
LoRA(Low-Rank Adaptation,低秩自适应)是一种用于高效微调大模型的“轻量级插件”技术。
简单来说,如果把一个庞大的AI基础模型(比如拥有数十亿参数的GPT或Stable Diffusion)比作一款“重型主机游戏”,那么LoRA模型就是一个“极小的游戏模组(MOD)”或“扩展包”。
它不需要你重新下载或修改几十GB的游戏本体,只需要加载一个几 MB或几十MB的小文件,就能让游戏增加全新的剧情、角色或画风。
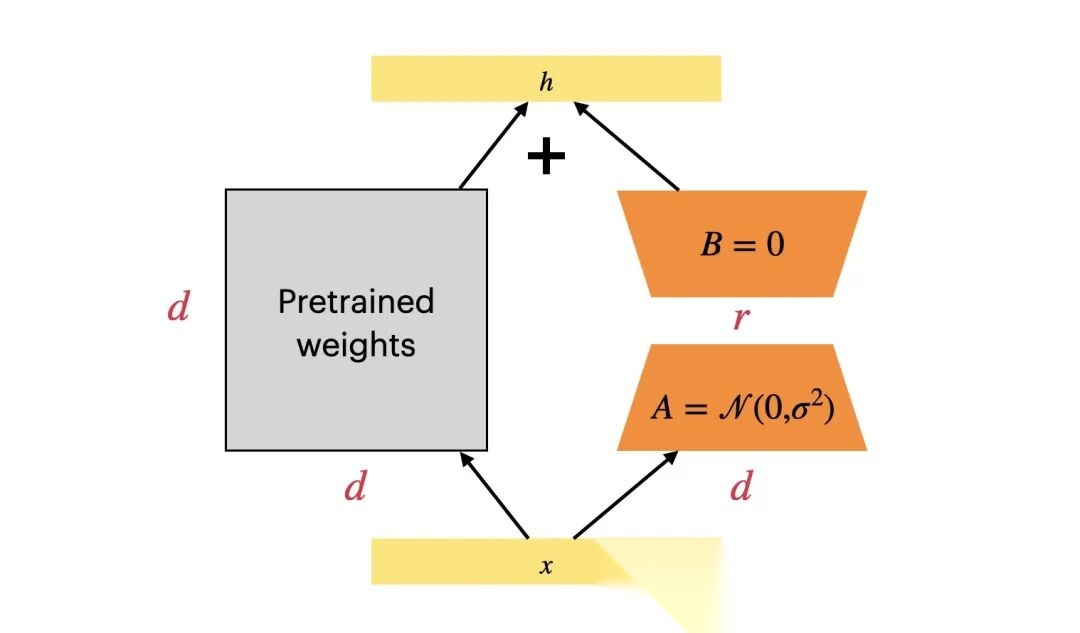
LoRA的核心工作原理
LoRA的核心思想非常巧妙:
- 冻结大模型:在训练时,保持原本庞大的AI模型(基础权重)完全不动。
- 外挂小矩阵:在模型的关键部位(通常是Transformer的注意力层)插入两个极小的、可训练的低秩矩阵(A和B)。
- 只练小插件:训练过程中,只更新这两个小矩阵的参数。因为参数量极小(通常仅为原模型的 0.01% – 0.2%),训练速度极快,且对电脑配置要求大幅降低。
为什么LoRA如此流行?
LoRA完美解决了大模型落地应用中的三大痛点:
表格
| 痛点 | LoRA 的解决方案 |
|---|---|
| 硬件门槛高 | 极度省资源:在单张消费级显卡(如 RTX 3090)上就能微调拥有上百亿参数的大模型,显存占用降低约 75%。 |
| 存储成本高 | 体积极小:一个 10GB 的大模型,微调后的 LoRA 插件可能只有 10MB – 200MB。你可以轻松在电脑里存几百个不同风格的 LoRA。 |
| 任务切换慢 | 即插即用:基础模型保持不变,只需动态加载不同的 LoRA 插件,就能让同一个 AI 瞬间在“写代码”、“写小说”、“画二次元图”之间无缝切换。 |
LoRA的两大主流应用场景
目前LoRA技术主要活跃在以下两个领域:
- AI 绘画(如 Stable Diffusion):
这是大众最熟悉的场景。你在Civitai等网站上下载的LoRA,通常用来固定画风、特定角色或物体。比如,加载一个“吉卜力画风”的LoRA,AI就能画出宫崎骏风格的插画;加载一个“钢铁侠”的LoRA,AI就能精准生成钢铁侠的形象。 - 大语言模型(如 LLaMA, ChatGLM):
在企业或科研中,开发者利用LoRA让通用大模型快速学会垂直领域的专业知识。比如,给通用模型挂上一个“医疗问诊LoRA”,它就能变成专业的医疗助手;挂上“法律条文LoRA”,它就能变成法律顾问。
概括
LoRA模型本质上就是大模型的“高效技能补丁”。它让普通人也能用极低的成本,定制出属于自己专属风格的 AI 模型,是目前 AI 领域最实用、最火爆的微调技术之一。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...