Hy-MT2 – 腾讯混元团队开源的新一代翻译大模型家族
腾讯混元团队开源的Hy-MT2是新一代多语言翻译大模型家族,包含1.8B、7B、30B-A3B三种尺寸,支持33种语言互译及5种民族语言/方言翻译,核心突破在于通过1.25-bit极端量化技术将轻量级...
CloudDM – ClouGence开发的开源数据库统一管理平台
CloudDM是由开云集致(ClouGence)开发的开源数据库统一管理平台,基于Apache 2.0协议全面开放所有功能,核心解决多源数据库的查询、变更审批与权限管控问题,支持 30+ 种数据源的统...

为何AI总会一本正经地胡说八道
为何AI总会一本正经地胡说八道?AI“一本正经地胡说八道”的本质原因是大语言模型的核心机制是基于统计概率预测文本,而非真正理解事实或逻辑,导致其在知识盲区或数据不足时倾向于编造看似合理但错误的内容,且...
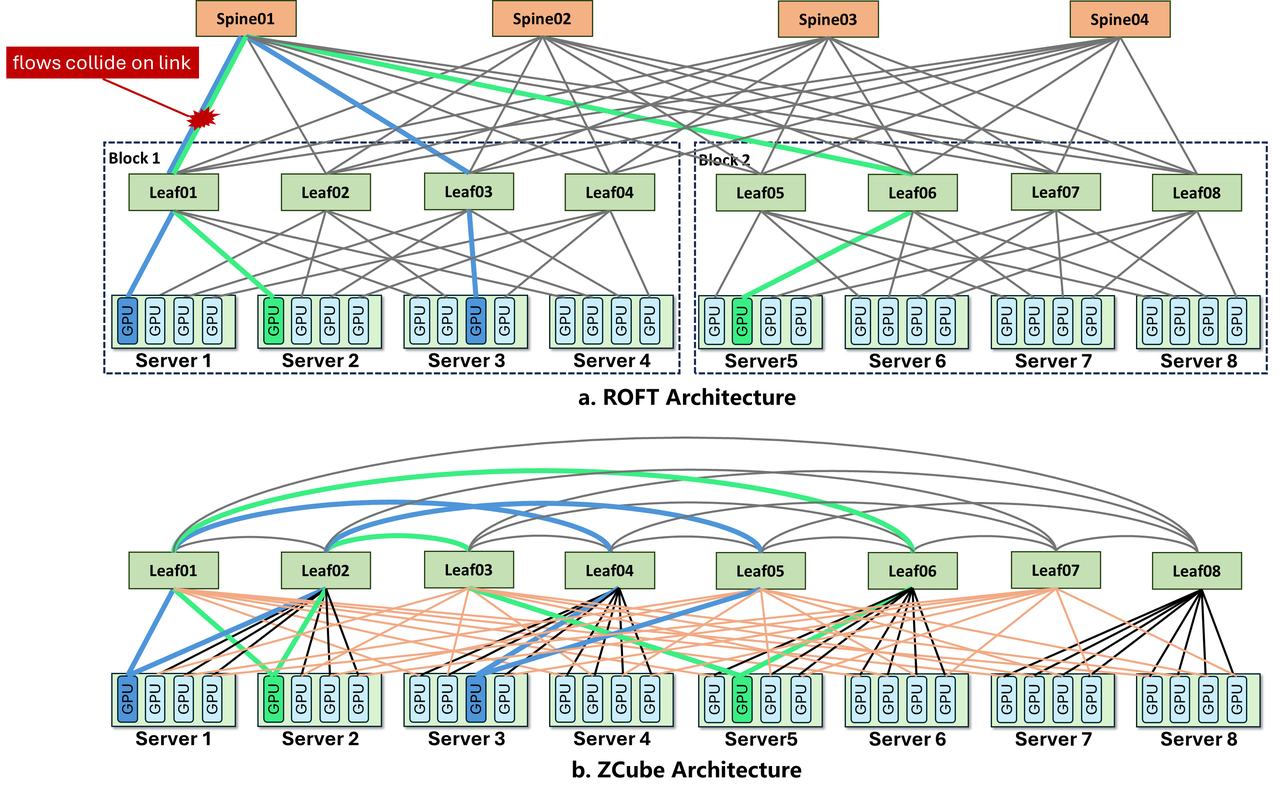
ZCube – 智谱联合清华大学开发的新型AI集群网络架构
ZCube是由智谱联合清华大学、驭驯网络开发的新型AI集群网络架构,专为解决大模型推理场景中的结构性网络拥塞问题而设计。 其核心突破在于彻底重构网络拓扑,通过取消传统Clos架构的Spine层、采用扁...
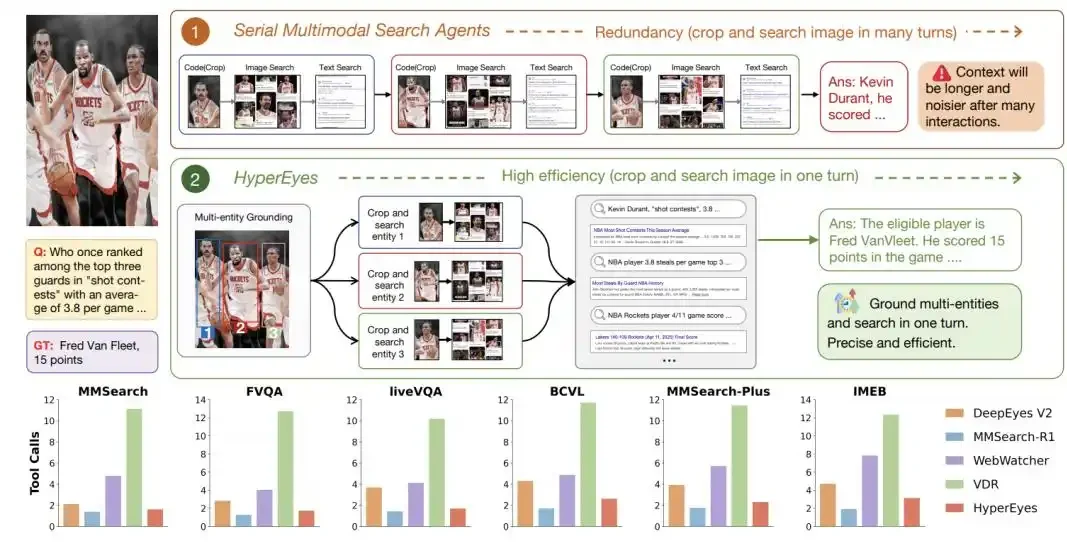
HyperEyes – 小红书研究团队提出的并行多模态搜索智能体
HyperEyes是由小红书研究团队提出的并行多模态搜索智能体,通过重构动作空间、数据合成与强化学习框架,解决了传统多模态搜索中“串行调用”导致的效率低下问题,实现了单次交互内对图片中多个目标的并发定...

Agora-1 – Odyssey发布的多人实时互动的AI世界模型
Agora-1是由AI初创公司Odyssey发布的全球首个支持多人实时互动的AI世界模型,其核心突破在于实现了人类与 AI 智能体在同一个动态生成的虚拟环境中同步交互,而非传统单人体验的静态生成内容...
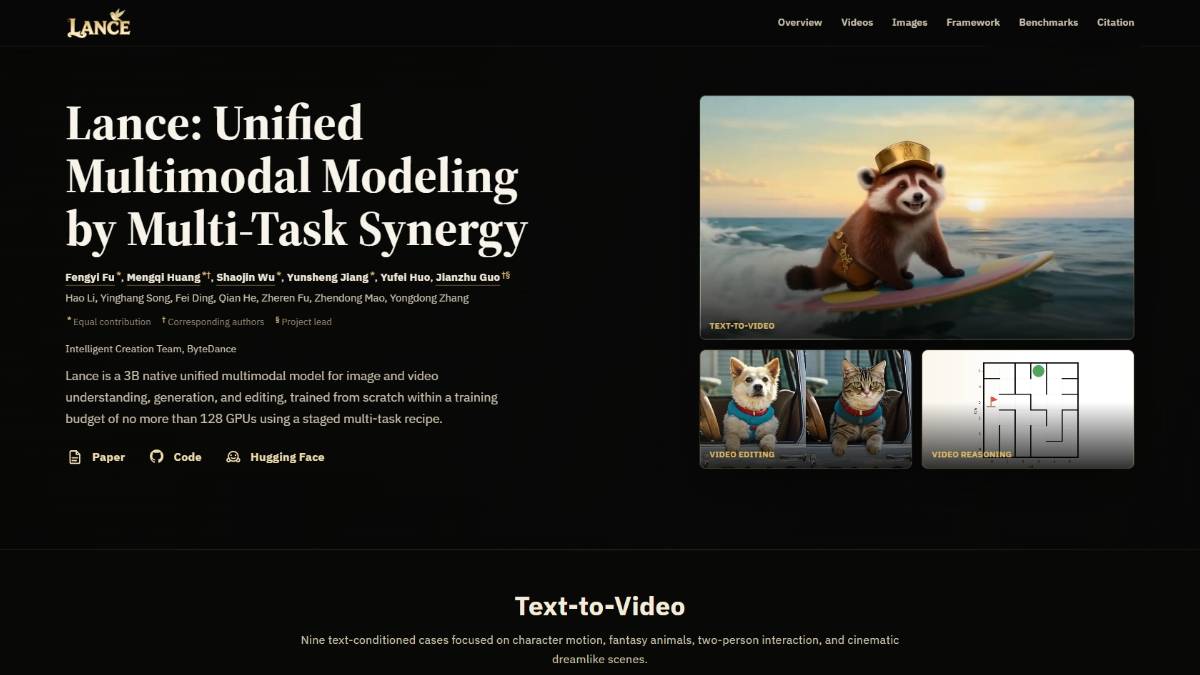
Lance – 字节跳动推出的原生统一的多模态模型
Lance 是字节跳动推出的一个原生统一的多模态模型。它是一个参数量为 30亿(3B) 的研究性项目,旨在打破图像和视频在理解、生成、编辑任务上的壁垒。 与许多需要针对不同任务单独微调的模型不同,La...

HiDream-O1-Image-Pro – 智象未来发布的图像生成大模型
HiDream-O1-Image-Pro是智象未来发布的超2000亿参数原生全模态图像生成大模型,采用全球首创的像素级统一Transformer(UiT)架构,彻底摒弃传统VAE压缩与独立文本编码器...

Qwen3.5-LiveTranslate – 阿里通义发布的实时语音翻译模型
Qwen3.5-LiveTranslate是阿里通义千问发布的实时语音翻译模型,核心突破在于实现2.8秒端到端字均延迟、支持60种语言输入与29种语言语音输出,并通过多模态技术保留说话人原声音色与情绪...

Qwen3.7-Max – 阿里巴巴发布的千问系列新一代旗舰大模型
Qwen3.7-Max是阿里巴巴发布的千问系列新一代旗舰大模型,核心定位为面向智能体(Agent)时代的全能基座模型,其最大突破在于无需人工干预即可自主完成超长周期复杂任务(如35小时连续工作、115...