
Qwen2.5-VL 是阿里巴巴通义千问团队发布的旗舰级视觉语言模型(Vision-Language Model),它在多模态理解、精确目标定位、文档解析和长视频理解等方面实现了显著的技术飞跃。
核心技术创新
Qwen2.5-VL的强大能力源于其多项核心技术创新,使其在处理复杂视觉任务时表现卓越。
- 动态分辨率处理 (Dynamic Resolution)
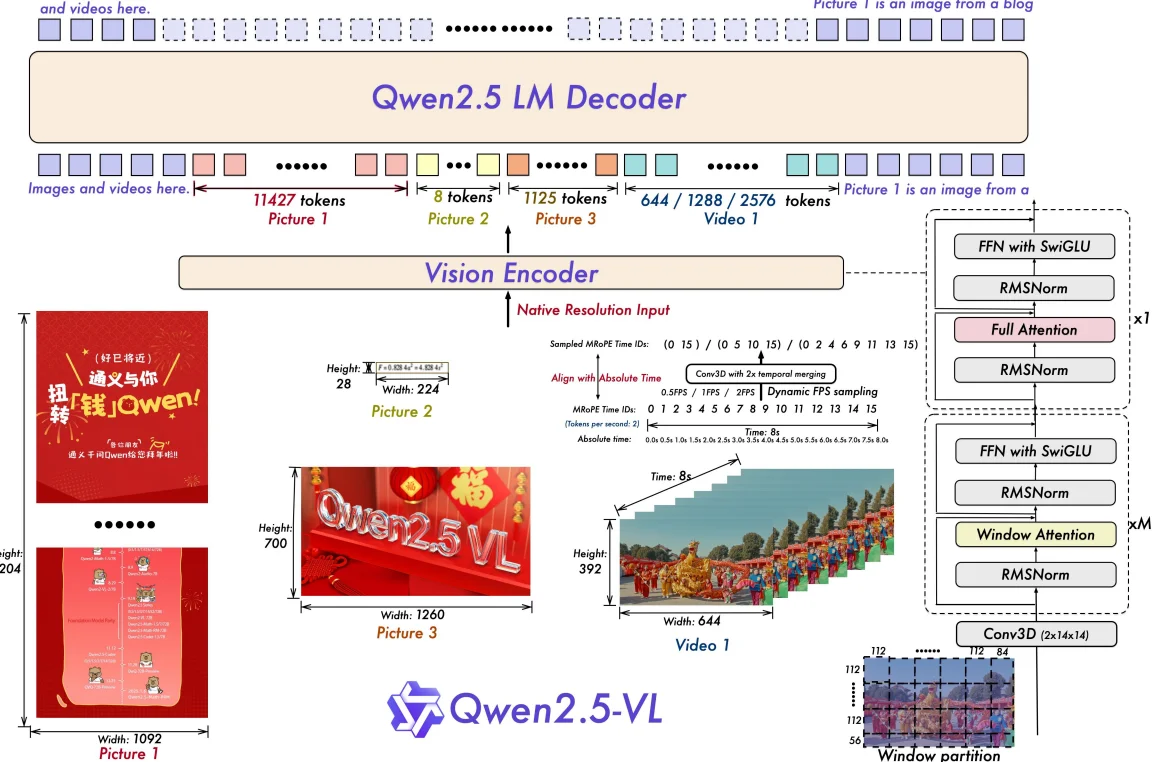
模型能够以原生分辨率处理任意尺寸的图像和长达数小时的视频,无需强制缩放或裁剪。这得益于其从头训练的动态分辨率视觉编码器(ViT),能有效避免因图像变形导致的信息损失,尤其擅长处理文档、图表和UI界面等对尺寸敏感的内容。 - 绝对时间编码 (Absolute Time Encoding)
针对视频理解,Qwen2.5-VL 引入了与绝对时间对齐的多模态旋转位置编码(MRoPE)。这一机制让模型能够精确感知视频中的时间动态,实现秒级精度的事件定位,从而深入理解长视频的内容脉络。 - 高效的窗口注意力 (Window Attention)
在视觉编码器中,模型创新性地引入了窗口注意力机制。该机制将计算复杂度从 O(n²) 降低到 O(n),在大幅减少计算开销的同时,依然保持了处理高分辨率图像的能力。
模型架构解析
Qwen2.5-VL采用了经典的“编码器-融合器-解码器”架构,由三个核心组件高效协同工作:
- 视觉编码器 (Vision Encoder)
基于支持动态分辨率和窗口注意力的ViT架构,负责从图像或视频中提取高质量的视觉特征。 - 跨模态融合器 (MLP Vision-Language Merger)
这是一个多层感知机(MLP)模块,负责将视觉特征压缩并投影到与语言模型对齐的语义空间,实现视觉与文本信息的高效融合。 - 语言模型 (LLM Decoder)
基于强大的Qwen2.5大语言模型,负责接收融合后的多模态信息,并进行深度的逻辑推理和文本生成。
模型家族与规格
Qwen2.5-VL 提供了多种参数规模的版本,以满足从边缘设备到高性能计算的不同场景需求。所有版本均完整继承了 Qwen2.5 LLM 的语言能力。
表格
| 模型名称 | 参数量 | 核心定位 | 开源协议 |
|---|---|---|---|
| Qwen2.5-VL-3B | 3.75B | 边缘 AI / 移动端部署 | Apache 2.0 |
| Qwen2.5-VL-7B | 8.29B | 通用推理 | Apache 2.0 |
| Qwen2.5-VL-32B | ~32B | 强化学习优化版 | Apache 2.0 |
| Qwen2.5-VL-72B | 73.4B | 旗舰级,对标 GPT-4o | 自定义 |
主要应用场景
凭借其强大的多模态能力,Qwen2.5-VL在多个领域展现出广泛的应用价值:
- 深度文档解析:能够精准理解和处理多语言、多格式的文档,包括手写体、复杂表格、图表和公式,并提取结构化数据。
- 精确目标定位:支持使用边界框(Bounding Box)或坐标点(Point)对图像中的物体进行精确定位。
- 长视频理解:能够分析长达数小时的视频内容,并以秒级精度定位和总结关键事件。
- 智能体交互 (Agent):可以作为视觉智能体,在计算机或移动设备上执行复杂的交互任务,例如根据屏幕截图生成前端代码。
性能与效率
Qwen2.5-VL不仅在能力上表现突出,在推理效率上也进行了深度优化。例如,Qwen2.5-VL-7B-Instruct 版本在RTX 4090显卡上,通过硬件特异性优化,推理速度相比同类模型有显著提升,处理一张1024×768分辨率的图像平均仅需3-5秒。同时,其显存管理也十分高效,常规任务下占用控制在8-12GB,为在消费级硬件上部署专业AI能力提供了可能。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...