视觉语言动作模型(Vision-Language-Action Model,简称 VLA) 是当前具身智能(Embodied AI)领域最前沿、最核心的技术范式。
简单来说,VLA是一种端到端的多模态大模型,它的核心使命是打通AI的“感知-理解-执行”闭环,让智能体(如机器人、自动驾驶汽车)真正实现“看懂、听懂、动手”。
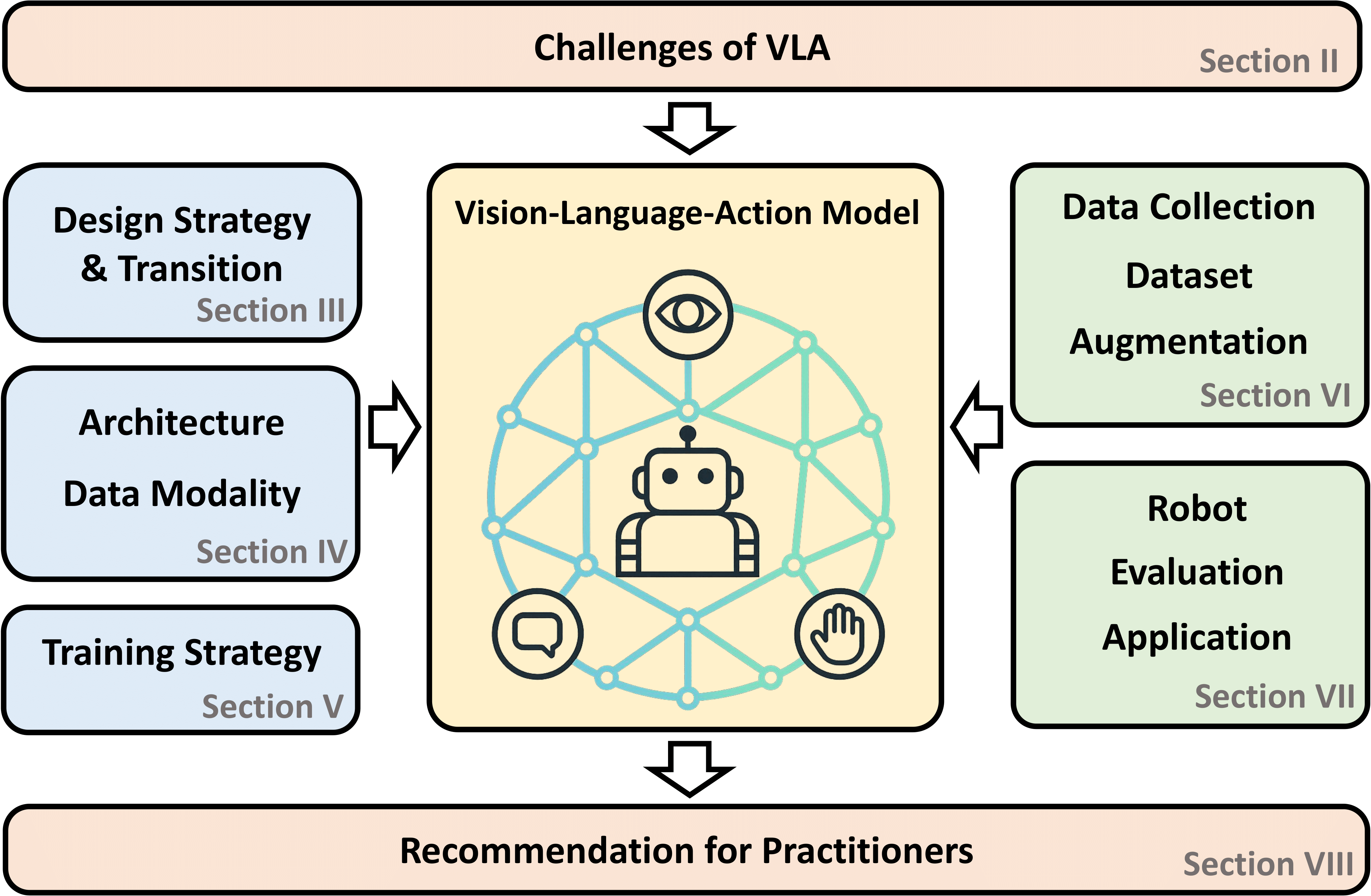
视觉语言动作模型核心定义:从“认知”到“知行合一”
传统的视觉语言模型(VLM,如GPT-4V)只能“看”和“说”,输出的是文字描述或答案。而VLA在VLM的基础上增加了一个动作头(Action Head),使其能够直接输出物理世界可执行的动作序列。
- 输入:多视角的视觉信号(图像/视频)、自然语言指令(如“把桌上的红色杯子拿给我”),以及物理状态信息(如机器人关节角度、车辆速度)。
- 输出:直接映射为机器人或车辆的控制指令(如关节扭矩、末端执行器的位姿、车辆的转向角和加速度)。
- 本质:它将视觉、语言和动作三种模态统一到了同一个语义空间中,跳过了传统机器人技术栈中复杂的感知、规划、控制等独立模块,实现了端到端的直接映射。
视觉语言动作模型发展历程与代表模型
VLA 的概念在 2023 年由谷歌 DeepMind 正式提出,随后引发了全球科技界的百家争鸣:
- 2023年(元年):谷歌 DeepMind 发布RT-2模型,首次正式提出 VLA 技术路线。它将视觉语言大模型与机器人动作数据结合,让机器人具备了跨任务的泛化能力。
- 2024年(开源与普及):OpenVLA框架首次开源了VLA的训练基础设施,大幅降低了研究门槛。同年,谷歌还推出了支持视频输入与连续动作输出的Octo模型。
- 2025年(落地应用):VLA技术开始从实验室走向实际应用,特别是在自动驾驶领域,出现了量产部署的VLA司机大模型。
- 2026年(架构演进):研究趋势向架构极简化、推理强化以及与“世界模型”结合的方向发展。例如注重“思维链”推理的 Alpamayo 模型、践行极简架构的SimVLA,以及将VLA与世界模型深度融合的WorldVLA框架。
视觉语言动作模型核心优势
相比于传统模块化的机器人或自动驾驶系统,VLA具备显著的优势:
- 简化系统架构:移除了 SLAM(定位与地图构建)、运动规划等复杂的中间模块,大幅降低了系统的开发与维护成本。
- 减少误差累积:端到端的训练方式避免了传统流水线中各个模块之间的误差传递和累积,提升了整体执行精度。
- 极强的泛化能力:借助大模型在海量互联网数据上预训练的知识,VLA能够在从未见过的场景或面对陌生的物体时,实现零样本或少样本的任务执行。
- 开放指令理解:能够直接解析人类复杂的自然语言指令,无需预先定义死板的指令集。
视觉语言动作模型主要应用场景
VLA 被视为实现高阶具身智能的关键技术,目前主要应用在以下两大领域:
- 具身智能机器人:包括家庭服务机器人(执行“倒水”、“整理书架”等日常指令)、工业协作机器人(理解柔性生产指令)以及人形机器人。VLA让机器人从执行预设程序进化为能理解世界并自主行动的通用智能体。
- 自动驾驶:VLA 被视为介于传统模块化方案与纯端到端方案之间的“端到端大模型 2.0”。小鹏、理想、Wayve等车企正在积极布局VLA大模型,通过融合视觉感知、语言推理与驾驶动作,来应对复杂的城市路况。
视觉语言动作模型当前面临的挑战
尽管前景广阔,VLA 目前仍面临几大核心瓶颈:
- 高质量数据稀缺:获取大规模的“视觉-语言-动作”配对数据(尤其是真实的机器人交互数据)成本极高,规模远小于互联网文本数据。
- 物理约束与安全:模型输出的动作必须符合物理世界的动力学规律和安全性要求,在开放环境中如何保证绝对的可靠性仍需探索。
- 长时序任务规划:面对需要多步骤推理和长期记忆的复杂任务,当前 VLA 模型的规划能力依然有限。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...