
混合专家(Mixture of Experts, MoE)模型是当前大模型领域最核心的架构创新之一。它通过一种“分而治之”的策略,成功破解了模型规模与计算成本之间的矛盾,让打造性能更强、效率更高的AI成为可能。
简单来说,MoE模型就像一个由“智能调度员”和一群“领域专家”组成的团队,能够高效协同地处理复杂任务。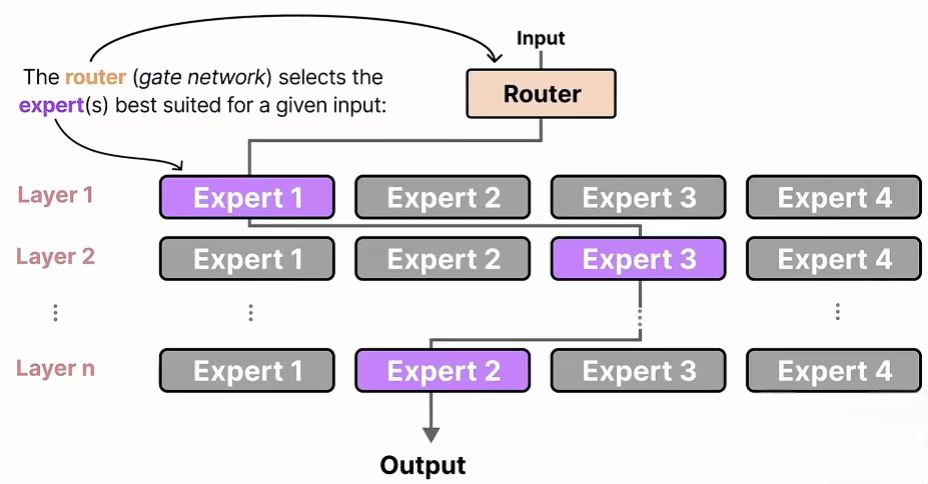
核心思想:术业有专攻
MoE模型的核心思想源于“条件计算”(Conditional Computation)。与传统“通才”模型不同,MoE不追求用一个庞大的网络处理所有信息,而是将任务分解,让不同的子网络(专家)专注于自己擅长的领域。
这种设计带来了“高参数、低计算”的独特优势。模型的总参数量可以非常庞大(例如万亿级别),但在处理任何一个具体输入时,只激活其中一小部分参数,从而在保持高性能的同时,大幅降低了计算开销和推理延迟。
️ 工作原理:智能调度与专家协作
MoE模型的工作流程可以清晰地分为三个步骤,我们可以用一个生动的比喻来理解:
- 门控网络(Gating Network):智能调度员
当输入数据(如一个句子或一张图片)进入模型时,首先会经过一个轻量级的“门控网络”。它的作用就像一个分诊护士或调度中心,快速分析输入内容的特点,并判断这个任务应该交给哪位或哪几位专家处理。 - 专家网络(Expert Networks):领域专家
模型中包含多个独立的“专家网络”,每个专家都是一个专门处理特定类型信息的子网络。例如,有的专家可能擅长处理语法结构,有的擅长理解代码,有的则对数学推理更在行。根据门控网络的决策,只有少数最相关的专家会被“激活”并开始工作。 - 加权输出(Weighted Output):结果汇总
被激活的专家们各自给出处理结果,最终由门控网络根据权重将这些结果进行整合,形成模型的最终输出。
这种“输入 → 门控打分 → 专家计算 → 结果聚合”的流程,确保了模型既能利用庞大的知识库,又能保持高效的运行速度。
MoE模型 vs. 传统稠密模型
为了更清晰地理解MoE的优势,我们可以将其与传统的稠密(Dense)模型进行对比:
表格
| 特性 | MoE模型 (混合专家) | 稠密模型 (Dense Model) |
|---|---|---|
| 参数利用 | 动态稀疏激活,每次仅调用部分参数,效率高 | 全参数激活,无论任务难易都调用全部参数,计算冗余 |
| 扩展性 | 易于扩展,通过增加专家数量即可提升模型容量,计算成本增加不多 | 扩展成本高,增加模型深度或宽度会导致计算成本急剧上升 |
| 适用场景 | 多任务、异构数据,如需要同时处理代码、文本、图像的复杂场景 | 单一任务、同构数据,任务相对固定和单一 |
| 训练难度 | 更复杂,需要解决专家负载均衡、通信瓶颈等工程挑战 | 相对简单,优化路径较为成熟和直接 |
优势与应用
MoE架构的兴起,主要是因为它解决了大模型发展中的几个关键痛点:
- 突破性能瓶颈:遵循“规模定律”(Scaling Law),模型越大性能越强。MoE允许模型在参数规模上实现数量级的增长(如达到万亿级别),从而获得更强的智能涌现和泛化能力,而不会让训练和推理成本高到无法承受。
- 提升计算效率:通过稀疏激活,MoE模型在推理时仅需消耗少量计算资源。例如,一个万亿参数的MoE模型,单次推理可能只激活约200亿参数,极大地节省了算力。
- 增强任务特异性:不同专家可以专注于不同领域,使得模型在处理代码生成、数学推理、多语言翻译等细分任务时更加精准。
目前,MoE已成为众多顶尖大模型的选择,例如:
- Google的Switch Transformer、GLaM
- Mistral AI 的 Mixtral
- OpenAI的GPT-4
- 阿里巴巴的 Qwen 系列(如Qwen1.5-MoE、Qwen3.6-35B-A3B)
- DeepSeek系列模型
️ 挑战与未来
尽管优势明显,MoE模型也面临着一些工程化挑战:
- 训练复杂度高:需要设计复杂的机制来确保所有专家都能被均衡地训练,避免出现“强者恒强,弱者闲置”的负载不均衡问题。
- 通信瓶颈:在分布式训练中,不同设备上的专家之间需要进行频繁的数据交换,这对通信带宽和效率提出了很高要求。
- 推理延迟:动态路由机制可能导致推理过程的不确定性,需要通过专家缓存、批处理路由等技术进行优化。
总而言之,混合专家(MoE)模型通过“专家团队+智能调度”的创新架构,为大模型的持续发展和落地应用提供了一条高效、经济的路径,是当前AI技术演进的重要方向。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...