
Audio Flamingo Next (AF-Next) 是由 NVIDIA(英伟达)与马里兰大学研究团队在2026年4月联合发布的最新开源大型音频语言模型(LALM)。
它是Audio Flamingo系列中能力最强的版本,专门旨在解决长音频理解与复杂推理的难题。
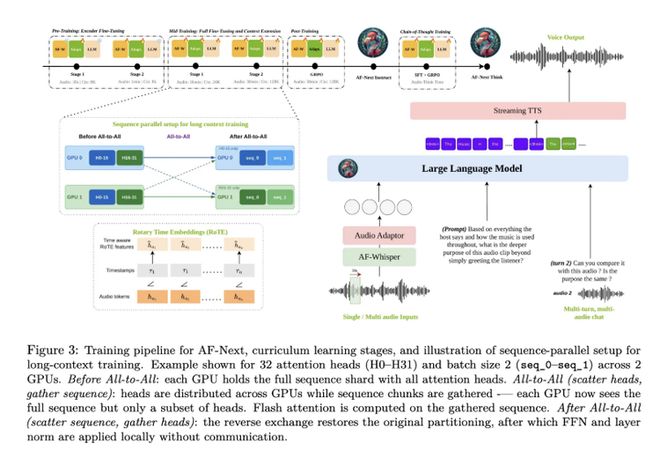
核心能力与技术突破
- 时序音频思维链 (Temporal Audio Chain-of-Thought)
这是该模型最大的技术创新。团队提出了一种将推理步骤显式锚定到音频时间戳的方法。这意味着模型不仅能回答“音频里说了什么”,还能精确指出“证据出现在第几分钟”,显著提升了长音频任务中的证据聚合能力与准确性。 - 基于 Qwen-2.5-7B 构建
AF-Next 采用了阿里巴巴的Qwen-2.5-7B作为其主干大语言模型。这赋予了它强大的语言理解和逻辑推理底座,使其能够进行高质量的音频内容分析。
开源版本与变体
此次开源非常全面,包含了三个针对不同任务优化的变体:
表格
| 模型变体 | 核心用途 |
|---|---|
| AF-Next-Instruct | 针对通用音频问答任务进行了指令微调。 |
| AF-Next-Think | 专注于多步推理,利用思维链技术解决复杂问题。 |
| AF-Next-Captioner | 专门用于生成高质量的音频描述文本。 |
性能表现
根据实验数据,AF-Next 在20项基准测试中大幅超越了同级别的开源模型。特别是在MMAU-Pro等高难度的音频理解基准测试上,它的表现甚至优于Gemini 2.5 Pro,展现了卓越的泛化能力。
与前代 (AF3) 的关系
Audio Flamingo系列此前已发布了AF3版本(基于Qwen-2.5-7B,具备语音交互和流式TTS能力)。AF-Next 作为该系列的最新进化,在保持强大基座的同时,重点攻克了长上下文和推理可解释性(通过时间戳锚定)这两个音频AI领域的深水区难题。
Audio Flamingo Next的项目地址
- 项目官网:https://afnext-umd-nvidia.github.io/
- GitHub仓库:https://github.com/NVIDIA/audio-flamingo
- HuggingFace模型库:https://huggingface.co/nvidia/audio-flamingo-next-hf
- arXiv技术论文:https://arxiv.org/pdf/2604.10905
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...