
混合滑动窗口注意力(Hybrid Sliding Window Attention, Hybrid SWA) 是一种旨在解决大语言模型(LLM)处理超长文本时计算成本过高问题的先进架构设计。
简单来说,它不再“一刀切”地让模型关注所有历史文本,而是聪明地结合了局部关注和全局关注两种机制,在保持高性能的同时,极大地提升了效率和速度。
混合滑动窗口注意力核心思想
要理解混合滑动窗口注意力,首先要明白它解决了什么问题:
- 标准注意力(Full Attention)的瓶颈:传统的Transformer模型在生成每一个新词时,都会回头审视之前生成的所有词。这种机制的计算量和内存消耗会随着文本长度的增加而呈二次方增长( O(n2) )。这意味着处理一本长篇小说,所需的计算资源是惊人的,导致速度变慢、成本高昂。
- 滑动窗口注意力(SWA)的局限:为了解决上述问题,滑动窗口注意力应运而生。它规定模型在处理当前词时,只关注最近的
w个词(即一个固定大小的“窗口”)。这将计算复杂度降低到了线性级别( O(n⋅w) ),效率大大提升。但缺点是,模型会“遗忘”窗口之外的早期信息,难以处理需要联系遥远上下文的长程依赖任务。
混合滑动窗口注意力正是为了平衡这两者而生。它的核心思想是:大部分时候只看局部,偶尔回顾全局。
混合滑动窗口注意力工作原理
混合滑动窗口注意力通常通过以下两种方式实现“混合”:
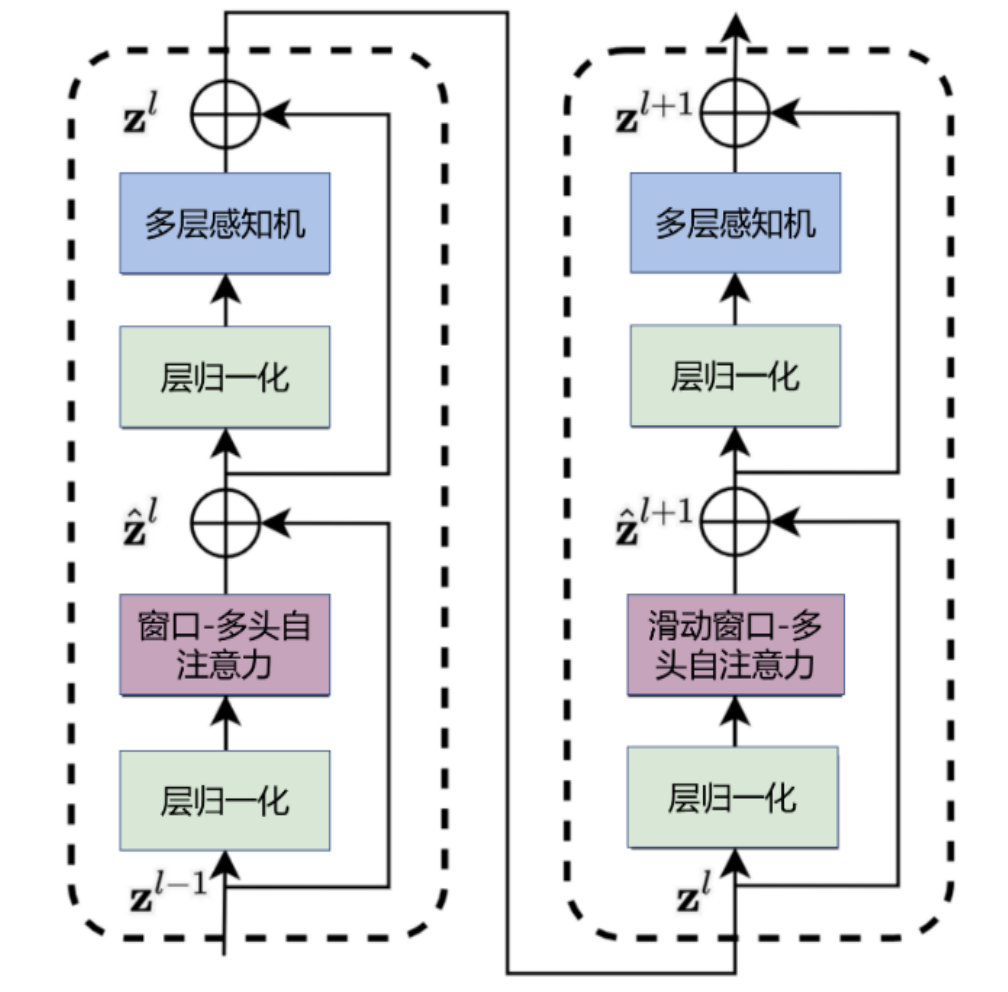
1. 层级混合:交替使用不同类型的注意力层
这是最常见的设计模式。模型的Transformer层被分为两种:
- 滑动窗口注意力层(局部层):这是模型的主体。在这些层中,模型只关注一个固定大小的局部窗口(例如最近的 128或1024个token)。这负责高效地处理语法、短语搭配等局部信息。
- 全局注意力层(Full Attention 层):这些层在模型中稀疏地出现(例如,每隔几层出现一次)。在这些层中,模型会关注完整的上下文。这就像一个“信息枢纽”,负责捕捉和传递跨越整个文档的长程依赖关系,确保模型不会丢失关键的全局信息。
通过这种“少量全局层+大量局部层”的交替结构,模型既能保持高效率,又具备了处理超长文本的全局视野。
2. 内部混合:在单层内结合多种注意力分支
更精细的设计是在单个注意力层内部就进行混合。例如,一个注意力层可以同时包含两个分支:
- 滑动窗口分支:负责处理最近的局部上下文。
- 全局/稀疏分支:负责通过稀疏采样的方式,从遥远的过去检索关键信息。
两个分支的输出再通过一个门控机制进行融合,让模型动态决定在当前步骤是更依赖局部信息还是全局信息。
混合滑动窗口注意力优势与应用
混合滑动窗口注意力架构带来了显著的优势,使其成为当前大模型设计的主流趋势之一。
- 极高的效率:通过大幅减少对全局注意力的依赖,模型的计算量(FLOPs)和显存占用(KV Cache)显著降低。例如,小米的MiMo模型和DeepSeek-V4都利用此技术实现了长上下文的高效处理。
- 保持强大性能:由于保留了全局注意力通路,模型在处理需要长程推理的任务时,性能几乎没有损失,甚至在某些任务上超越了纯全局注意力模型。
- 支持超长上下文:这使得模型能够以可承受的成本处理数十万甚至上百万token的超长文本,如整本书籍、长篇代码库或数小时的会议记录。
混合滑动窗口注意力实际应用案例
- 小米MiMo系列:其HySparse架构是混合滑动窗口注意力的演进。它在模型中仅保留极少数(如 5 层)全局注意力层,其余均为高效的滑动窗口层,实现了KV Cache占用降低近十倍,同时支持100万token的超长上下文。
- DeepSeek-V4:采用了更复杂的混合注意力,其主体由压缩稀疏注意力(CSA)和重度压缩注意力(HCA)交替构成,并额外增加了一个滑动窗口注意力(SWA)分支,专门用于保留近期的细粒度局部信息,弥补压缩机制可能带来的细节丢失。
- Gemma 3:也采用了局部与全局注意力层按 5:1 比例混合的架构,以平衡效率与性能。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...