
稠密模型,全称为稠密架构大语言模型,是当前大模型家族中与混合专家模型相对的一种主流架构。
它的核心特征是:在处理每一个输入时,都会激活并使用模型的全部参数进行计算。你可以把它想象成一个“全能型选手”,无论面对什么问题,都会调动自己所有的知识和能力来应对。
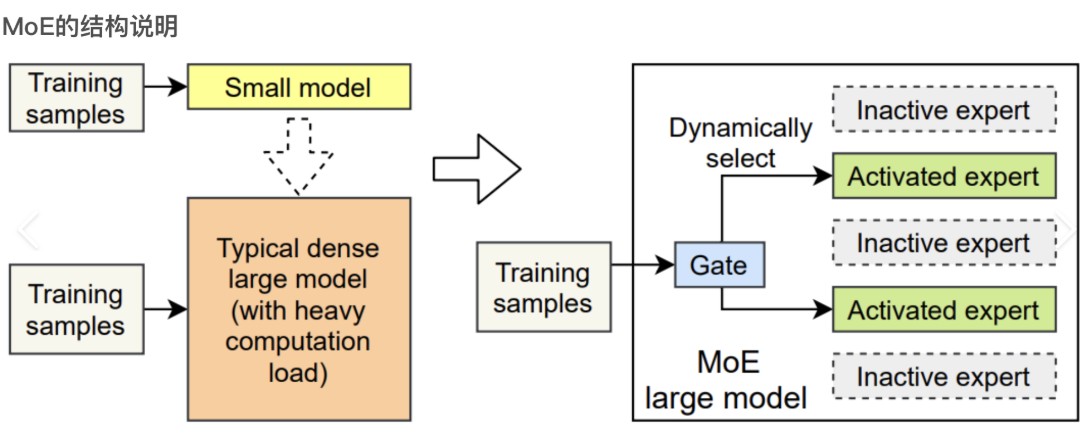
稠密模型核心原理
与混合专家模型(MoE)那种“按需分配”的模式不同,稠密模型的工作方式非常直接:
- 统一处理:对于任何一个任务,模型的所有神经网络层和参数都会被激活并参与计算。
- 稳定可靠:由于每次推理的路径和计算量都是固定的,其行为表现和性能输出也更为稳定。
与混合专家模型(MoE)的对比
理解稠密模型最好的方式就是与混合专家模型(MoE)进行对比。MoE架构更像一个“专家团队”,遇到不同问题时,只会路由(激活)少数相关的“专家”参数来处理,从而实现用更小的计算成本获得高性能。
表格
| 特性 | 稠密模型 | 混合专家模型 |
|---|---|---|
| 参数激活 | 全部激活,处理每个任务都使用所有参数。 | 稀疏激活,仅激活一小部分相关参数(专家)。 |
| 部署难度 | 相对简单,推理过程直接,无需复杂的路由机制。 | 相对复杂,需要高效的专家路由和负载均衡策略。 |
| 性能特点 | 性能稳定,在小到中等参数规模下表现优异。 | 能以更低的推理成本实现超大规模模型的性能。 |
| 典型代表 | Qwen3.6-27B, Qwen3-32B | Qwen3-235B-A22B, Qwen3-30B-A3B |
典型代表:Qwen3.6-27B
以阿里最新开源的Qwen3.6-27B模型为例,它就是一个典型的稠密模型,并展现了该架构的独特优势:
- 旗舰级能力:尽管只有270亿参数,但它在编程、多模态理解等复杂任务上的表现,全面超越了参数规模大15倍的上一代混合专家模型。这体现了稠密模型“以小博大”的潜力。
- 部署友好:由于无需混合专家模型那种复杂的路由机制,Qwen3.6-27B的本地化部署门槛更低,推理效率更高,对开发者非常友好。
最后想说,稠密模型凭借其稳定、直接、易于部署的特点,依然是当前大模型应用,尤其是在中等参数规模下的主力架构。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...