文生图模型(Text-to-Image Model)是一种人工智能技术,它能根据你输入的文字描述,从零开始生成一张全新的、符合描述的图片。它不是简单的图片拼接或修改,而是像一位画师,通过学习海量图文数据,理解了文字与图像之间的关联,最终将你的创意“画”出来。
文生图模型是如何工作的?
要理解文生图模型的工作原理,我们可以把它想象成一个由两个核心模块组成的智能绘画系统:
- 一个能“读懂文字”的翻译官 (文本编码器)
- 一个能“无中生有”的画师 (图像生成器)
这两个模块协同工作,就能实现“输入文字,生成图片”的神奇过程。
第一步:让AI“读懂”你的话
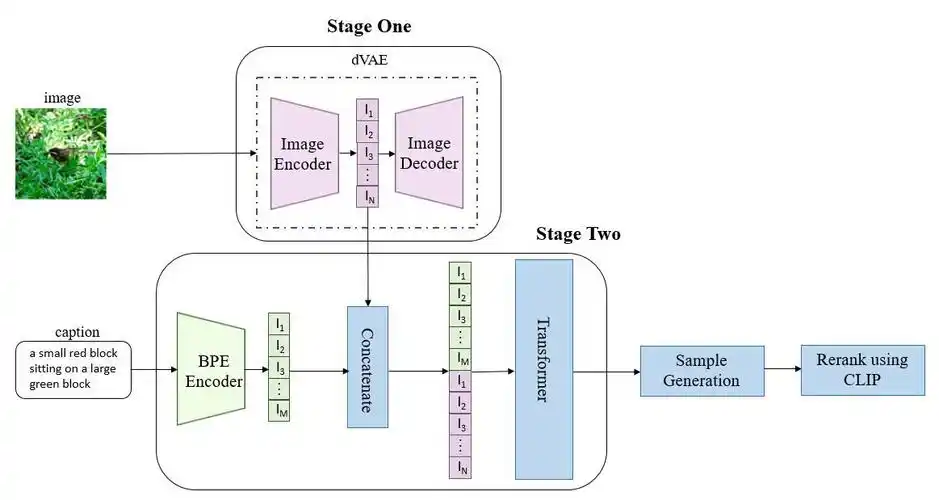
当你输入“一只戴着围巾的橘猫,坐在雪地里”时,AI并不能像人类一样理解这些文字的含义。这时,就需要“翻译官”——文本编码器(例如广泛使用的CLIP模型)出场。
这个编码器在海量的“图片-文字”配对数据上进行过训练,它学会了将文字转换成AI能够理解的数字向量(也称为特征向量)。在这个向量空间里,“橘猫”的文字特征会和所有橘猫图片的图像特征紧密关联,“雪地”也是如此。经过这一步,你的文字描述就被翻译成了AI能理解的“创作指令”。
第二步:让AI“画出”你想要的图
拿到“创作指令”后,就轮到“画师”——图像生成器开始工作了。目前主流的图像生成器采用的是扩散模型(Diffusion Model)。
扩散模型的原理非常巧妙,可以比作一个“从混沌中创造秩序”的过程:
- 学习过程(加噪):在训练阶段,AI会看一张清晰的图片(比如一只猫),然后一步步给它加上随机的噪点(就像往清水里滴墨水),直到这张图变成一团完全杂乱的噪点,什么都看不出来。这个过程教会AI“一张图是如何变成噪点的”。
- 创作过程(去噪):当AI要画画时,它会反其道而行之。它会从一团随机的噪点开始,然后根据文本编码器给出的“创作指令”,一步步地预测并去掉噪点。每去掉一点噪点,图像就会变得更清晰一些,最终从一团混沌中“浮现”出你想要的“戴着围巾的橘猫”。
技术的演进:从GAN到扩散模型
文生图技术并非一蹴而就,它经历了几个重要的发展阶段:
- 早期探索(GANs):早期的模型主要使用生成对抗网络(GAN)。它通过两个AI(一个负责生成假图,一个负责鉴别真假)相互“博弈”来生成图像。虽然效果在当时很惊艳,但GANs训练过程非常不稳定,容易失败,且很难生成复杂、细节丰富的图像。
- 当前主流(扩散模型):扩散模型的出现解决了GANs的痛点。它训练更稳定,生成的图像质量更高、细节更丰富,并且能很好地理解和执行复杂的文字描述。因此,包括Midjourney、Stable Diffusion在内的所有主流AI绘画工具,其核心都是扩散模型。
- 架构创新(Diffusion Transformer, DiT):这是目前最前沿的架构。它将强大的Transformer(也是大型语言模型的核心)与扩散模型相结合,用Transformer来处理图像生成过程。这种架构在处理复杂场景、多对象关系以及精准生成图像内文字方面表现尤为出色。百度的ERNIE-Image、智谱的CogView4等新一代国产模型都采用了这种先进架构。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...