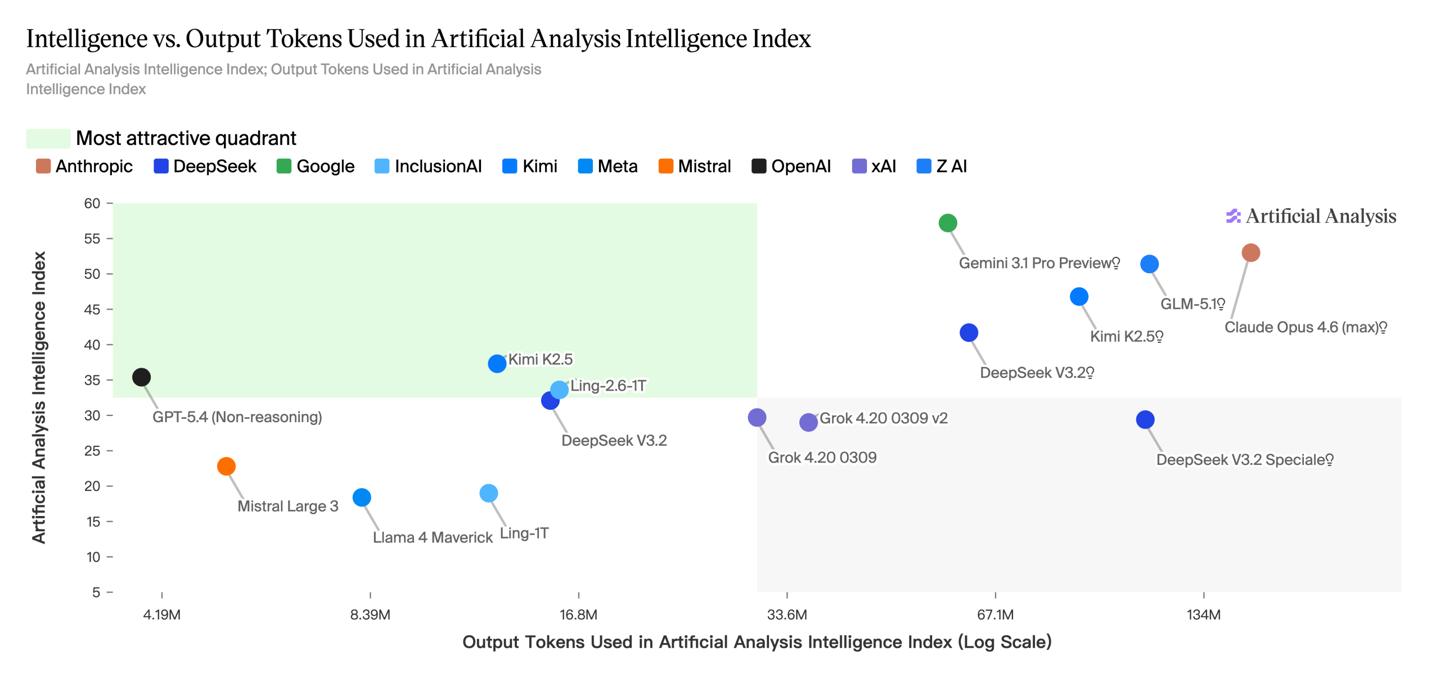
Ling-2.6-1T是蚂蚁集团百灵大模型团队开源的一款万亿参数级旗舰大模型。它最大的特点是不盲目追求“慢思考”式的长推理链,而是独创了“快思考”机制,旨在以极低的计算成本实现高效的复杂任务执行。其综合智能水平已对标 GPT-5.4(非推理模式)。
Ling-2.6-1T核心亮点
Ling-2.6-1T的设计哲学是“高智效比”,即用最少的资源消耗解决最复杂的问题。
- 极速思考 (Fast Thinking):
模型在后训练阶段引入了“上下文流程冗余抑制优化”。简单来说,它能自动剔除思维链中啰嗦、无用的废话,直接输出关键结果。 - 成本极低:
在真实任务中,它的 Token 消耗量仅为同级别模型的 1/4。例如,在Artificial Analysis的完整评测中,它仅消耗 16M tokens 就完成了全流程,大幅降低了推理成本。 - 混合架构:
采用了MoE (混合专家)架构,总参数达1万亿,但每次推理仅激活500亿-630亿参数。同时结合了MLA 与Linear Attention技术,既保证了智能上限,又提升了推理速度。
Ling-2.6-1T硬核参数与能力
表格
| 特性 | 详细参数/表现 |
|---|---|
| 参数规模 | 1万亿 (1T) 总参数,MoE 架构 |
| 上下文窗口 | 支持 262K 超长上下文(约数十万字) |
| 代码能力 | SWE-bench Verified 解决率达 72.2% (SOTA级) |
| 推理能力 | AIME26 测试中领先一众无思考机制模型 |
| 智能体能力 | 在 TAU2-Bench、BFCL-V4 等工具调用榜单中表现顶尖 |
Ling-2.6-1T工程化与部署
Ling-2.6-1T非常注重落地实用性,不仅是一个“聊天机器人”,更是一个能干活的生产力工具:
- 深度适配框架:原生兼容OpenCode、Claude Code等主流智能体开发框架,也支持SGLang 和vLLM推理框架。
- 部署门槛降低:官方提供了8卡张量并行部署示例,支持 FP8 和 BF16 精度,让普通企业甚至开发者也能在本地部署万亿级模型。
- 实战表现:在蚂蚁内部,它已被用于日志分析、代码自动修复等复杂运维场景,能稳定处理包含 10 个以上步骤的复合任务。
Ling-2.6-1T的应用场景
- Agent 自动化工作流:承担长程自主规划、高频工具调用与多步骤业务流编排,在复杂约束环境下稳定推进执行。
- 软件工程开发:胜任全栈代码生成、缺陷修复、复杂 Slide 开发及游戏原型构建等人机协作编程任务。
- 前端与设计原型:将工业风、拟物化、数据看板等风格指令快速转化为可交互、可迭代的 Landing Page 与产品原型。
- 专业内容创作:完成广告文案、品牌叙事、跨语言内容及 Subreddit 风格帖文等多样化写作,保持风格稳定与表达自然。
- 企业知识管理:从海量文档中精准提纯关键知识点,理清复杂实体关系,作为高精度记忆层接入长期业务系统。
Ling-2.6-1T的项目地址
- HuggingFace模型库:https://huggingface.co/inclusionAI/Ling-2.6-1T

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...