
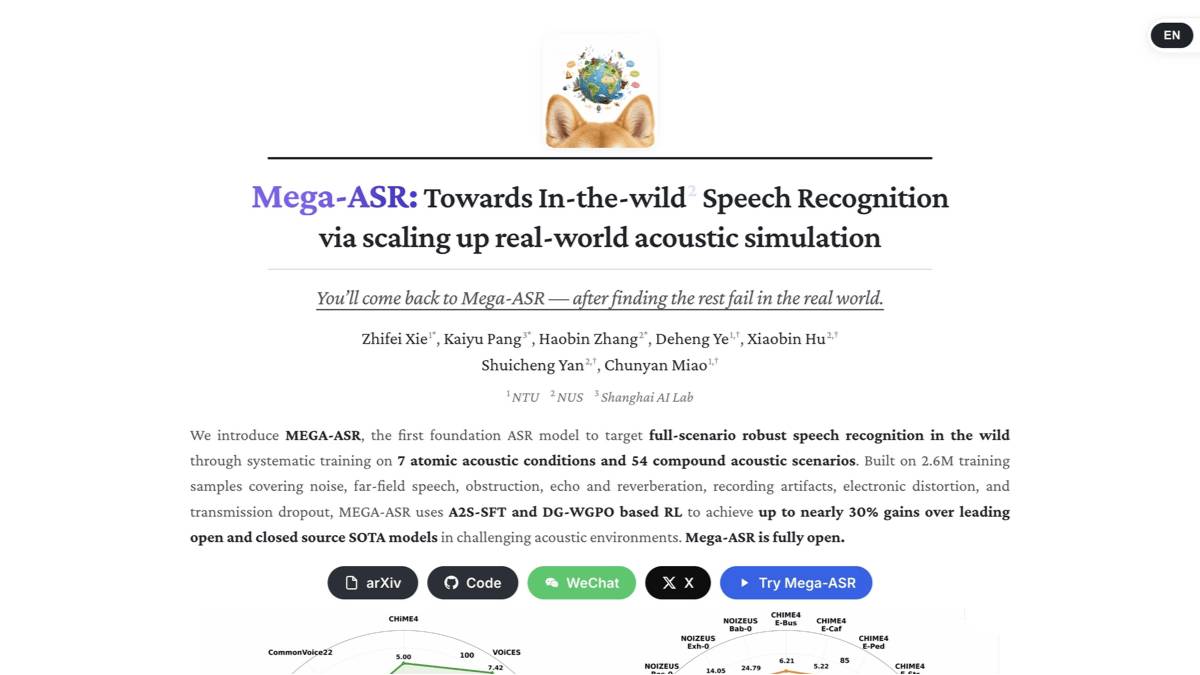
Mega-ASR 是新加坡国立大学、南洋理工大学与上海人工智能实验室等团队于2026年5月联合开源的全场景鲁棒语音识别基座模型,基于Qwen3-ASR 1.7B架构,通过声学仿真规模化训练与强化学习优化,显著解决高噪声、野外环境下的语音识别幻觉、丢字问题,在极端噪声场景中相对传统模型(如Whisper、Gemini 3 Pro)词错率(WER)降低最高达30%。其核心价值在于为工业现场、野外作业等复杂声学环境提供了高精度、低延迟的本地化语音识别解决方案。
Mega-ASR技术原理
1. 声学仿真规模化训练
- 200万小时真实噪声数据集:
研发团队构建了 Voices-in-the-Wild-2M 数据集,包含 240万个样本、总长1.1万小时 的极端噪声环境语音(如机械轰鸣、风噪、电磁干扰),通过物理级声学仿真技术模拟真实工业场景。 - 双粒度 WER 门控策略优化(DG-WGPO):
采用强化学习动态调整模型训练目标,针对短时突发噪声和长时稳态噪声分别设计细粒度与粗粒度词错率反馈机制,避免传统模型在噪声突变时的性能骤降。
2. 抗幻觉与抗丢字设计
- 上下文感知的注意力修正机制:
通过分析语音流的时频特征与语言模型概率分布,动态抑制噪声引发的虚假音素生成,减少“幻觉输出”(如将机械噪音误识别为语音)。 - 多假设融合验证:
生成多个候选识别结果后,利用声学-语言联合置信度评分筛选最优解,显著降低高噪声下的丢字率(如压力异常告警中的关键数字漏识别)。
Mega-ASR功能优势
1. 极端噪声下的高鲁棒性
- 95dB 强噪声环境仍保持高精度:
在电力泵房、风电塔筒等 80–110dB 背景噪声场景中,关键词识别率稳定超过98%,远超通用 ASR 模型(通常低于70%)。 - 抗非平稳噪声干扰:
对变压器嗡鸣、钻机运转等非稳态工业噪声的适应性显著提升,WER 相对 Whisper Large v3 降低 25–30%。
2. 本地化与安全特性
- 纯离线边缘部署能力:
模型经 4-bit 量化压缩后可嵌入防爆平板、巡检仪等边缘设备,在完全断网环境下实现毫秒级语音转写,避免数据外传风险。 - 物理级安全加固:
音频数据在受信任执行环境(TEE)中内存即处理即销毁,不产生临时缓存,符合能源、军工等关键基础设施的安全要求。
3. 开源生态支持
- 全栈开源协议:
采用Apache-2.0 协议开源全部代码、模型权重及 Voices-in-the-Wild-2M 数据集,支持开发者快速适配垂直场景。 - 轻量化推理优化:
通过算子级国产 NPU 适配,在移动端实现 RTF(实时率)<0.05,推理速度较未优化模型提升 3倍以上。
Mega-ASR典型应用场景
1. 能源行业安全作业
- 实时语音告警联动:
巡检人员口头报告“压力异常”时,系统毫秒级触发紧急停机指令,避免人工确认延迟导致的安全事故。 - 高噪声环境免提操作:
在泵房、变电站等场景中,通过语音直接完成设备参数录入、巡检项勾选,解放双手并降低操作风险。
2. 工业质检与流程合规
- 销售/服务过程全量质检:
结合Mega NLP大语言模型,对客服、销售对话进行语义级合规检查(如规避关键词替换的违规表述),检出率提升 40% 以上。 - 自动化报告生成:
将现场语音记录实时转写为结构化工单,自动关联设备编号、故障类型,减少人工录入错误。
3. 野外与应急场景
- 极端环境语音交互:
适用于野外勘探、灾害救援等网络不稳定场景,离线支持方言、口音及语速变化的鲁棒识别。 - 多语言混合内容处理:
对中英文混杂、专业术语密集的语音(如医疗急救指令),语码切换识别准确率提升 15%。
Mega-ASR的项目地址
项目主页:https://xzf-thu.github.io/Mega-ASR/
GitHub仓库:https://github.com/xzf-thu/Mega-ASR
Hugging Face 模型库:https://huggingface.co/zhifeixie/Mega-ASR
arXiv技术论文:https://arxiv.org/pdf/2605.19833
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...