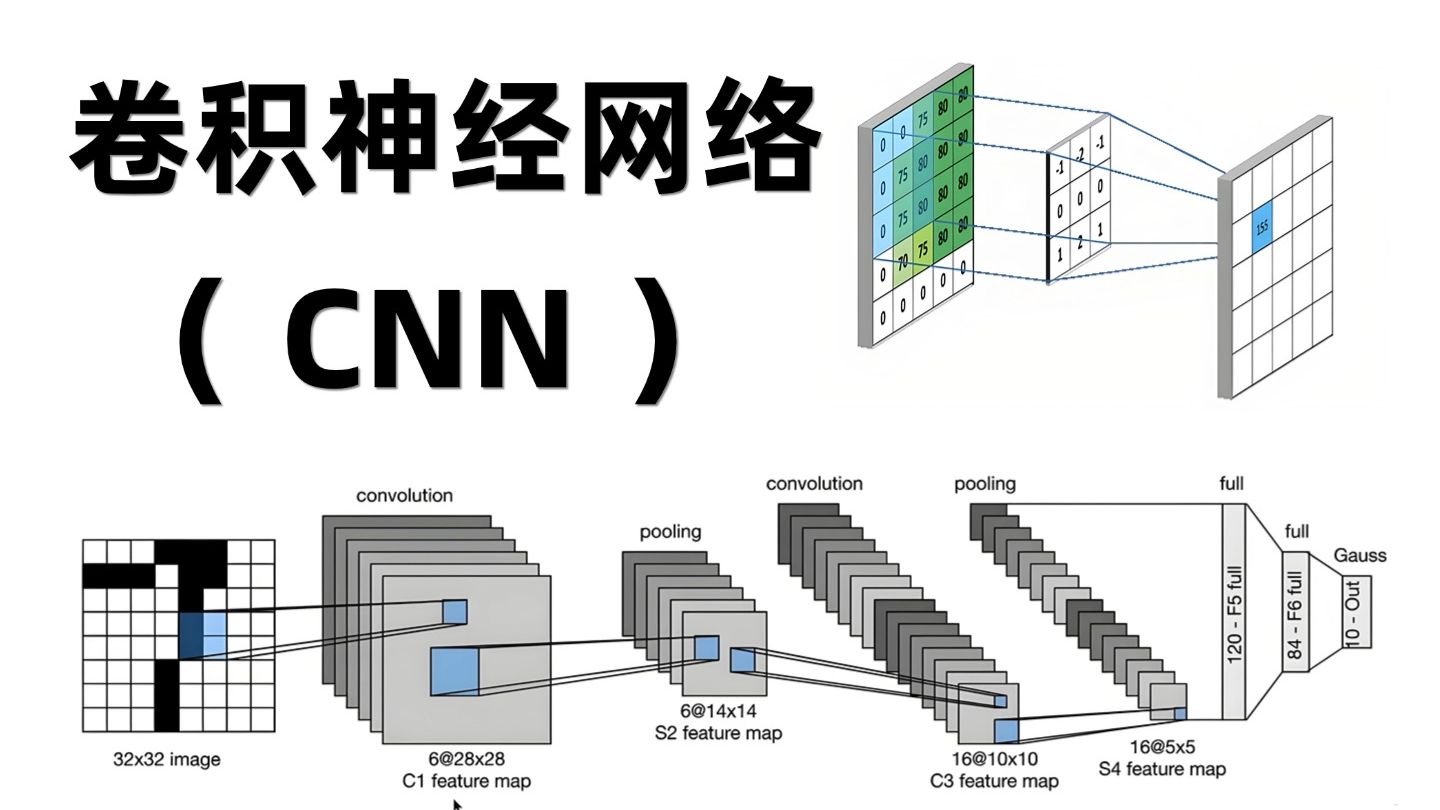
“底座大模型”(也常被称为“基座大模型”)可以通俗地理解为人工智能大模型的“地基”或“基础版本”。它具备通用的语言理解、逻辑推理和内容生成能力,但通常没有经过特定场景的精细调教,因此还不能直接完美地响应人类的各种复杂指令。所有的定制化、场景化应用(比如医疗助手、车载AI、教育辅导等),都是在这个“底座”的基础上进行后续的微调和优化开发出来的。
目前,底座大模型主要分为两类:一类是面向全行业的通用底座,另一类是面向特定行业的垂类(专属)底座。
通用底座大模型
这类模型没有特定的行业限制,能力体系全面,是大多数AI应用的起点。
- 架构分类:按技术架构可分为仅解码器(Decoder-only,擅长生成,如GPT系列、Qwen系列)、仅编码器(Encoder-only,擅长理解,如Bert系列)以及编码器-解码器(Encoder-Decoder,兼顾理解与生成,如T5系列)。
- 代表模型:目前主流的开源底座大模型包括Meta的 Llama 系列、阿里的 Qwen(通义千问)系列、清华的 GLM 系列等。
行业专属底座大模型
为了解决特定行业的专业需求、数据隐私和合规问题,许多机构和企业在通用底座的基础上,注入了大量的行业专业知识,形成了专属底座。以下是几个典型的行业案例:
- 工业与电力领域
- 南网电力多模态大模型底座:南方电网发布的电力专属底座,融合了电网全场景的多源数据,能解决传统模型缺乏电力专业知识的问题,应用于变电站漏油检测、安监违章识别等核心业务。
- 工业私有化底座:在化工、高端制造等央企场景中,为了保护核心工艺参数等机密数据,通常会采用基于国产算力(如昇腾、海光)搭建的私有化底座。这种底座部署在企业内网,确保数据主权和供应链安全。
- 具身智能基座大模型:由深圳市推动研发,面向工业制造领域,旨在赋能机器人具备交互、预测与决策能力,推动机器人进入工厂、车间等场景进行焊接、装配等作业。
- 汽车行业
- 豆包大模型(汽车底座):火山引擎推出的汽车AI解决方案,充当整车的“AI大脑”。它已搭载于超过700万辆智能汽车,覆盖奔驰、奥迪、红旗等主流车企,实现了整车能力的一体化调度,重构了智能座舱的交互体验。
- 基础教育领域
- “师承万象”基础教育大模型:由北京师范大学等机构研发,紧扣新课标知识体系。它具备智能解题、启发式答疑、教案生成等能力,专门服务于真实的教学场景,并已在北京多所学校投入使用。
- 科学研究领域
- “磐石”科学基础大模型:中国科学院打造的服务于科学任务的智能底座。它采用专业科学语料训练,具备科学文献萃取、知识推理等能力,并衍生出了面向粒子物理、材料、天文等不同学科的专属模型(如“磐石·祝融”、“磐石·金乌”等)。
- 泛娱乐领域
- XVERSE-Ent:元象开源的专注于泛娱乐场景的底座大模型,深度适配社交互动、游戏叙事、小说剧本创作等领域,填补了该领域的专属开源模型空白。
总的来说,底座大模型正在从单一的通用能力,向“通用+垂直”的多元化生态发展,为千行百业的智能化转型提供着坚实的底层支撑。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...