
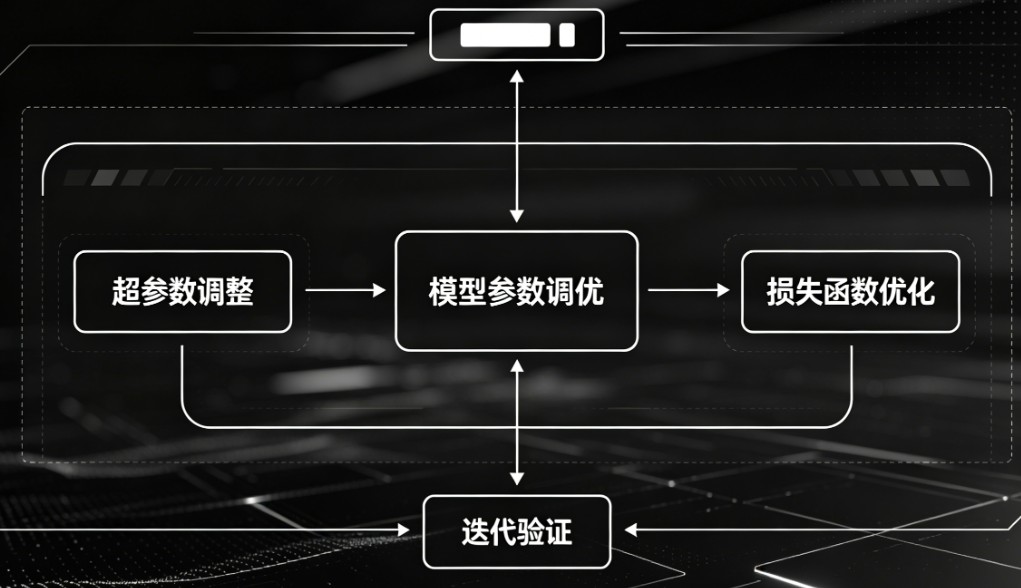
“模型参数调优”这个词在日常交流中其实包含了两层完全不同的含义。为了彻底搞清楚,我们需要把“模型本身的参数”和“训练时的超参数”分开来看:
1. 狭义的“参数调优”:即“模型微调”
- 原理:在一个已经预训练好的通用大模型(比如GPT、Qwen)基础上,喂给它一些特定领域的专属数据(比如医疗病历、法律卷宗、公司内部的客服问答),让模型内部的权重和偏置(即模型参数)进行小幅度的更新和调整。
- 打个比方:
- 预训练模型就像一个名牌大学毕业的“通才”,上知天文下知地理,但不懂你们公司的具体业务。
- 微调(参数调优)就像是让这个通才去你们公司“实习”了三个月。他通过看你们公司的内部资料(特定数据),学会了用公司的黑话、了解具体的办事流程,最终变成了一个能直接上岗干活的“专才”。
- 常见手段:现在最主流的高效微调方法是LoRA,它不需要把整个模型重新训练一遍,而是通过给模型打一些“小补丁”(新增少量可训练参数),成本极低且效果显著。
2. 广义的“参数调优”:即“超参数调优”
这通常发生在模型训练或微调的准备阶段,也叫“调参”。它调整的不是模型内部的权重,而是控制模型训练过程的配置选项。
- 原理:在训练开始之前,由工程师手动设置或通过算法自动搜索的一组配置。这些配置决定了模型“怎么学”、“学多快”。
- 常见的超参数包括:
- 学习率(Learning Rate):控制模型每次学习时步子迈多大。步子太大容易学歪(不收敛),步子太小又学得太慢。
- 批次大小(Batch Size):模型一次看多少条数据再更新一次脑子。
- 迭代次数(Epochs):模型要把这些数据反复学几遍。
- 打个比方:
- 如果微调是让学霸“实习”,那么超参数调优就是“制定实习计划”。
- 每天学几个小时(学习率)?一次看几页书(批次大小)?总共实习几个月(迭代次数)?这些计划制定得好不好,直接决定了实习(训练)的最终效果。
概括一下两者的区别
表格
| 维度 | 模型参数(微调) | 超参数(调参) |
|---|---|---|
| 调整对象 | 模型内部的权重和偏置(大脑里的神经连接) | 训练前的配置选项(学习计划表) |
| 如何调整 | 模型在训练时通过数据自动学习更新 | 工程师在训练前手动设置或自动搜索 |
| 核心目的 | 让模型掌握特定领域的知识,适配具体任务 | 让模型训练得更快、更稳,防止学偏或死记硬背 |
所以,当你听到别人说“我在做模型参数调优”时,你可以结合语境判断:他可能是在用专属数据微调模型(Fine-tuning),也可能是在反复测试寻找最佳的训练配置(调超参数)。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...