StepAudio 2.5 ASR是阶跃星辰正式发布的新一代自动语音识别模型。该模型的核心突破在于率先将大语言模型的推理加速技术引入语音识别领域,通过架构创新,在大幅提升转写精度的同时,实现了推理速度与成本的颠覆性优化。

StepAudio 2.5 ASR核心突破
StepAudio 2.5 ASR采用了首创的ASR+MTP-5深度融合架构。它将此前应用于大语言模型(如 Step 3.5 Flash)的“多Token预测”(MTP)技术移植到了语音识别中。
- 打破传统瓶颈:传统语音识别模型受限于“自回归”机制,必须逐个识别并输出Token,效率较低。
- 并行处理优势:新架构允许模型一次性预测多个候选Token,并通过并行验证机制快速确认结果,将串行的处理过程变为并行,从而打破了效率瓶颈。
StepAudio 2.5 ASR主要亮点
1. 速度与成本的颠覆性提升
得益于新架构,模型在效率和成本上实现了巨大飞跃。
- 推理速度:提升400%,峰值速度达到500tokens/s。
- 处理时延:降低60%。
- 推理成本:直降80%。
- 实际体验:一段5分钟左右的音视频,几乎可以实现“一眨眼”的即时转写。
2. 根治长音频“失忆”难题
针对行业内普遍存在的长音频处理痛点,StepAudio 2.5 ASR提供了端到端的解决方案。
- 传统方案缺陷:通常采用“切片-转写-拼接”的方式处理长音频,容易导致上下文信息割裂,模型在转写后半段时可能“忘记”开头的背景信息。
- 新方案优势:模型复用了大语言模型原生的32K上下文窗口,支持一次性完整读入最长30分钟的连续音频,无需分段。在满载测试中,模型未出现随时间推移精度衰减的情况。
3. 业界领先的转写精度
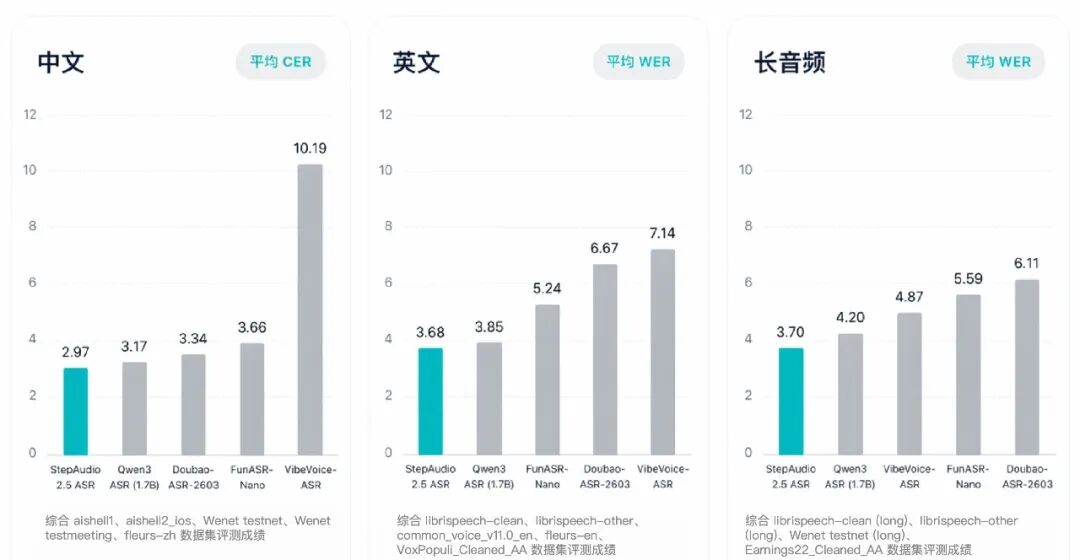
在大幅提升速度的同时,模型的转写精度也达到了行业顶尖(SOTA)水准。
- 在覆盖新闻播报、会议访谈及强噪声环境的多个中英文权威测试集上,其综合转写精度表现优异。
- 在LibriSpeech等10个权威开源测试集上的综合错误率均低于竞品。
StepAudio 2.5 ASR的应用场景
- 会议纪要与访谈转写:端到端转写长时段会议、访谈录音,保持术语一致性与上下文连贯,无需切片拼接。
- 字幕生成与媒资预处理:快速生成视频字幕,支持OGG、mp3、wav、PCM等多格式音频批量处理。
- 长音频内容归档:适用于播客、讲座、庭审等30分钟级音频的完整转写与检索入库。
- 实时语音质检:凭借低时延与高吞吐特性,适用于客服通话质检与内容合规审查场景。
- 后端系统接入:识别结果可直接接入检索、摘要、质检或归档链路,满足工业级术语一致性与稳定性要求。
StepAudio 2.5 ASR的项目地址
- 技术论文:https://stepaudiollm.github.io/step-audio-2.5-asr/model-card/
- 在线体验Demo:https://stepaudiollm.github.io/step-audio-2.5-asr/
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...