
视觉语言模型(VLM)和多模态大模型(MLLM)的核心区别在于能力范围和技术架构。简单来说,VLM是专注于“看懂”图像并“说出”内容的专家,而MLLM则是在此基础上,以强大的语言模型为核心,能够处理和理解更多类型信息的“全能大脑”。
你可以这样理解它们的关系:VLM是MLLM的一个重要组成部分和前身,而MLLM是VLM能力的扩展和进化。
核心定位不同
- 视觉语言模型 (VLM): “图文专家”
VLM的核心任务是建立图像和文本之间的关联。它像一个“能看懂世界的文本专家”,主要专注于处理和理解图像+文本这两种模态的信息。它的目标是实现图文间的双向理解,例如看图说话或根据文字找图片。
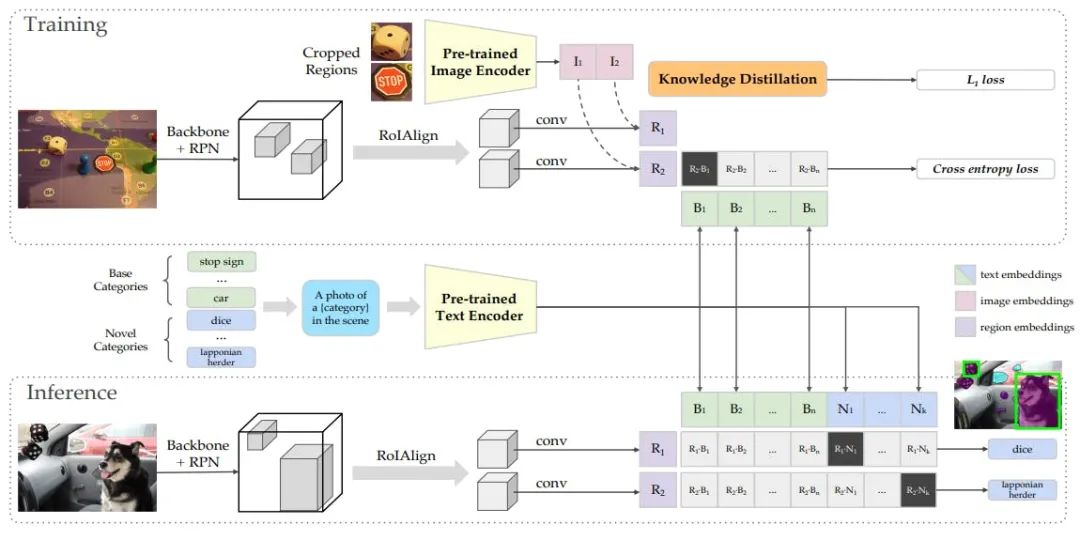
技术架构不同
- VLM的架构:双流融合
VLM通常采用“视觉编码器 + 文本编码器 + 跨模态融合模块”的双流架构。- 视觉编码器(如ViT)负责从图像中提取视觉特征。
- 文本编码器负责处理文本信息。
- 融合模块(如简单的投影层或注意力机制)将两种特征对齐,让它们能够相互理解。
- MLLM的架构:LLM为核心
MLLM的架构更为复杂和统一,其核心是大型语言模型(LLM)。- 多模态编码器:除了视觉编码器,还可能包含音频、视频等编码器。
- 高级连接器 (Adapter):这是一个关键组件,它将各种模态的特征(如图像特征)映射到LLM的语义空间中,让LLM能像理解文字一样理解图像。
- 大型语言模型 (LLM):作为“通用推理引擎”,LLM占据了模型参数的绝大部分(通常超过80%),负责整合所有信息并进行复杂的逻辑推理和内容生成。
应用场景不同
- VLM的应用:专注单轮图文任务
VLM擅长处理单一的、与图像直接相关的任务,交互通常是单轮的。- 图像描述:为一张图片生成一段文字描述。
- 视觉问答 (VQA):回答关于图片内容的简单问题(如“图里有几只猫?”)。
- 图文检索:根据文字描述找到对应的图片。
- MLLM的应用:胜任复杂多轮交互
MLLM能处理需要深度理解和推理的复杂任务,并支持多轮对话。- 多轮对话:可以围绕一张图片进行连续提问和解答,理解上下文。
- 复杂推理:例如,分析一张复杂的图表,并结合文字问题给出推理过程。GPT-4o等模型甚至能进行无OCR的数学公式推理。
- 多模态融合:在自动驾驶场景中,同时处理摄像头画面、雷达数据和导航指令,做出驾驶决策。
总结对比
为了让你更清晰地理解,以下是两者的核心差异总结:
表格
| 对比维度 | 视觉语言模型 (VLM) | 多模态大模型 (MLLM) |
|---|---|---|
| 核心定位 | “图文专家” | “全能大脑” |
| 处理模态 | 主要是图像+文本 | ≥3种模态 (图文音视频等) |
| 技术核心 | 视觉与文本编码器的双流融合 | 以大型语言模型(LLM)为核心的统一架构 |
| 任务类型 | 单轮、直接的图文任务 | 多轮、需要复杂推理的交互任务 |
| 典型应用 | 图像描述、视觉问答 | 智能助手、自动驾驶、复杂内容分析 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...