DeepSeek-V4是深度求索(DeepSeek)正式发布的新一代大模型系列预览版,标志着国产大模型在性能、成本和自主可控生态上迈出了关键一步。它并非单一模型,而是包含两个版本,并以其百万级上下文、极致性价比和对国产算力的全面适配而备受瞩目。
DeepSeek-V4双版本发布
DeepSeek-V4 系列分为两个版本,以满足不同场景的需求:
- DeepSeek-V4-Pro (旗舰版)
- DeepSeek-V4-Flash (轻量版)
- 定位:轻量高效的经济之选,适合对成本和速度要求高的规模化场景。
- 参数:总参数量为2840亿,每次推理激活约130亿参数。
- 能力:推理能力接近Pro版,但API价格更低,响应更快捷。
DeepSeek-V4核心亮点
1. 百万级上下文标配
两个版本均支持 100万 (1M) Token 的超长上下文窗口,并将其作为所有官方服务的标准配置。这意味着模型可以一次性处理相当于《三体》三部曲体量的完整文本。这得益于其开创的混合注意力机制,大幅降低了长文本处理的计算量和显存需求,处理1M上下文时,计算量仅为前代模型的27%。
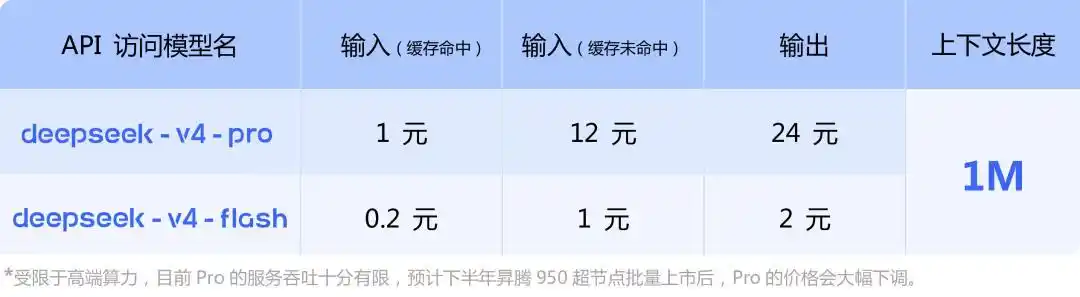
2. 极致性价比
DeepSeek-V4 延续了“价格屠夫”的风格,定价极具竞争力。
表格
| 模型版本 | 输入价格 (缓存命中/未命中) | 输出价格 |
|---|---|---|
| V4-Flash | 0.2元 / 1元 (每百万词元) | 2元 (每百万词元) |
| V4-Pro | 1元 / 12元 (每百万词元) | 24元 (每百万词元) |
这是DeepSeek-V4最具战略意义的突破。它实现了与华为昇腾、寒武纪等国产芯片的深度适配,不再依赖英伟达的CUDA生态。
- 华为昇腾全系列已完成适配,预计下半年昇腾950超节点批量上市后,Pro版本的价格有望大幅下调。
- 这一举措标志着国产AI产业在“自主可控”的道路上,从“能用”迈向了“好用”的商业化新阶段。
DeepSeek-V4的性能体现
- 知识能力
- 世界知识领先开源:SimpleQA-Verified达57.9%,超越所有已评测开源模型20个百分点,仅稍逊于Gemini-3.1-Pro(75.6%)。
- 中文知识突出:Chinese-SimpleQA达84.4%,大幅领先K2.6(75.9%)与GLM-5.1(75.0%)。
- 教育知识接近前沿:MMLU-Pro 87.5%、GPQA Diamond 90.1%,与GPT-5.4持平,略低于Gemini-3.1-Pro。
- 推理与代码能力
- 数学竞赛比肩闭源:HMMT 2026 Feb达95.2%,IMOAnswerBench达89.8%,超越K2.6与GLM-5.1,接近GPT-5.4与Opus-4.6。
- 代码竞赛首次开源追平闭源:Codeforces Rating达3206,与GPT-5.4(3168)相当,当前排名人类选手第23位。
- 高难度推理突破:Apex Shortlist达90.2%,超越GPT-5.4(78.1%)与Opus-4.6(85.9%);LiveCodeBench达93.5%,领先所有对比模型。
- Agent能力
- 软件工程接近顶级闭源:SWE Verified达80.6%,与Opus-4.6(80.8%)基本持平;SWE Pro 55.4%、SWE Multilingual 76.2%。
- 终端操作领先开源:Terminal Bench 2.0达67.9%,超越K2.6(66.7%)、GLM-5.1(63.5%)与Opus-4.6(65.4%)。
- 工具调用泛化优秀:MCPAtlas Public 73.6%、Toolathlon 51.8%,在包含广泛工具和MCP服务的评测中表现突出。
- 长上下文能力
- 百万上下文检索强劲:MRCR 1M达83.5%,超越Gemini-3.1-Pro(76.3%);128K内检索性能高度稳定,1M时仍保持较强能力。
- 真实场景长文档理解:CorpusQA 1M达62.0%,优于Gemini-3.1-Pro(53.8%)。
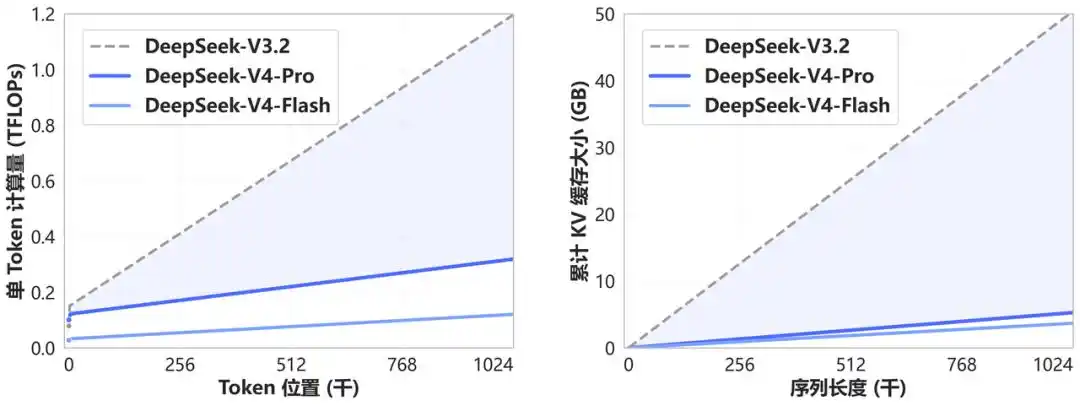
- 效率表现
- 计算量断崖式下降:1M上下文下,V4-Pro单Token推理FLOPs仅为V3.2的27%,V4-Flash仅为10%。
- KV缓存大幅压缩:1M上下文下,V4-Pro累计KV缓存为V3.2的10%,V4-Flash仅为7%。
- 路由专家FP4量化:专家权重采用FP4存储,未来硬件上理论可再提升1/3效率。
DeepSeek-V4的项目地址
- HuggingFace模型库:https://huggingface.co/collections/deepseek-ai/deepseek-v4
- 技术论文:https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...