
16g显存能跑32b模型吗
跑是可以跑,但是有很大的门槛 16GB 显存想要运行 32B(320亿参数)模型,无法使用标准的 FP16 精度(那需要约 65GB 显存),必须使用量化版本(INT4 或 INT8)。 简单来说,你...

什么是开源大模型
开源大模型(Open Source Large Model)是人工智能领域的一场“技术平权”运动。简单来说,它指的是将大模型的核心资产(如代码、权重参数、训练数据等)向公众公开,允许开发者自由下载、使...

RAG和embedding区别
RAG(检索增强生成)和Embedding(嵌入)并不是同一个层面的概念,它们的关系更像是“整个系统”与“核心组件”的关系。 为了让你一目了然,我们可以用一个通俗的比喻: RAG是一座“智能图书馆...

语音大模型是什么
语音大模型(SpeechLM)是人工智能领域的一次重要技术跃迁,它旨在让AI像人类一样,直接“听懂”并“说出”语言,而非依赖“语音转文字”的中间环节。 简单来说,它是一场从“间接翻译”到“直接理解”的...

Seeduplex – 字节跳动发布的原生全双工语音大模型
Seeduplex是字节跳动Seed团队2026年4月9日发布的原生全双工语音大模型,已全量上线豆包、抖音App。它突破传统半双工“回合制问答”限制,实现“边听边说”的实时自然交互。通过语音语义联合建...

小米XLA大模型 – 小米智能驾驶领域研发的一款端到端认知大模型
小米XLA大模型是小米集团专为智能驾驶领域研发的一款端到端认知大模型,是其HAD(Hyper Autonomous Driving,小米超级智能驾驶)系统的核心技术升级。 它的核心突破在于首次将“辅助...
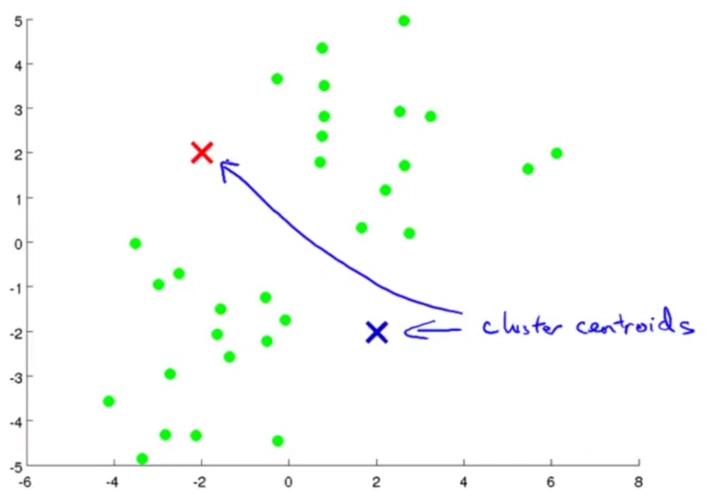
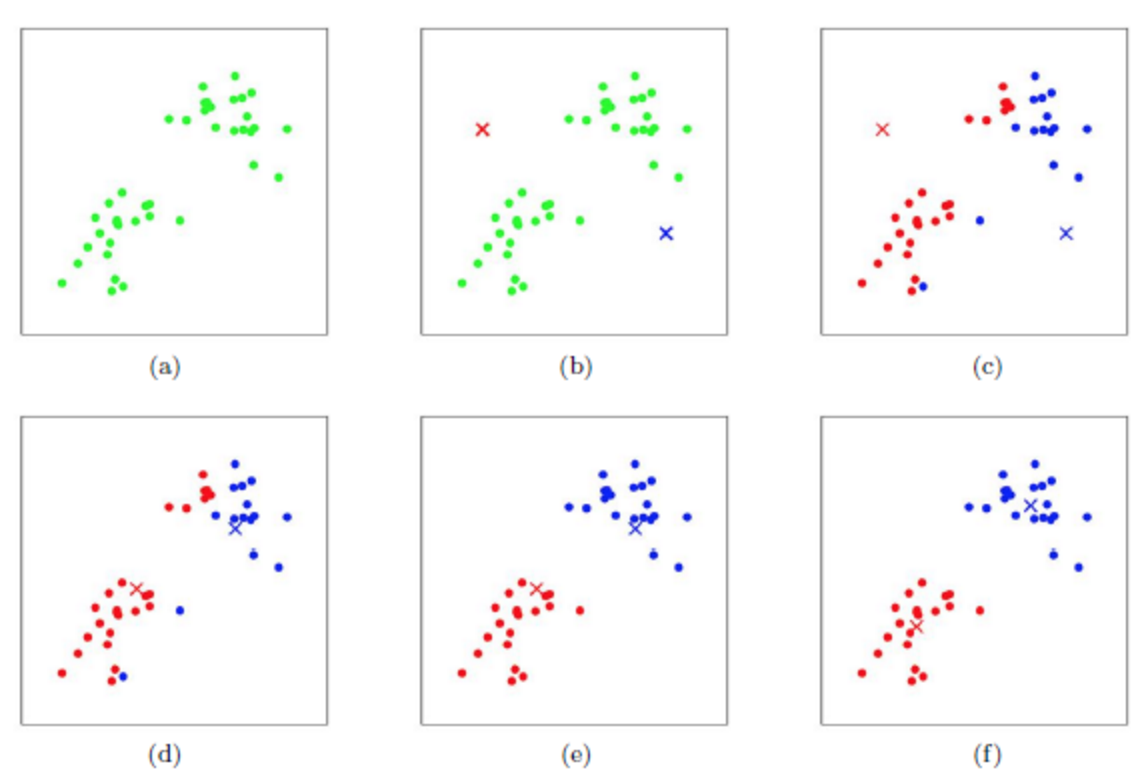
kmeans算法原理
K-Means(K均值)算法是一种经典的无监督学习算法,主要用于数据聚类分析。它的核心思想非常直观,可以概括为“物以类聚,人以群分”,目标是将数据自动划分成K个内部相似、彼此不同的“簇”(Cluste...
k近邻算法和kmeans的区别
K近邻算法(KNN)和K均值聚类(K-Means)虽然名字里都有一个“K”,但它们是两个目的、原理和应用场景都截然不同的算法。 最核心的区别在于:KNN是一种有监督学习算法,用于分类或回归;而K-Me...
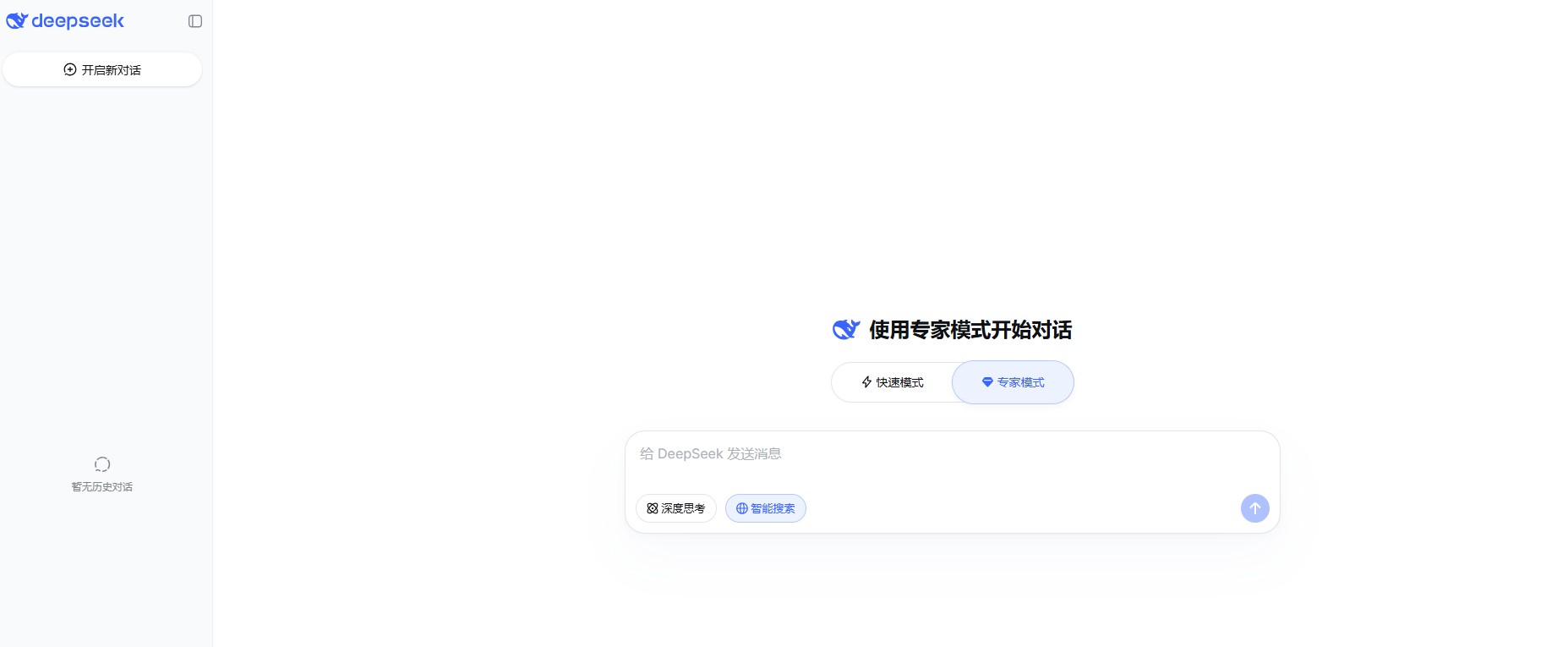
DeepSeek重要更新:上线专家模式 已经可以使用
2026年4月8日,DeepSeek迎来重要产品升级,专家模式正式上线,同步提供快速模式与专家模式双选择,为平台首次引入模式分层设计。 专家模式依托混合专家模型架构,强化深度推理、思维链可视化与引用溯...

VoxCPM2 – OpenBMB团队开源的一款语音生成基座模型
VoxCPM2 是由面壁智能(OpenBMB)团队开源的一款新一代语音生成基座模型。 如果说上一代 VoxCPM(0.5B)是以“小钢炮”著称的轻量化模型,那么 VoxCPM2 则是全面进化的“全能型...