

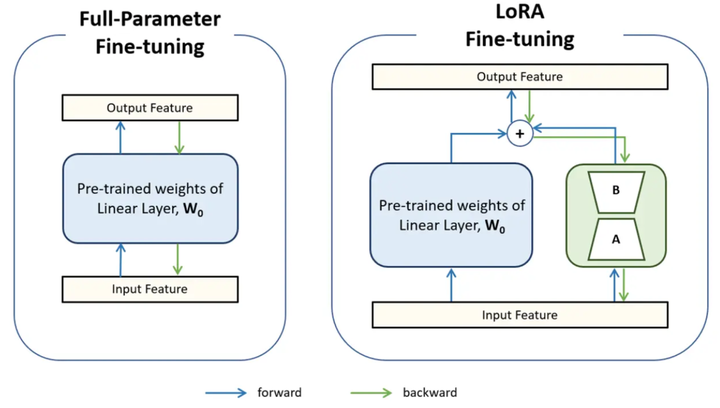
- 全参数微调就像是“回炉重造”,把他大脑里的所有神经元都重新调整一遍,让他适应新工作。
- LoRA 微调就像是给他“发个外挂笔记本”,让他大脑保持原样,只在笔记本上记新工作的要点。
全参数微调和LoRA微调核心区别对比表
表格
| 特性 | 全参数微调 | LoRA 微调 |
|---|---|---|
| 形象比喻 | 回炉重造:彻底改变大脑结构。 | 打补丁/挂外挂:大脑不动,只加个小插件。 |
| 训练参数量 | 100%。模型有多少参数,就训练多少参数(比如 70 亿个)。 | 极少(通常 <1%)。只训练新增的两个小矩阵 A 和 B (比如几百万个)。 |
| 显存需求 | 极高。需要巨大的显卡显存来存储梯度和优化器状态。 | 极低。普通消费级显卡(甚至单张 3090/4090)就能跑。 |
| 训练速度 | 慢。计算量巨大。 | 快。因为计算量小了很多。 |
| 存储成本 | 高。每训练一个新任务,都要存一份完整的模型(几十 GB)。 | 低。只需存那个小插件(几 MB 到几百 MB)。 |
| 灾难性遗忘 | 容易。因为改动太大,容易忘掉原本学到的通用知识。 | 不容易。因为原模型没动,保留了原本的通用能力。 |
| 最终效果 | 理论上在特定任务上能达到最优。 | 效果通常接近全参数微调,甚至在某些情况下更好。 |
全参数微调和LoRA微调深度原理解析
全参数微调:牵一发而动全身
- 做法:输入数据进来,反向传播时,模型里每一个权重参数都会根据误差进行更新。

- 缺点:如果你有 10 个不同的任务(比如写代码、写小说、做翻译…),你就得存 10 个完整的巨型模型。这太占硬盘了,而且训练一次电费都吓人。
LoRA 微调:低秩分解的魔法
- 优势:
- 省钱:原本要训练 100 亿个参数,现在可能只需要训练 100 万个。
- 灵活:原本的大模型像是一个通用的“底座”。如果你想做翻译,就加载“翻译 LoRA 插件”;想做写代码,就卸载插件,加载“代码 LoRA 插件”。一个底座,无限扩展。
简单来说
全参数微调是“富人的游戏”,适合大厂有几千张显卡去训练一个极致的专用模型。
LoRA 微调是“平民的神器”,让普通人也能在单张显卡上微调出属于自己的个性化大模型。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...