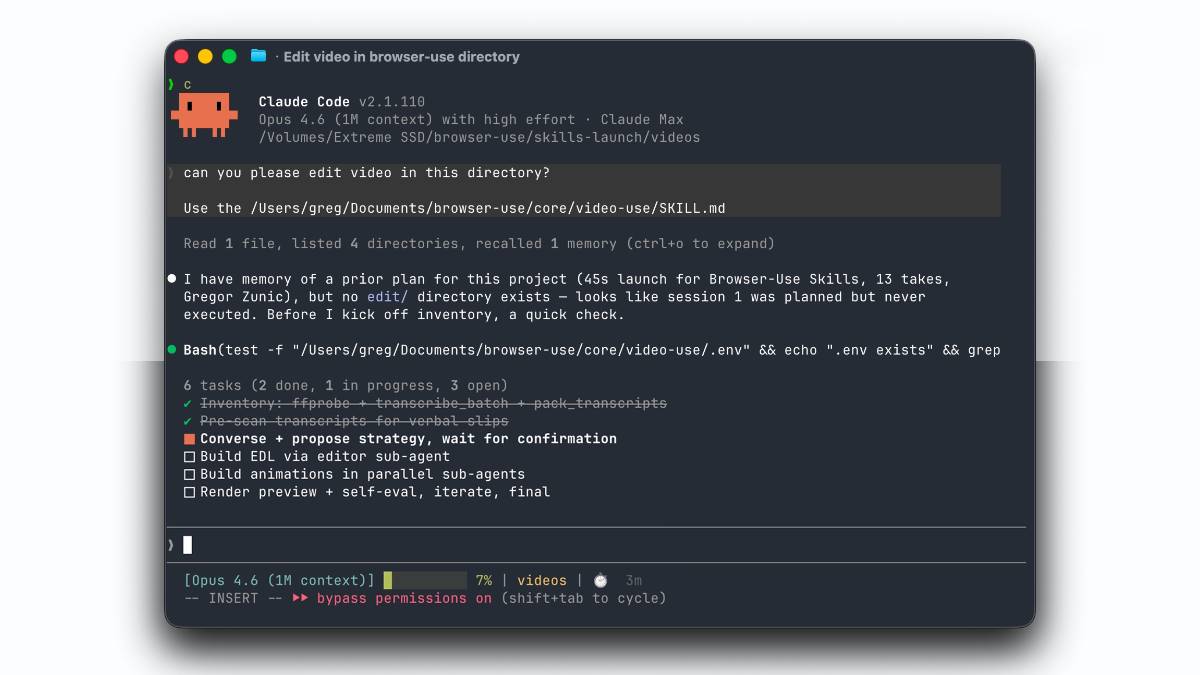
video-use核心特点
1. 自然语言交互驱动
- 用户只需用一句话描述需求(如“把这些素材剪成一条产品发布视频”),AI 自动完成从转录到成片的全流程,无需编写脚本或操作时间线。
- 剪辑逻辑完全基于文本指令,不依赖预设模板,适配口播、教程、会议记录等多样化场景。
2. 双层信息处理机制
- 音频转录层:始终加载轻量级文本摘要(约12KB的
takes_packed.md),包含逐词时间戳、说话人分离及音频事件标记,供大语言模型直接决策。 - 可视化复合层:仅在需要判断沉默时长、节奏差异等细节时,按需生成胶片条+波形图+文本标签的合成图像,避免处理海量视频帧的算力浪费。
3. 端到端自动化闭环
- 自动执行 填充词剔除、音频淡入淡出、字幕烧录、调色、动效叠加 六大环节,并通过自我评估机制检查剪辑点跳跃、爆音、字幕遮挡等问题,最多重试3次直至达标。
video-use技术原理
1. 视频理解降维设计
- LLM 不直接分析视频画面,而是通过结构化文本(如
takes_packed.md)理解内容,将视频剪辑问题转化为文本处理任务。例如:- 填充词识别:基于转录文本中的“umm”“uh”等标记自动裁剪。
- 沉默段判定:结合音频波形数据与文本停顿逻辑综合判断。
- 大幅降低计算成本:传统方案需处理数万帧画面(约4500万token),而 video-use 仅需12KB文本+少量关键图像。
2. 模块化工作流
- 转录层:依赖 ElevenLabs Scribe 生成高精度逐词时间戳转录(支持说话人分离)。
- 决策层:大语言模型基于文本摘要生成剪辑策略(如裁剪点、字幕样式)。
- 执行层:通过 FFmpeg 实现无损渲染,调用 HyperFrames/Remotion 等工具生成动效。
3. 自我修正机制
- 渲染后自动用
timeline_view工具检查关键帧连贯性,若检测到画面跳跃或音频异常,重新调整剪辑策略并重试,确保输出质量达标。
video-use核心功能
1. 智能内容优化
- 自动剔除冗余内容:精准识别并删除填充词、重复句、卡顿停顿及无效沉默段。
- 动态节奏调整:根据语义连贯性优化片段衔接,避免生硬跳切。
2. 专业级后期处理
- 音频处理:所有剪辑点自动添加30ms淡入淡出,消除爆音与突兀感。
- 调色统一:预设电影感、中性增强等风格,或通过自定义 FFmpeg 滤镜链实现个性化效果。
- 字幕生成:支持两词分块、字体/颜色/位置自定义,烧录至视频内避免外挂字幕丢失。
3. 高效工作流管理
- 会话记忆:剪辑进度保存在
project.md中,支持中断后续接。 - 并行处理:动画生成、音频处理等任务由子代理并行执行,缩短长视频处理时间。
video-use项目地址
- GitHub仓库:https://github.com/browser-use/video-use
video-use典型应用场景
1. 内容创作者
- 口播类视频:自动清理访谈/演讲中的口误、停顿,10分钟内输出带字幕成片,剪辑效率提升90%以上。
- 教程制作:高亮代码区域、添加操作标注,无需手动逐帧调整。
2. 企业级应用
- 培训课程:自动删除讲师卡顿内容,插入章节标题,交付周期缩短70%。
- 产品演示:快速生成专业级 Demo 视频,统一品牌调色与字幕风格。
3. 轻量化需求场景
- 会议记录:将录制内容精简为关键结论片段,便于内部流转。
- 旅行Vlog:手机原始素材一键生成电影感混剪,无需专业剪辑知识。
最后想说
video-use 的价值在于 将视频剪辑从“操作工具”转变为“描述意图”,尤其适合高频产出口播类内容的创作者。它通过结构化文本替代原始视频分析的技术路径,在保证质量的同时显著降低成本,但需注意其对音频转录质量的依赖性及内容类型适配范围。对于每周需处理多条教程或访谈视频的用户,配置后可单条视频节省3-4小时人工剪辑时间,长期使用 ROI 显著。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...