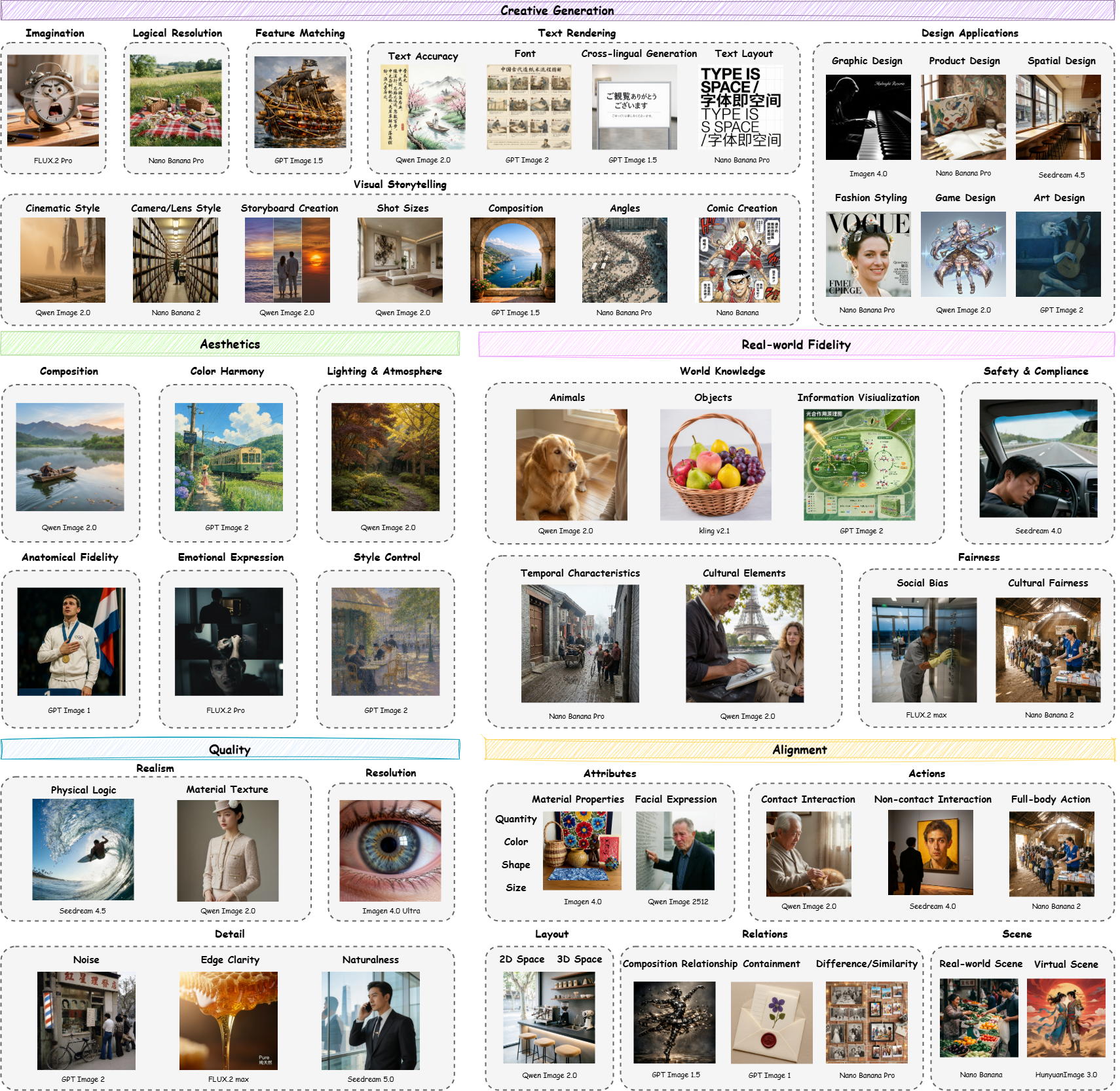
Qwen-Image-Bench – 通义千问团队推出的文生图专用评测基准
Qwen-Image-Bench是阿里云通义千问团队推出的文生图专用评测基准,主打创作者视角与专业标准。含1000 个中英双语 prompt,从画质、美学、图文对齐、真实保真、创作生成 5 大维度,设...

Guizang Social Card Skill – 归藏开源的AI图文排版工具
Guizang Social Card Skill是由开发者 op7418(归藏)开源的AI图文排版工具,专为小红书、公众号等平台设计,核心目标是通过技术路径规避平台对 AI 生成内容的强制标识要求...
Wall-OSS-0.5 – 自变量机器人团队开源的具身基础模型
Wall-OSS-0.5是自变量机器人团队开源的全球首个实现"预训练即可部署"的具身基础模型,无需针对下游任务进行后训练,直接在真实机器人上完成零样本操作任务,其核心突破在于通过技术重构使预训练模型自...
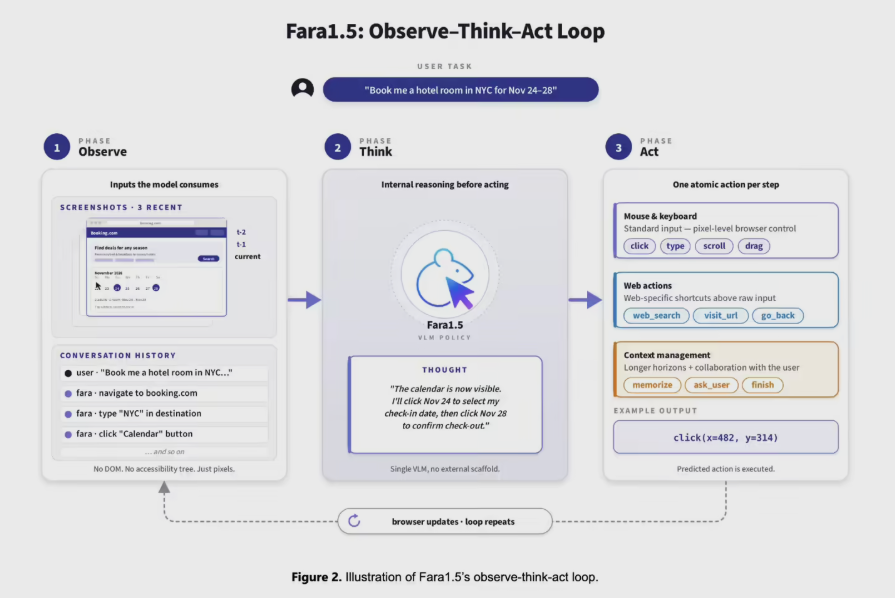
Fara1.5 – 微软研究院发布的浏览器智能体模型系列
Fara1.5是微软研究院AI Frontiers实验室发布的浏览器智能体模型系列,专为直接操作真实浏览器界面完成复杂任务而设计,不依赖网页DOM结构或无障碍树,仅通过视觉截图理解界面。 其核心突破在...

国内文生图ai工具有哪些
文生图AI工具是将文字描述自动转化为图像的智能创作工具,依托大模型理解语义并生成视觉内容。核心优势为零门槛、高效出图、风格多元,支持写实、插画、国潮等多种风格。国内主流工具如文心一格、通义万相、豆包...
MAI-Image-2.5 – 微软发布的最新文本生成图像模型
MAI-Image-2.5是微软发布的最新文本生成图像模型,在权威评测平台Arena的文生图排行榜中以1254分位列全球第三,仅次于OpenAI的gpt-image-2. 该模型重点强化了文字渲染能力...

ForgeTrain – 面壁智能联合清华等全球首个由AI自主编写
ForgeTrain是由面壁智能联合清华大学及OpenBMB开源社区发布的全球首个完全由AI自主编写、零人类代码介入的生产级大模型预训练框架。 其核心突破在于AI首次独立完成大模型训练基础设施的端到端...

端侧大模型
端侧大模型(On-device Large Models)简单来说,就是将人工智能模型直接部署在手机、电脑、汽车、智能家居等终端设备上,让设备在本地就能完成数据的分析、推理和决策,而无需依赖云端服务器...

Gemini 3 Flash – 谷歌推出的轻量级多模态大模型
Gemini 3 Flash是谷歌推出的轻量级高性能多模态大模型,核心定位是以速度与成本效率为核心优化目标,在保持接近旗舰模型推理能力的同时,响应速度达到前代Gemini 2.5 Pro的3倍,且完成...

Keye-VL-2.0-30B-A3B – 快手发布的30B级多模态大模型
Keye-VL-2.0-30B-A3B是快手发布的30B级多模态大模型,其核心突破在于首次将DSA机制引入多模态领域,实现256K超长上下文的高效处理能力,并在长视频时序理解任务中达到接近无损的推理精...