
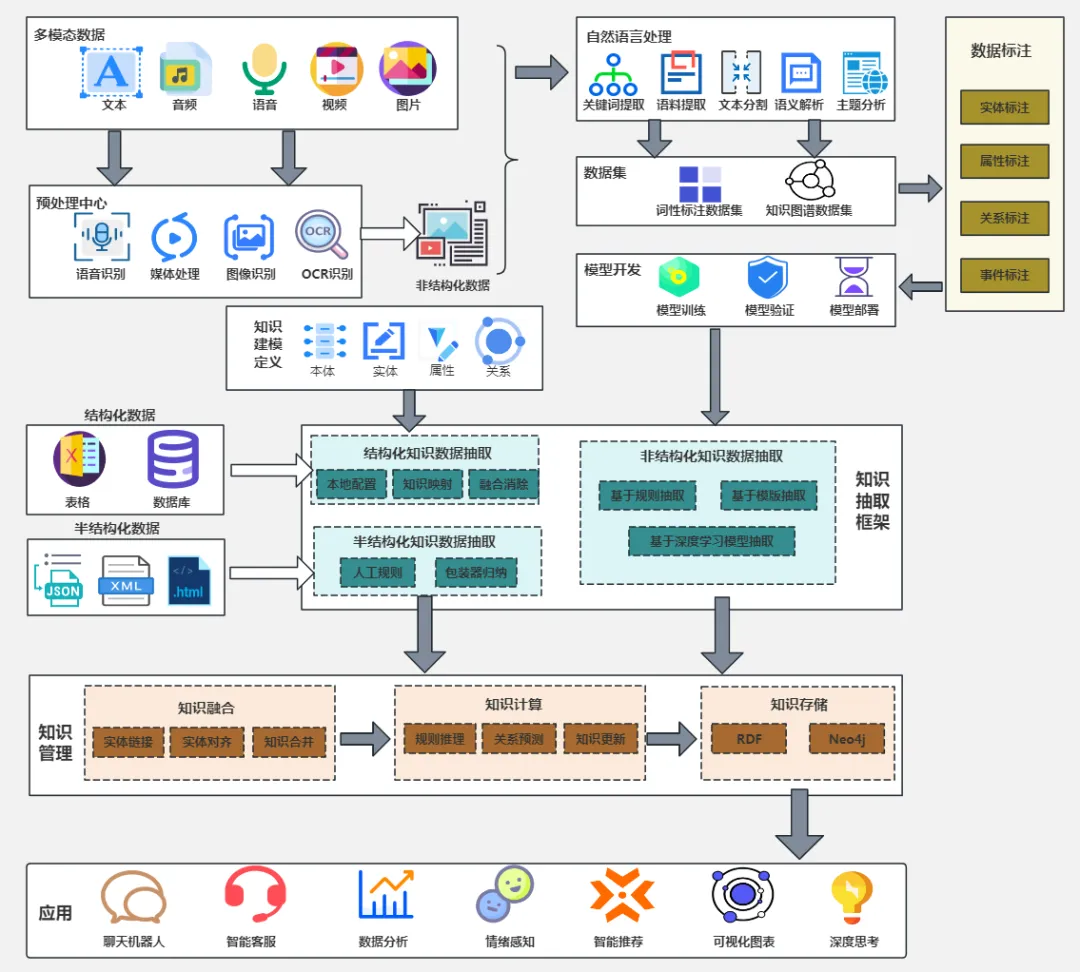
模型架构(Model Architecture)通俗来说,就是人工智能模型的“设计蓝图”或“骨架结构”。
它定义了模型内部的组织方式:数据如何输入、经过哪些处理层、层与层之间如何连接、以及最终如何输出结果。
模型架构核心概念
如果把训练好的人工智能模型比作一栋“建成的大楼”,那么模型架构就是这栋大楼的“建筑设计图”。
- 架构(Architecture):决定了这栋楼是摩天大楼(如Transformer)、是四合院(如CNN)还是长廊(如RNN)。它规定了有多少层、每层多高、楼梯怎么修(连接方式)、承重墙在哪里(核心机制)。
- 模型(Model):是根据这张图纸,用钢筋水泥(数据)浇筑完成后,真正能住人的实体。
- 权重(Weights):是建筑内部的具体装修和参数(比如墙体的坚固程度),是在训练过程中学到的,但必须在架构规定的框架内进行调整。
模型架构包含哪些要素?
当我们讨论一个模型的架构时,通常是在讨论以下几个技术细节:
- 层的类型与堆叠:
- 模型由哪些“积木”组成?是卷积层(擅长看图)、注意力层(擅长理解上下文)还是全连接层(擅长做决策)?
- 这些层堆了多少层?(例如:ResNet-50 代表有50层深)。
- 连接方式(数据流向):
- 数据是单向流动的(前馈网络),还是有反馈回路的(循环神经网络)?
- 是否有“跳跃连接”(让信息跳过某些层直接传递,解决深层网络难训练的问题)?
- 核心机制:
- 比如Transformer架构的核心是“自注意力机制”,它决定了模型如何捕捉长距离的关联。
- 比如CNN架构的核心是“卷积核”,它决定了模型如何提取图像的边缘和纹理特征。
常见的主流架构对比
为了帮你建立全局视野,这里列举了AI领域最经典的几种架构:
表格
| 架构名称 | 核心特点 | 擅长领域 | 典型代表 |
|---|---|---|---|
| Transformer | 基于注意力机制,并行计算能力强,擅长处理长序列依赖。 | 自然语言处理、多模态 | GPT系列、BERT、Qwen |
| CNN (卷积神经网络) | 通过卷积核提取局部特征,具有平移不变性。 | 图像识别、计算机视觉 | ResNet、AlexNet |
| RNN (循环神经网络) | 具有记忆功能,按时间步顺序处理数据。 | 早期的语音识别、文本生成 | LSTM、GRU |
| MoE (混合专家) | 一种稀疏架构,由多个“专家”网络组成,每次只调用部分专家。 | 超大规模大模型 | Mixtral、Qwen-MoE |
为什么架构如此重要?
架构决定了模型的“上限”和“基因”:
- 决定能力边界:如果你用CNN去写小说,效果会很差,因为它不擅长处理长文本的逻辑关联;如果你用RNN去处理高清视频,速度会极慢。选对架构是成功的关键。
- 影响效率与成本:优秀的架构(如现在的混合滑动窗口注意力)可以在保持性能的同时,大幅降低计算量和显存占用,让模型跑得更快、更便宜。
- 技术演进的载体:AI的发展史,本质上就是架构的进化史——从简单的感知机,到CNN解决视觉问题,再到 Transformer引爆大模型时代。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...