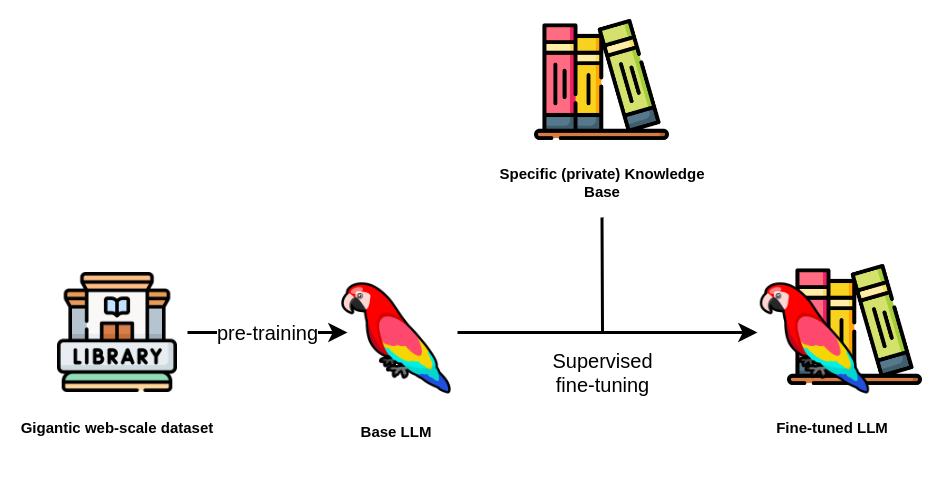
全监督微调(Full Supervised Fine-Tuning),也常被称为全参数微调(Full-Parameter Fine-Tuning),是微调大语言模型最经典、最彻底的一种方式。
简单来说,全监督微调的核心逻辑是:在特定任务的训练过程中,将预训练底座模型的所有参数全部解冻并进行更新,让模型的每一个权重都根据新数据进行深度适配。
全监督微调的核心特点
- 彻底的重塑:全监督微调不保留模型原有的任何“僵化”参数。通过让所有参数参与训练,模型能够最大程度地学习新领域的知识和特定的输出风格,从而获得最优的任务适应能力。
- 高质量数据依赖:这种方法极度依赖高质量的标注数据(通常是“指令-回答”配对的形式)。如果数据量太少,全参数更新非常容易导致模型过拟合(即死记硬背了训练数据,但遇到新问题反而不会了)。
- 极高的资源消耗:由于需要同时计算和更新模型的全部参数(比如几十亿甚至上千亿个),全监督微调对计算资源(如GPU显存)和训练时间的要求非常高,成本极其昂贵。
优缺点对比
表格
| 维度 | 优点 | 缺点 |
|---|---|---|
| 性能表现 | 灵活性最高,能充分挖掘模型潜力,在特定任务上往往能达到最佳效果。 | 如果新任务与预训练任务差异过大,可能会破坏模型原有的通用能力(即“灾难性遗忘”)。 |
| 资源成本 | 训练逻辑相对直接,不需要设计复杂的旁路或适配器结构。 | 计算与存储成本巨大,对小团队或个人开发者极不友好。 |
| 数据需求 | 能够深度吸收大规模、高质量的领域数据。 | 需要海量的高质量标注数据,在小样本场景下极易过拟合。 |
🆚 什么时候用全监督微调?
在实际应用中,全监督微调通常不是首选的“轻量级”方案,它更多出现在以下场景:
- 高价值、高复杂度的特定任务:例如在医疗诊断、国防安全等容错率极低的领域,或者需要模型彻底掌握一门全新语言/专业知识时,全监督微调能提供最可靠的性能保障。
- 算力与数据极其充足:当团队拥有强大的算力集群,并且已经准备好了数万甚至数百万条高质量的领域专属数据时,全监督微调能最大化地发挥这些数据的价值。
- 与参数高效微调(PEFT)的对比:目前更主流的微调方式是LoRA、QLoRA等参数高效微调(PEFT)技术。它们通过冻结大部分模型参数,只训练极少部分新增的参数,就能达到接近全监督微调的效果,且训练速度极快、显存占用极低。
概括一下:
如果把大模型比作一个已经大学毕业的“全能通才”,全监督微调就像是把他送回去重新读一个深度的博士学位,彻底重塑他的知识体系,让他成为某个极窄领域的顶尖专家;而像LoRA这样的高效微调,则更像是给他报一个短期的职业技能培训班,让他快速掌握一项新技能,同时保留原有的大部分通用能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...