
这其实是当前大模型架构(尤其是像Qwen2.5-VL这类视觉语言模型)里,为了解决“既要看得清细节,又要算得快”这个矛盾而采用的一种混合架构设计。它并不是指某一个具体的模型名字,而是指一种将混合注意力机制与专家混合架构相结合的技术方案。
这种设计主要是为了解决单一架构在处理长文本或高分辨率图像时“算力消耗大”和“信息捕捉不全”的矛盾。
核心概念拆解
混合注意力机制
传统的Transformer模型通常只使用一种注意力机制(如标准的多头自注意力),但这在处理超长序列(如长文档、高清视频)时计算量呈平方级增长,速度极慢。
“混合注意力”是指在同一个模型中,结合使用多种不同的注意力机制,取长补短:
- 全局注意力:用于捕捉长距离的依赖关系(比如文章开头和结尾的联系)。
- 局部/滑动窗口注意力:只关注当前词周围的局部信息,计算速度极快,适合捕捉细节特征。
- 线性注意力:通过数学近似将计算复杂度从平方级降低到线性级,大幅提升推理速度。
作用:让模型既能“纵观全局”,又能“聚焦细节”,同时还能保持极快的推理速度。
专家混合架构
这是为了解决模型“容量”与“推理成本”的矛盾。
- 原理:模型内部包含多个“专家网络”,每个专家擅长处理不同类型的任务或数据(例如有的擅长处理语法,有的擅长处理逻辑)。
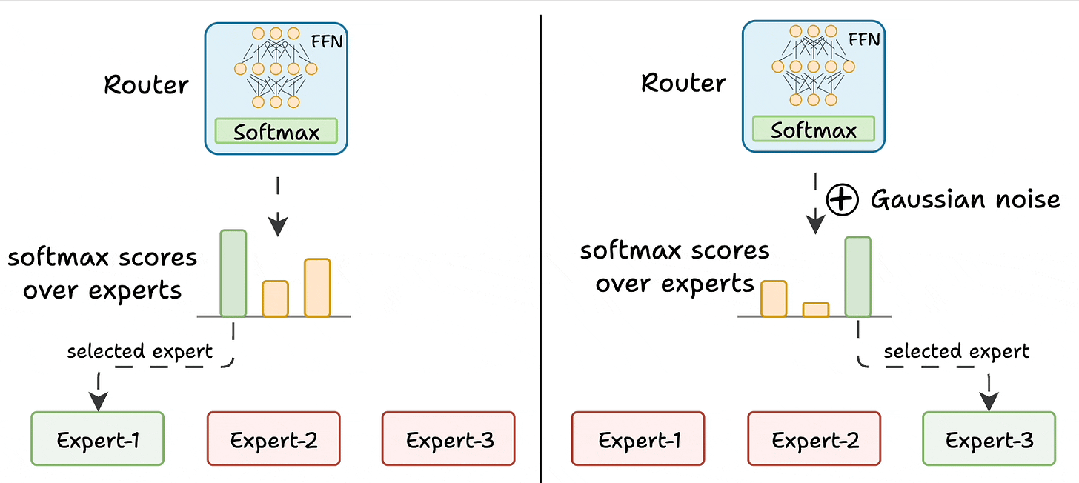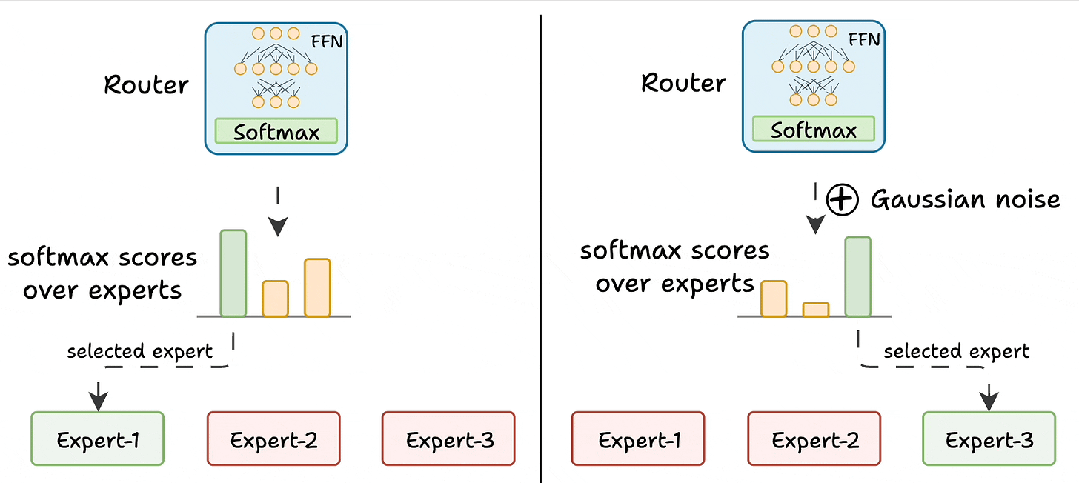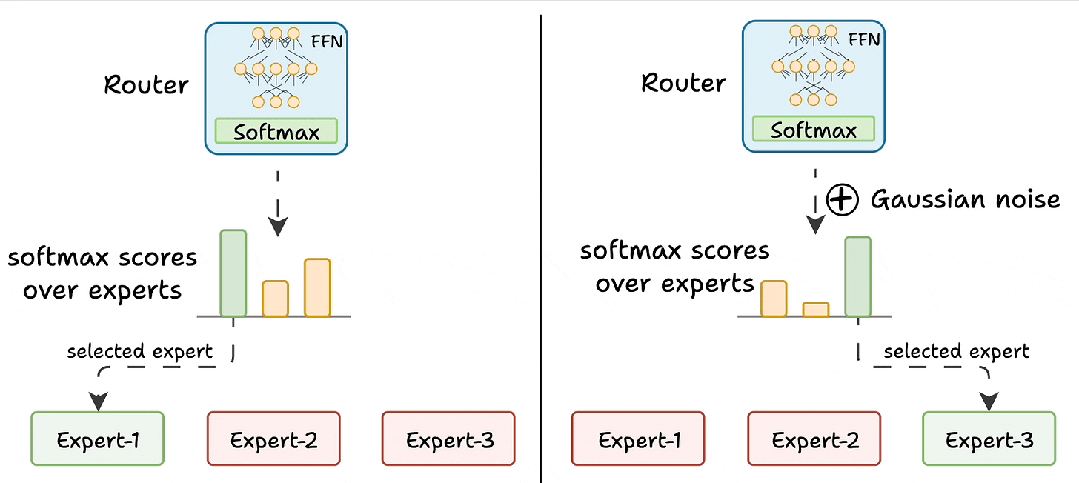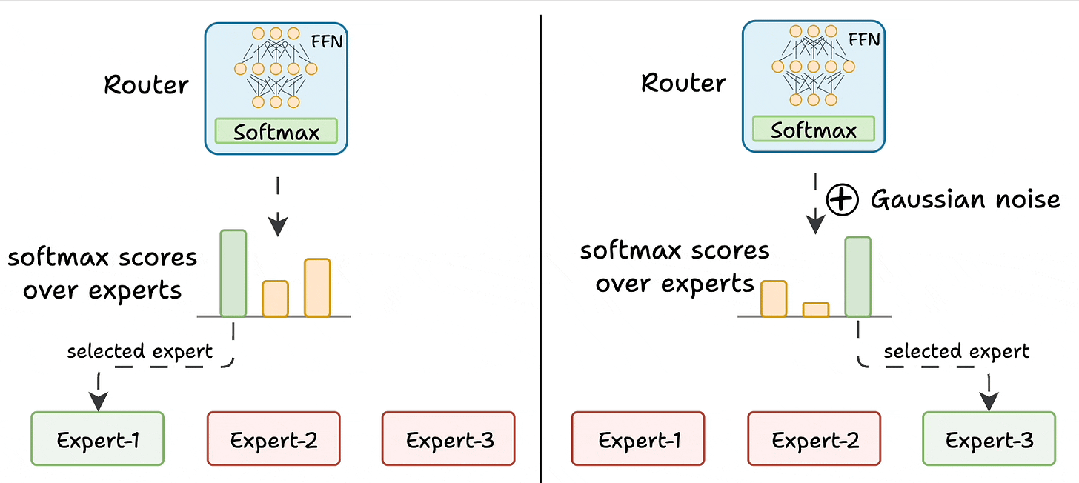
- 动态路由:当输入一段数据时,一个“路由器”会根据数据内容,只激活最相关的几个专家(通常是Top-2或Top-4)来进行计算,而其他专家处于休眠状态。
作用:极大地增加了模型的参数量(提升智能上限),但每次推理时实际激活的参数量却很少(保持低成本)。
“混合注意力专家”架构的优势
将这两者结合(例如在Qwen2.5-VL等模型中),就构成了所谓的“混合注意力专家”架构,其核心优势在于:
- 多尺度感知能力:混合注意力让模型在处理视觉信息时,既能看清图片的微小细节(局部窗口),又能理解图片的整体构图和语义(全局注意力)。
- 极高的推理效率:
- 专家混合架构保证了模型虽然很大(比如千亿参数),但运行起来像一个小模型一样快。
- 混合注意力避免了处理长视频或长文档时的“显存爆炸”。
- 更强的泛化性:不同的专家可以专注于不同的模态(如文本专家、图像专家、代码专家),使得模型在处理跨模态任务(如“看图写代码”)时表现更出色。
概况
“混合注意力专家”是大模型架构进化的高级形态。
- 以前的模型:像是一个全能但反应慢的学者,处理所有信息都用同一种方式,且事必躬亲。
- 混合注意力专家模型:像是一个高效的专家顾问团。
- 混合注意力是他们的“眼睛”,既能用显微镜看细节,又能用望远镜看全局。
- 专家混合是他们的“大脑”,遇到数学题就交给数学专家,遇到写作题就交给文学专家,分工合作,效率极高。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...