
多模态智能体模型
多模态智能体模型是能够同时感知、理解并操作多种数据模态(如文本、图像、音频、视频等),且具备自主决策与行动能力的AI系统。它不仅像传统模型一样“看懂”或“听懂”信息,更能主动调用工具、执行任务、验证结...

Qwen3.7-Plus – 阿里巴巴发布的多模态智能体模型
Qwen3.7-Plus是阿里巴巴于2026年6月2日正式发布的多模态智能体模型,定位为视觉与语言统一的智能体基座。它在Qwen3.7文本能力基础上深度融合视觉理解与行动能力,不仅能看懂图像/视频,还...
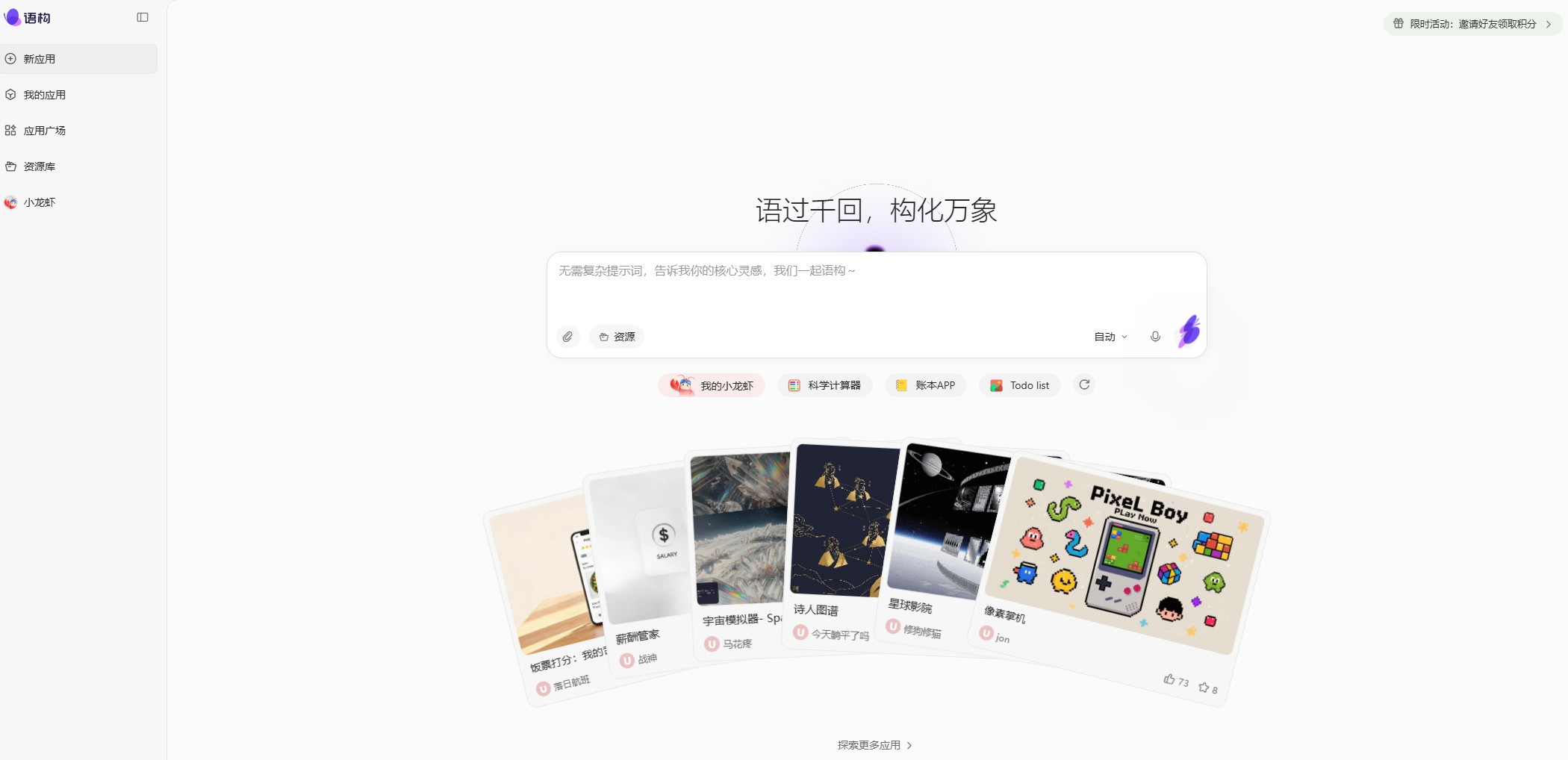
语构 – 阿里达摩院上线的零代码AI原生应用开发平台
语构是阿里达摩院于2026年6月2日正式上线的零代码AI原生应用开发平台,基于Vibe Coding技术实现“一句话生成完整应用”的能力,支持网页、小程序、互动工具等多元形态开发。 其核心突破在于彻底...
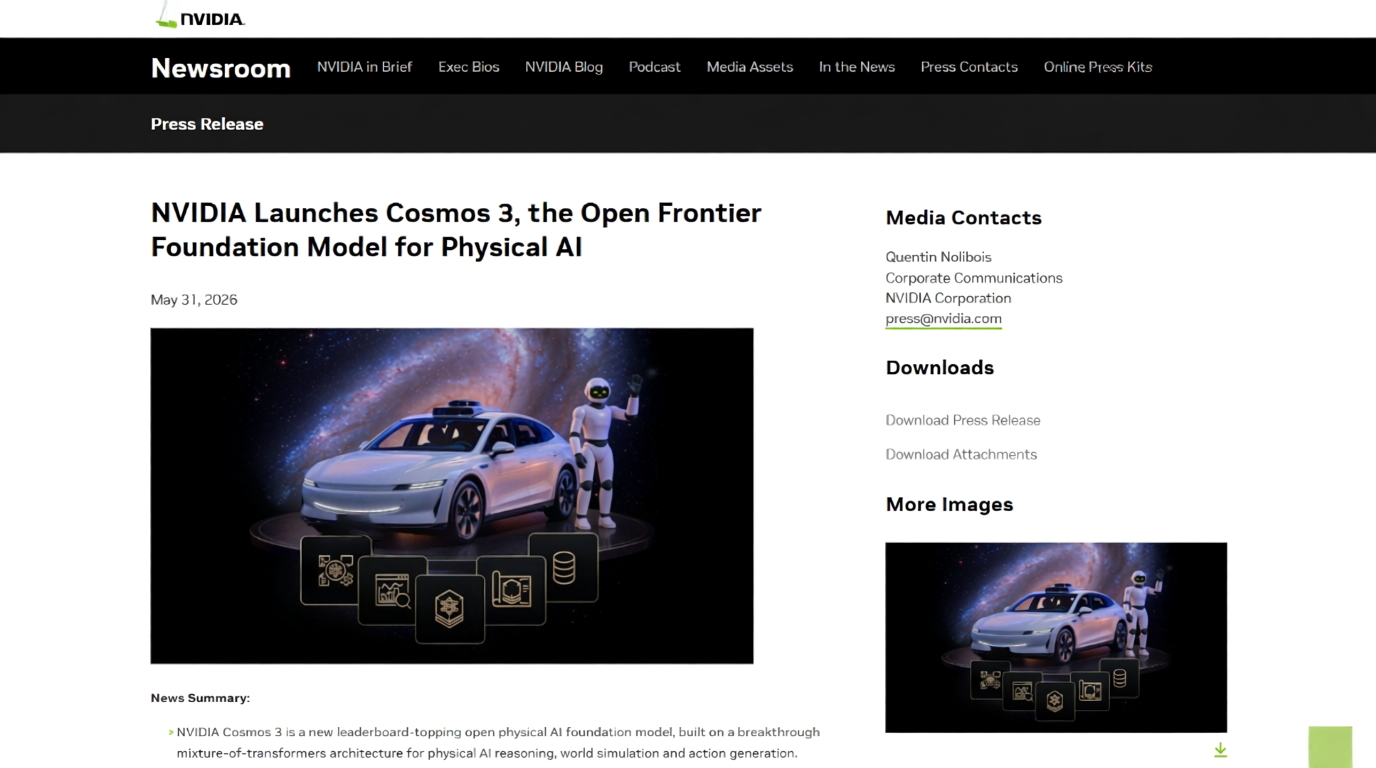
Cosmos 3 – 英伟达发布的开源全模态物理AI基础大模型
Cosmos 3是英伟达(NVIDIA)于2026年6月1日正式发布的全球首款全开源、全模态(Omni-Model)物理AI基础大模型。它被定义为一个“世界模型”,旨在赋予人工智能系统理解物理世界规律...
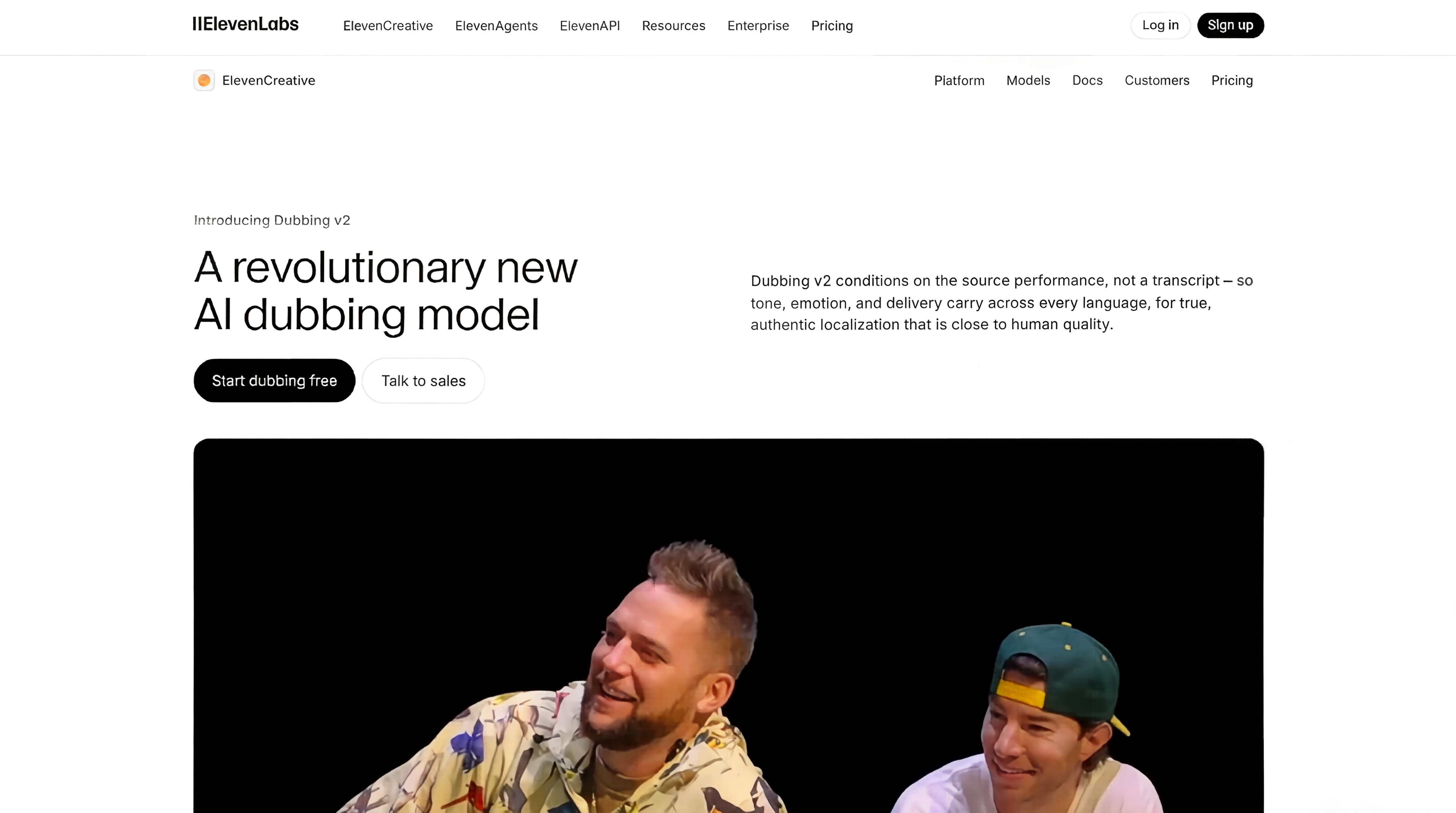
Dubbing v2 – ElevenLabs推出的最新AI配音模型
Dubbing v2是ElevenLabs推出的AI配音模型,首次实现 跨语言情感迁移,能够将原始语音中的语调、节奏、停顿、情绪起伏等表演细节完整保留并自然映射到目标语言中。 其核心突破在于 摒弃传统...
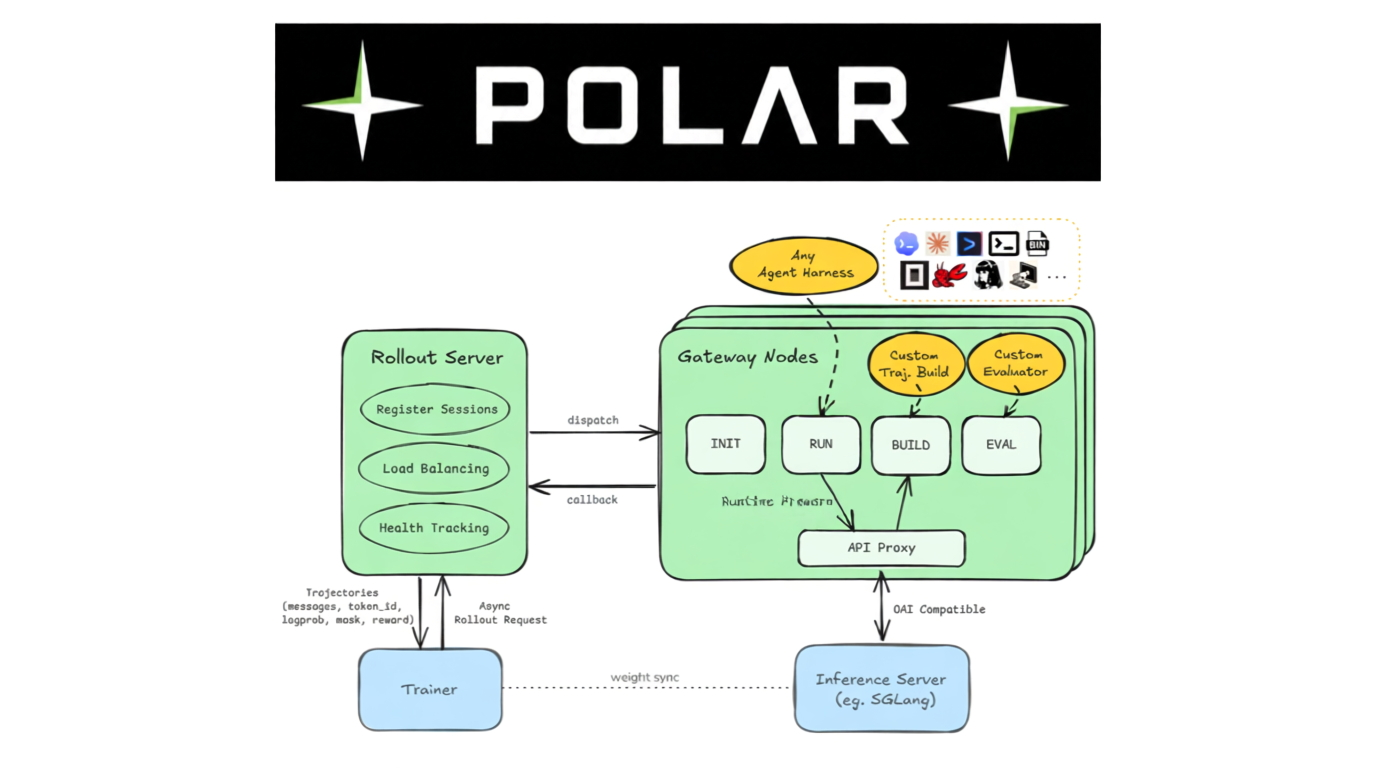
Polar – 英伟达开源的强化学习训练框架
Polar是英伟达(NVIDIA)开源的强化学习训练框架,专为解决代码智能体(如Codex、Claude Code、Qwen Code等)接入强化学习时的高成本与信号丢失问题而设计。 其核心突破在于无...

Gamma-World – 英伟达与清华大学推出的多智能体世界模型
Gamma-World是由英伟达与清华大学团队联合提出的多智能体世界模型,旨在解决传统单智能体世界模型无法模拟多主体在共享环境中交互的核心缺陷。 其核心突破在于通过身份对称性编码和稀疏通信架构,首次实...
Music v2 – ElevenLabs发布的新一代专业级音乐生成模型
Music v2是ElevenLabs发布的新一代专业级音乐生成模型,其核心突破在于将AI音乐创作从“抽卡式随机生成”推进到可精准编辑、支持商业落地的工业化阶段。 该模型基于完全授权的数据集训练,生成...

Qwen-VLA – 阿里通义团队最新发布的通用机器人基础模型
Qwen-VLA是阿里通义团队最新发布的通用机器人基础模型。 简单来说,如果之前的视觉模型是让AI拥有一双“眼睛”去理解世界,那么Qwen-VLA就是给这双眼睛配上了“灵活的手脚”,让AI不仅能看、能...

Gemini 3.1 Pro – 谷歌发布的旗舰人工智能基础模型
Gemini 3.1 Pro是谷歌(Google)发布的新一代旗舰人工智能基础模型。它定位为一款专为解决复杂问题而生的高阶推理工具,主打深度思考和复杂任务处理。 Gemini 3.1 Pro核心特点与...