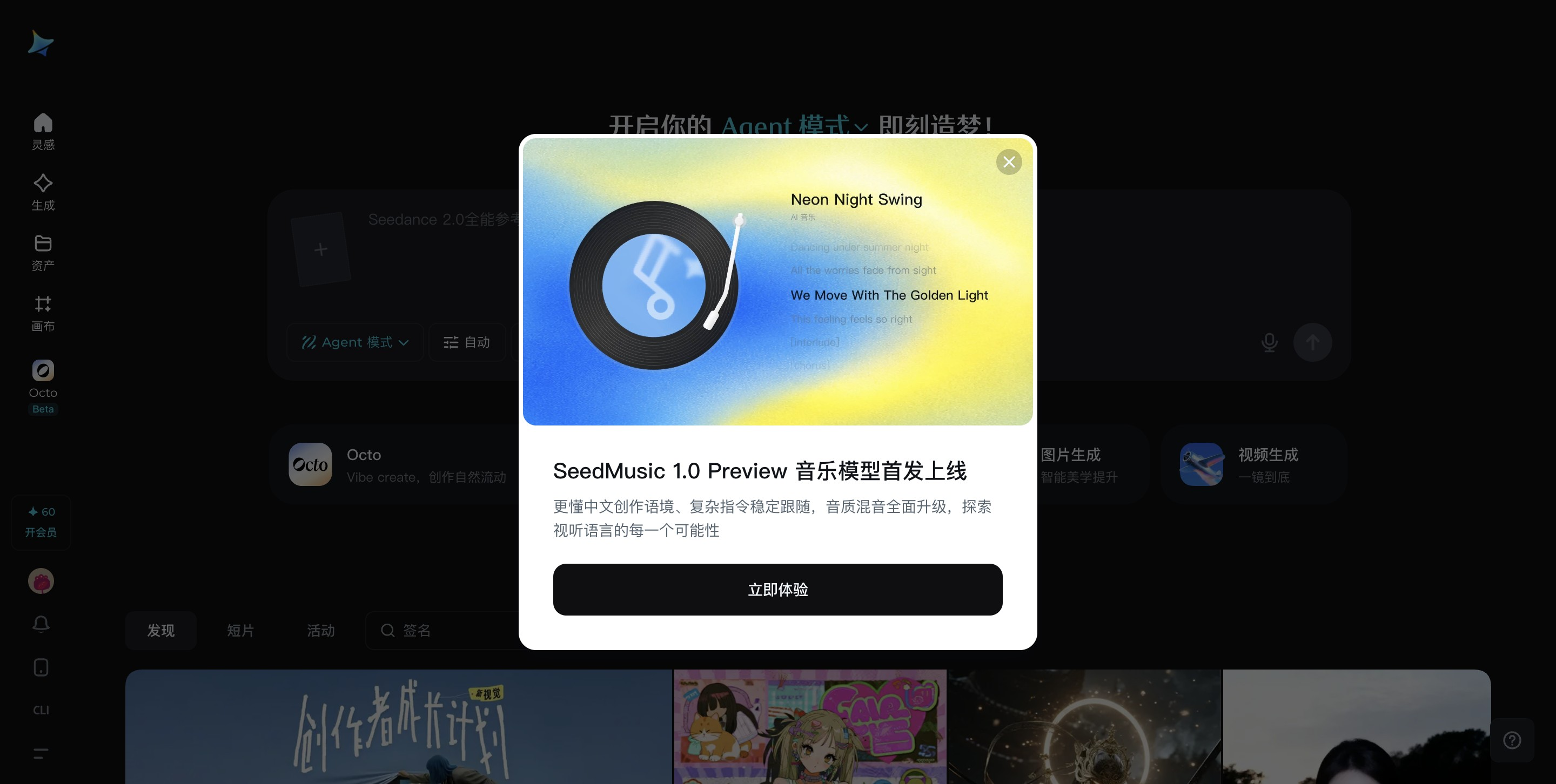
SeedMusic 1.0 Preview核心特点
1. 自然语言驱动的零门槛创作
- 中文语境深度优化:对古风诗词、方言(如粤语)、口语化表达的理解远超通用音乐模型,能精准生成符合中文韵律的旋律,避免“翻译腔”式生硬编曲。
- 多模态输入融合:支持文字描述(如“江南烟雨中的离别”)、语音片段甚至哼唱输入,3秒内实时生成可试听的完整歌曲,无需乐理知识或专业软件操作。
- 动态反馈机制:用户可随时调整指令(如“节奏再轻快些”“加入二胡”),系统即时响应并播放修改后的片段。
2. 技术架构突破
- 双模型协同框架:结合自回归语言模型(LM) 与扩散模型(Diffusion),前者确保歌词-旋律逻辑连贯,后者优化音色细节,避免机械感或失真。
- 流式解码技术:输入指令后3秒内开始播放生成内容,大幅降低等待感知,提升创作沉浸感。
- 安全验证流程:对生成内容实施多级水印与重复检查,防范版权与滥用风险。
SeedMusic 1.0 Preview核心优势
1. 创作自由度与易用性平衡
- 10秒人声克隆:仅需用户提供10秒清唱或语音片段,即可将普通人的声音转换为符合歌曲风格的演唱音色,无需专业录音设备。
- 音符级精细编辑:可直接修改单个音符的音高、时长、力度,实现专业级调整,而非仅能替换整体风格。
- 歌词-旋律解耦控制:支持修改歌词但保留原旋律结构(如将“一捧黄河水”改为“一捧长江水”),避免传统工具中歌词变动导致旋律断裂。
2. 普惠化设计
- 免费额度充足:通过每日签到、任务奖励提供每日10首以上的免费生成额度,显著降低体验门槛。
- 跨语言无缝适配:中文歌词可自动生成匹配的英文副歌段落,或直接基于粤语文本输出地道港乐风格编曲。
- 多终端一致性:网页端与移动端操作逻辑统一,手机端可直接录制语音输入灵感。
SeedMusic 1.0 Preview核心功能
1. 智能生成类
- 场景化作曲:根据用户描述的情绪或场景(如“毕业季的操场回忆”“深夜加班的孤独感”)自动生成结构完整、时长1-3分钟的原创歌曲。
- 风格仿写:输入参考歌曲名称或片段,生成相似风格但完全原创的旋律,规避版权风险。
- 纯器乐生成:支持仅生成背景音乐(BGM),适配短视频、播客等场景需求。
2. 编辑优化类
- 局部旋律重写:选定某小节后指定“更欢快”“更舒缓”,系统仅修改目标段落并保持前后过渡自然。
- 歌词动态修正:实时提示“此处可调整字数以匹配节拍”,辅助优化歌词与旋律的适配性。
- 人声-伴奏分离:上传现有歌曲可提取纯净人声或伴奏,用于二次创作。
SeedMusic 1.0 Preview应用场景
1. 个人情感表达
- 纪念性创作:为亲友生日、结婚纪念日等定制专属歌曲,将照片故事转化为歌词,无需依赖专业音乐人。
- 社交内容增强:为短视频、Vlog生成高度匹配画面情绪的原创BGM,避免版权纠纷,提升内容独特性。
- 情绪外化工具:将日记中的文字片段生成音乐,帮助用户具象化难以言表的情感。
2. 轻量级商业与教育场景
- 本地化营销:中小企业为促销活动定制方言版广告曲(如粤语港风、川渝方言),低成本实现地域化传播。
- 教育辅助:教师输入乐理概念(如“小调进行”),系统即时生成示例音频,直观讲解抽象音乐知识。
- 内容平台生态:抖音、小红书创作者一键生成差异化背景音乐,强化个人IP辨识度。
3. 专业创作辅助
- 灵感速记:音乐人用语音快速记录旋律灵感,系统自动补全和声与配器,3分钟内输出可商用Demo。
- 跨文化协作:基于中文歌词生成粤语风格编曲,或为英文歌词匹配本土化旋律逻辑。
即梦SeedMusic 1.0 Preview将音乐创作从“专业特权”转化为“大众表达工具”,其关键差异点在于:
- 中文场景深度适配,能精准捕捉古风意象、方言韵律等本土化表达;
- 编辑自由度与易用性的平衡,既保留专业级控制能力,又不牺牲创作流畅性;
- 免费策略推动规模化尝试,通过高频试错降低用户心理门槛。
需注意,当前Preview版本对复杂曲式(如交响乐)支持有限,更适合流行、民谣等中短篇幅创作,且人声克隆效果受原始语音质量影响较大。对于追求极致音质的专业制作,仍需结合传统工具进行后期处理。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...