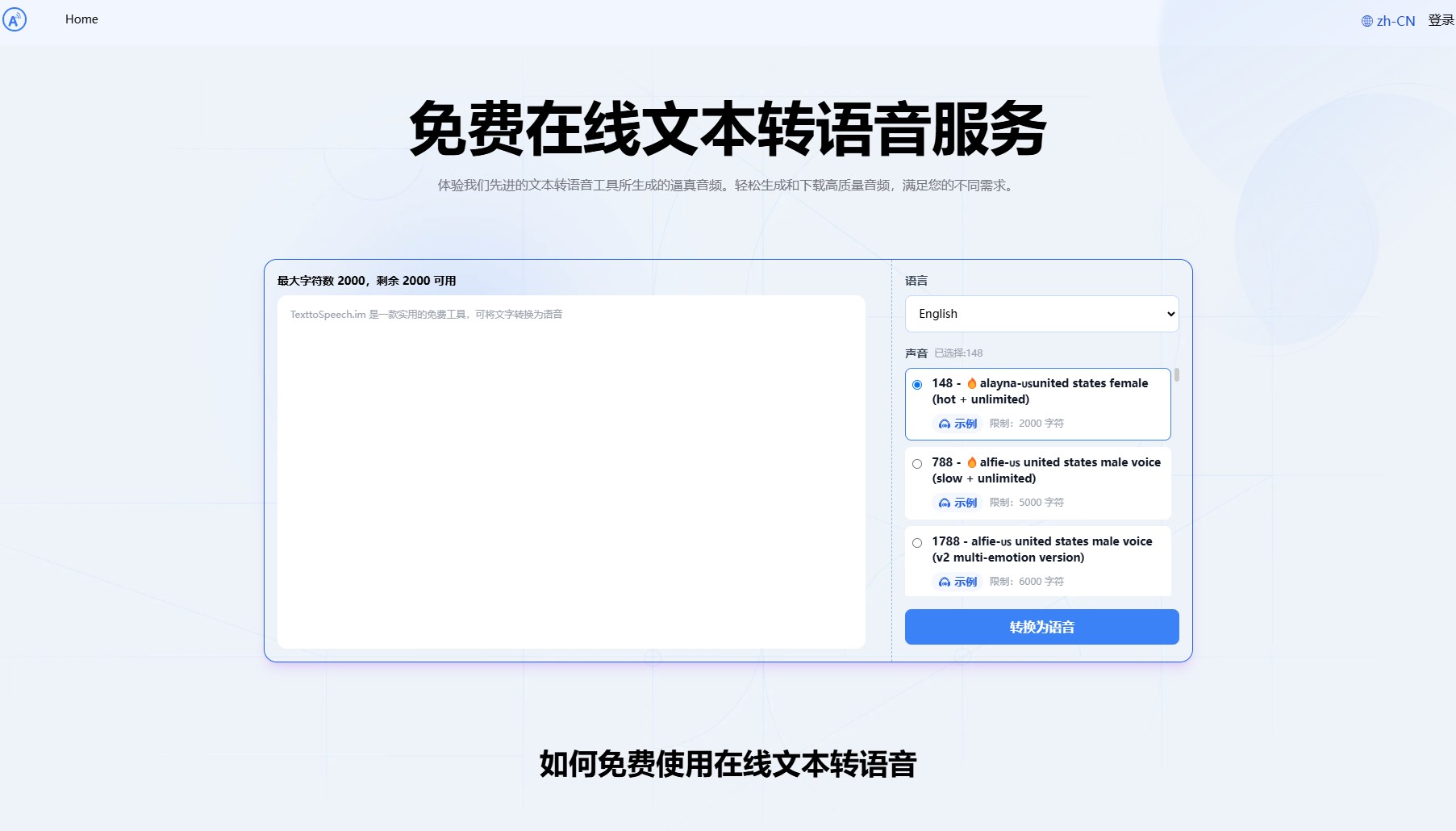
功能概述
TextToSpeech 是一种将书面文字(文本)转换为人类语音(音频)的技术。它通过合成算法模拟人类的发声过程,生成可听的语音内容,是人工智能语音技术的重要组成部分。

TextToSpeech介绍
- 基础文本合成
- 输入:接收任何格式的文本输入(如文档、网页、对话、代码注释等)。
- 输出:实时或批量生成对应的语音音频文件(如MP3、WAV)或实时播放流。
- 语音定制与风格选择
- 多音色库:提供多种预设音色(男声、女声、童声、不同年龄和性格),满足不同场景需求。
- 语音克隆:允许用户上传短段语音样本,生成具有特定个人音色的语音(需注意合规与隐私)。
- 情感与风格调整:可调节语音的语速、音调、音量,甚至注入特定情感(如开心、悲伤、严肃),使表达更生动。
- 多语言与方言支持
- 全球语言覆盖:支持数十种乃至上百种语言的合成。
- 方言与口音:部分先进TTS系统支持特定语言的方言或区域口音(如美式/英式英语、普通话/粤语)。
- 高级语音特性控制
- SSML支持:使用语音合成标记语言,精细控制停顿、重音、强调、数字读法等,使语音更自然、更符合预期。
- 多说话人对话:支持在一个音频中切换多个不同音色,模拟对话场景。
- 应用场景集成
- API接口:提供云服务API,方便集成到各类应用、网站、智能设备中。
- 离线引擎:部分SDK支持在本地设备运行,无需网络连接,保护隐私并降低延迟。
- 音频后处理
- 背景音乐与音效:可为生成的语音添加背景音乐或音效,制作更丰富的音频内容。
- 音频编辑:提供简单的剪辑、拼接功能。
TextToSpeech功能
- 高自然度与流畅性
- 现代TTS(尤其是神经网络TTS) 的核心优势在于生成的语音几乎与真人无异,包括自然的停顿、语调变化和呼吸感,极大提升了聆听体验。
- 高效性与低成本
- 速度快:可实时生成语音,远快于真人录音。
- 成本低:相比雇佣专业配音演员或播音员,TTS的边际成本极低,尤其适合大批量、重复性内容的生成。
- 灵活性与可扩展性
- 内容更新便捷:文本内容修改后,语音可快速重新生成,无需重新录制。
- 多场景适配:从简单的语音播报到复杂的有声书、视频配音,均可通过调整参数和音色来适配。
- 无障碍与普惠性
- 视觉障碍辅助:为视障用户提供“听”到的数字世界,是重要的辅助技术。
- 语言学习工具:帮助学习者练习听力和发音。
- 信息获取平等化:让不识字或阅读困难的人群也能获取信息。
- 技术驱动,持续进化
- 随着AI大模型的发展,TTS在情感表达、上下文理解、多语言混合等方面的能力正在快速提升,个性化和智能化是未来趋势。
- 隐私与安全考量
- 语音克隆 的双刃剑:既可用于个性化服务(如为失声者提供语音),也可能被滥用于诈骗。因此,负责任的平台会建立严格的审核和授权机制。
TextToSpeech总结
TextToSpeech 是将文字世界与声音世界连接起来的关键桥梁,其核心价值在于“让信息可听”。
- 它解决了什么问题?
- 解决了信息获取方式单一的问题,为视觉障碍者和阅读困难者提供了解决方案。
- 解决了内容生产效率问题,快速将文本转化为音频内容。
- 解决了多媒体内容创作门槛问题,为视频、动画、播客等提供便捷的配音方案。
- 解决了标准化语音播报需求,如客服、导航、公告等场景。
- 它的核心优势是什么?
- 1.极致的效率与成本效益:批量、快速、低成本地生成高质量语音。
- 2.高自然度与可定制性:提供接近真人的音质和丰富的个性化选项。
- 3.强大的集成能力:易于嵌入到各类数字产品和服务中。
- 适合谁?
- 内容创作者:为视频、动画、课程、播客制作配音。
- 企业与机构:用于客服语音、产品介绍、内部培训、无障碍服务。
- 开发者与产品经理:集成到APP、网站、智能设备中,提升用户体验。
- 教育工作者与学生:制作学习材料,辅助语言学习。
- 个人用户:有声阅读、语音助手、个性化消息等。
- 注意事项
- 情感表达局限:虽然技术进步巨大,但TTS在表现极度复杂、微妙的人类情感时,仍可能不如专业配音演员。
- 版权与伦理:使用语音克隆技术时,必须确保获得明确授权,遵守法律法规。
- 技术依赖:高质量的TTS通常需要较强的算力或云服务支持。