
LingBot-Map是由蚂蚁灵波科技正式开源的一款流式三维重建模型。
它被誉为机器人领域的“白眼”(源自《火影忍者》中的瞳术,意指360度无死角的视觉感知),其核心突破在于仅使用一颗普通RGB摄像头,就能让机器人在移动过程中实时完成高精度的三维空间重建和定位。
这项技术的开源,补齐了具身智能“感知-建模-模拟-控制”全链路中的关键拼图。
核心亮点:单目摄像头的“逆袭”
传统的三维重建或SLAM(即时定位与地图构建)方案通常依赖昂贵的激光雷达、双目相机或RGB-D相机。LingBot-Map 打破了这一硬件门槛:
- 极简硬件:仅需单目普通RGB摄像头即可工作,大幅降低了机器人、无人机或AR设备的硬件成本。
- 流式处理:不同于“先录视频、后处理”的离线模式,LingBot-Map支持边看边建图。它能实时处理视频流,一边接收画面一边输出定位与三维结构。
- 长时稳定:解决了长视频处理中的“灾难性遗忘”问题,支持10,000+帧的长序列连续推理,且精度几乎不衰减。
技术原理:几何上下文注意力机制
LingBot-Map的核心创新在于其架构设计,旨在平衡几何精度、时序一致性与运行效率:
- 几何上下文注意力机制(GCA):这是模型的大脑。它借鉴了经典SLAM系统对空间信息分层管理的思路,但通过深度学习模型统一学习。GCA 能够高效组织和利用跨帧的几何信息,在保留关键历史数据的同时,剔除冗余计算。
- 纯自回归建模:基于几何上下文Transformer,模型在不依赖未来帧信息的前提下,逐帧处理当前及历史画面,实现了真正的实时流式重建。
- 64帧窗口设计:通过巧妙的窗口设计,模型将推理速度从全历史缓存方案的3.12 FPS提升至 约 20 FPS,同时将显存占用从36GB压缩至13.28 GB,使得普通消费级显卡也能流畅部署。
性能表现:超越离线方案
在多个权威基准测试中,LingBot-Map的表现不仅领先于同类流式方法,甚至超越了许多计算量巨大的离线方案:
表格
| 评测基准 | 关键指标 | 表现详情 |
|---|---|---|
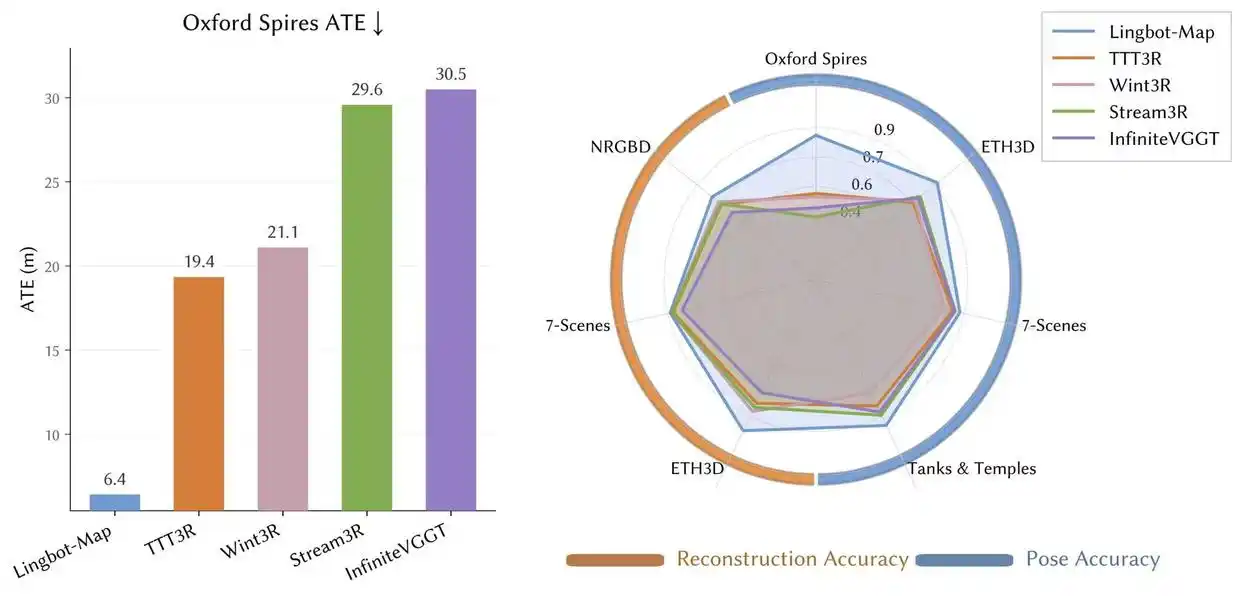
| Oxford Spires | 绝对轨迹误差 (ATE) | 6.42米。精度较此前最优流式方法提升约 2.8倍,优于离线方法 DA3 (12.87米)。 |
| ETH3D | 重建 F1 分数 | 85.70。较第二名提升超过 8%,场景还原精度大幅提升。 |
| 推理速度 | 实时帧率 (FPS) | 稳定在 20 FPS 左右,满足机器人实时作业需求。 |
应用场景与生态意义
LingBot-Map的开源不仅仅是发布了一个模型,它标志着具身智能技术栈的进一步完善。
- 机器人导航与作业:仓库巡检、家庭服务机器人不再需要昂贵的激光雷达,仅靠摄像头就能实现低成本、大规模部署的精准导航和避障。
- AR/VR 体验升级:在增强现实中,虚拟物体可以更稳定、零延迟地叠加在真实桌面上,解决“漂移”问题。
- 自动驾驶与无人机:为纯视觉自动驾驶方案提供了更强的时空理解能力,支持城市级大场景的实时建模。
🔗 开源资源
目前,LingBot-Map的模型权重、代码及相关文档已全面开源,开发者可以通过以下平台获取:
- 项目官网:https://technology.robbyant.com/lingbot-map
- GitHub仓库:https://github.com/Robbyant/lingbot-map
- HuggingFace模型库:https://huggingface.co/robbyant/lingbot-map
- arXiv技术论文:https://arxiv.org/pdf/2604.14141
LingBot-Map与之前开源的LingBot-Depth(空间感知)、LingBot-VLA(具身大模型)、LingBot-World(世界模型)共同构成了蚂蚁灵波完整的具身智能技术闭环。
如何使用LingBot-Map
- 环境准备:确保本地环境配备 NVIDIA GPU(推荐显存 ≥ 12GB),安装 Python 3.8+、PyTorch 2.0+ 及 CUDA 工具链。系统需支持 Linux 或 Windows WSL2 环境以兼容依赖库编译。
- 安装部署:访问 GitHub 仓库
https://github.com/Robbyant/lingbot-map克隆代码,进入项目目录后通过 pip 安装依赖:pip install -r requirements.txt。环境会自动安装 DINO backbone、Transformer 架构及三维可视化所需的 Open3D 等库。 - 模型获取:从 HuggingFace (
robbyant/lingbot-map) 或 ModelScope 下载预训练权重,放置于项目checkpoints/目录。模型包含 Geometric Context Attention (GCA) 核心网络及 Camera/Depth 预测头。 - 运行推理:
- 离线视频模式:输入单目 RGB 视频文件,模型逐帧提取 DINO 特征,经 Frame Attention 与 GCA 层处理,输出相机位姿轨迹(Trajectory)和深度图(Depth),最后融合为三维点云地图。
- 实时摄像头模式:连接普通 USB 摄像头,设置输入流分辨率为 640×480 或 1280×720,模型用 ~20 FPS 实时推理,持续输出当前相机位姿并增量式更新场景三维结构。
- 结果输出:重建结果包含相机轨迹文件(标准坐标格式)和带尺度的稠密点云,可通过可视化脚本查看三维重建效果。长序列推理时,GCA 机制会自动管理内存,支持 10,000+ 帧连续处理而无需重启。
- 高级配置:调整
config.yaml中的anchor_context和trajectory_memory参数可平衡精度与计算开销;针对大场景可启用局部窗口优化(Local Pose-Reference Window)提升长轨迹稳定性。具体 API 调用示例与参数说明参考 GitHub 仓库的README.md与demo.py。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...