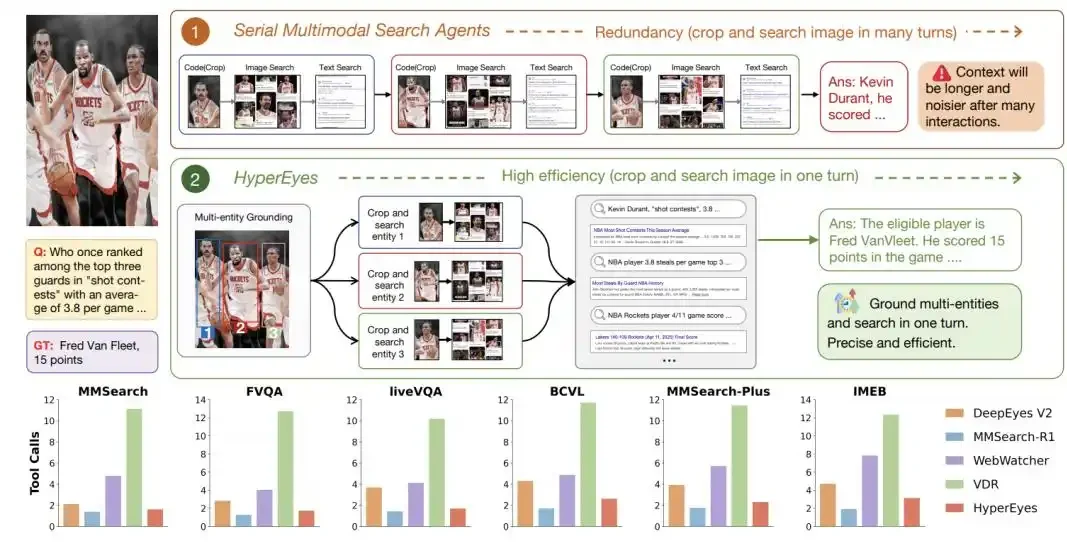
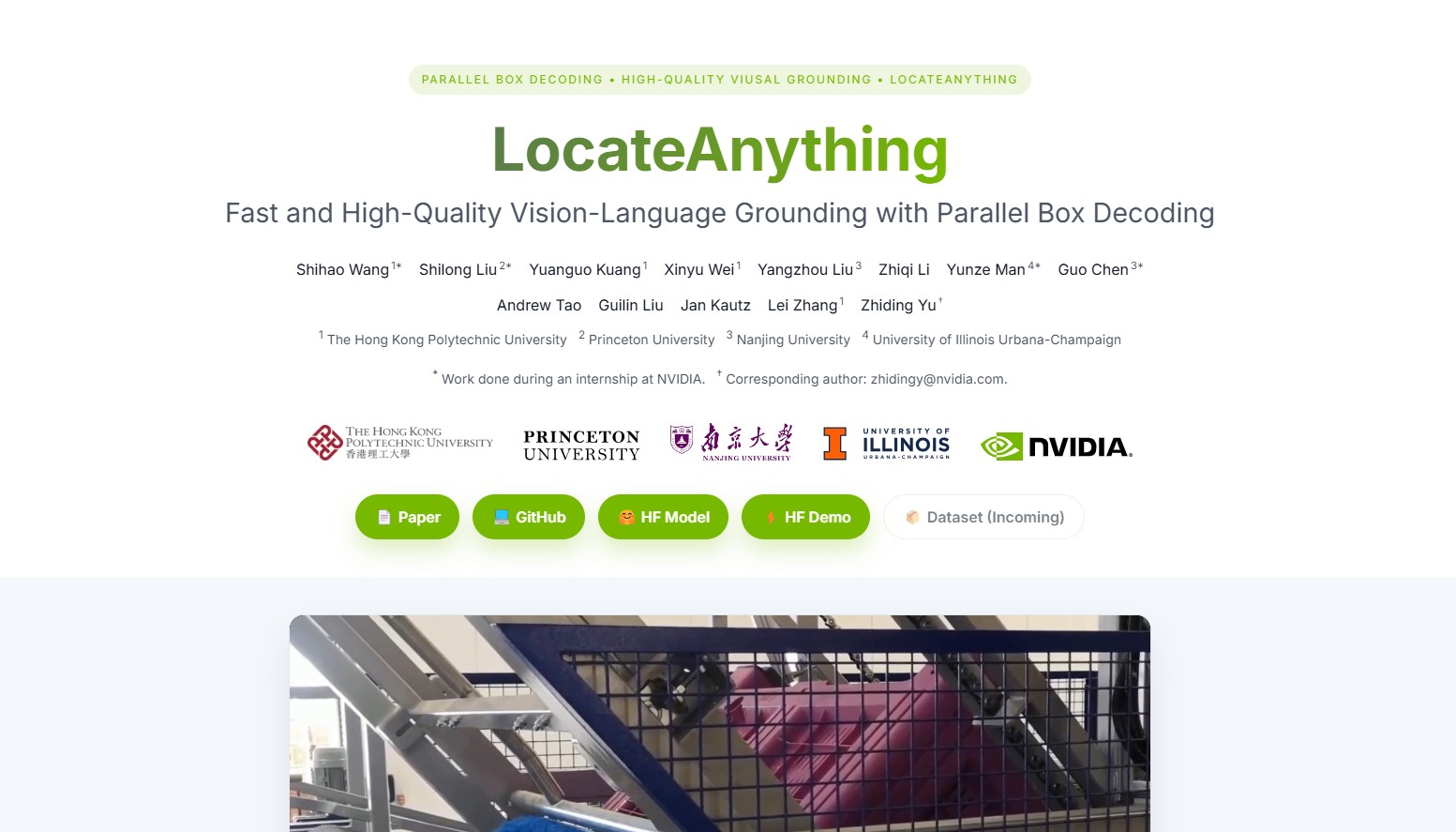
LocateAnything是英伟达联合香港理工大学、南京大学等机构推出的视觉语言定位模型,通过并行框解码技术实现单步预测边界框坐标,在保持高精度的同时将检测速度提升至传统模型的2.5倍以上。该模型专为实时交互场景设计,能在毫秒级内完成目标定位,显著解决机器人操作、GUI自动化等任务中传统模型响应延迟的瓶颈问题。
LocateAnything核心特点
1. 速度与精度的突破性平衡
- 单步预测机制:将边界框坐标(x1,y1,x2,y2)视为固定长度原子单元,仅需1次前向传播即可完成预测,避免传统模型逐个生成坐标token的串行延迟。
- 实时性能领先:在单张NVIDIA H100 GPU上,Hybrid模式达到12.7框/秒的处理速度,远超Qwen3-VL(1.1框/秒)和Rex-Omni(5.0框/秒)。
- 高精度保障:在LVIS数据集IoU=0.95标准下得分31.1,ScreenSpot-Pro平均F1值达60.3,DocLayNet和M6Doc分别获得76.8与70.1的高分。
2. 动态适应多场景需求
- 三种运行模式灵活切换:
- Fast Mode:面向端侧设备优化吞吐量,牺牲少量精度换取更高帧率,适用于机器人实时操作。
- Slow Mode:侧重离线标注与高精度评估,确保复杂任务的绝对准确性。
- Hybrid Mode(默认):常规场景快速输出,遇到格式异常或空间歧义时自动切换至自回归解码,实现效率与精度的动态平衡。
- 泛化能力突出:覆盖通用检测、GUI元素定位、指代表达理解等六大核心领域,无需针对单一任务重新训练。
3. 大规模多模态数据支撑
- LocateAnything-Data数据集包含1200万独立图像、1.38亿语言查询及7.85亿边界框,涵盖从日常物品到复杂文档布局的多样化场景。
- 中文支持优化:基于千问(Qwen)系列模型的语义理解能力,对中文查询的定位准确率显著提升。
LocateAnything技术原理
1. 并行框解码(Parallel Box Decoding, PBD)
- 原子单元设计:将边界框或点坐标编码为固定长度的几何单元,直接通过单次神经网络前向传播输出完整坐标,消除传统自回归解码的序列依赖。
- 几何一致性保障:避免逐个预测坐标导致的框体扭曲问题,确保检测框内部结构的逻辑合理性。
2. 动态模式切换机制
- 异常检测逻辑:系统实时监测输出格式的完整性与空间逻辑一致性,当检测到坐标格式错误或目标重叠冲突时自动触发Slow Mode。
- 资源分配优化:Fast Mode通过简化非关键区域计算降低延迟,Hybrid Mode仅在必要时调用高精度模块,实现算力的精准分配。
3. 多任务统一框架
- 共享视觉编码器:采用统一的视觉-语言对齐架构处理不同任务,避免为每类任务单独设计模型。
- 任务类型条件控制:通过输入指令中的任务标识符(如“OCR定位”“GUI元素”)动态激活对应解码头,保持模型轻量化。
LocateAnything核心功能
1. 跨领域目标定位
- 开放词汇检测:支持任意自然语言描述的目标搜索(如“左侧第三个红色按钮”),无需预定义类别。
- 细粒度场景解析:
- GUI元素定位:精准识别屏幕截图中的按钮、输入框等界面组件。
- OCR文字定位:直接框选出图像中的文本区域,跳过传统OCR的预处理环节。
- 文档结构理解:解析表格、标题、段落等版面元素,适配PDF/扫描件等复杂格式。
2. 实时交互支持
- 毫秒级响应:从接收图像到输出检测框的端到端延迟低于100毫秒,满足机器人抓取、自动驾驶避障等实时需求。
- 动态目标追踪:结合视频流输入,持续跟踪移动物体的坐标变化,适用于监控场景分析。
3. 多语言与低资源适配
- 中英文无缝切换:对中文查询的定位准确率与英文持平,无需额外翻译层。
- 端侧部署优化:Fast Mode可在消费级GPU(如RTX 4060)上运行,推理速度仍达3-5框/秒。
LocateAnything项目地址
- 项目官网:https://research.nvidia.com/labs/lpr/locate-anything/
- GitHub仓库:https://github.com/NVlabs/Eagle/tree/main/Embodied
- HuggingFace模型库:https://huggingface.co/nvidia/LocateAnything-3B
- 技术论文:https://research.nvidia.com/labs/lpr/locate-anything/LocateAnything.pdf
LocateAnything典型应用场景
1. 机器人与自动化系统
- 具身智能操作:服务机器人通过实时定位环境中的物体(如“拿起桌上的水杯”),完成抓取、递送等任务。
- 工业质检:在流水线上毫秒级识别缺陷部件,替代人工目检,提升产线效率。
2. 辅助技术与无障碍服务
- 视障辅助工具:通过语音描述周围物体位置(如“前方2米有台阶”),显著提升出行安全性。
- 智能界面导航:帮助残障用户快速定位屏幕控件,简化交互流程。
3. 数字工作流优化
- 文档自动化处理:自动提取合同中的关键字段(如签名位置、金额),减少人工录入错误。
- 智能仓储管理:AGV机器人实时识别货架商品,替代条码扫描,适应无标签场景。
LocateAnything的核心价值在于将视觉定位从“事后分析”转化为“即时交互”的基础能力。其单步预测机制与动态模式切换解决了传统模型在速度-精度权衡上的根本矛盾,尤其适合机器人操作、辅助技术等对响应时间敏感的场景。目前该模型已开源,支持本地部署与API调用,成为连接物理世界与数字智能的关键桥梁。随着具身智能与Agent技术的发展,此类实时定位能力将逐步成为人机交互的标准组件。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...