
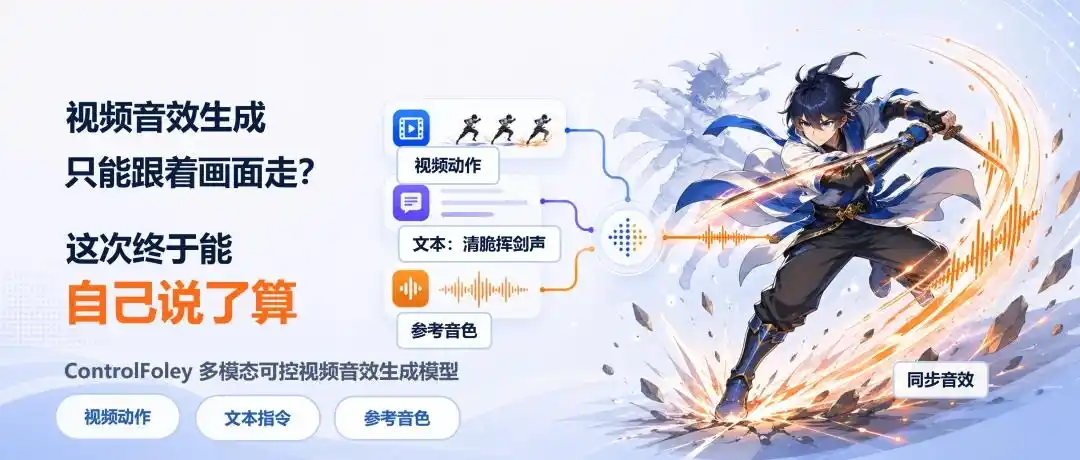
ControlFoley是小米大模型应用团队与武汉大学联合开发的开源可控视频音效生成模型。其核心突破在于 首次实现”按意图配声音”的精准控制能力,解决了传统音效生成模型”只能根据画面自动猜声音”的局限性,使创作者能通过文本指令或参考音频主动干预音效内容与风格。
该模型在多个视频音效生成基准测试中达到开源SOTA水平,并在语义对齐、时间同步精度上接近甚至超越部分闭源商业系统。
ControlFoley核心特点
1. 真正的”可控性”突破
- 三类任务统一框架:首次将 TV2A(文本引导配音)、TC-V2A(文本控制配音)、AC-V2A(参考音频控制配音) 整合至单一模型,无需切换不同模型即可实现:
- 文本覆盖画面冲突:当视频内容与文本指令矛盾时,仍能严格遵循文本生成目标音效。
- 参考音色精准迁移:输入一段参考音频,模型能提取其音色特征并绑定到视频动作节奏上,避免传统方法中音画不同步问题。
- 新增VGGSound-TVC评测基准:专门测试模型在”画面与文本冲突”场景下的可控性,此前行业仅关注”配得准不准”,无人量化”听不听话”的能力。
2. 高精度时间同步
- 音画同步误差中位数≤+5.1ms(正数表示音频稍晚于画面),最大偏差不超过8ms,完全落在人类感知不可辨区间(ITU标准)。
- 毫秒级动态对齐:通过光流法估算动作发生帧位置,结合亚帧插值算法,确保音效起始点精确匹配视频中的物理事件(如脚步落地、物体撞击)。
3. 开源完整性与易用性
- 开箱即用:代码、模型权重、技术报告、在线Demo及ComfyUI节点全部开源,支持HuggingFace和Running Hub平台一键体验。
- 多模态输入兼容:支持视频、文本、参考音频的任意组合输入,无需额外训练即可适应不同创作需求。
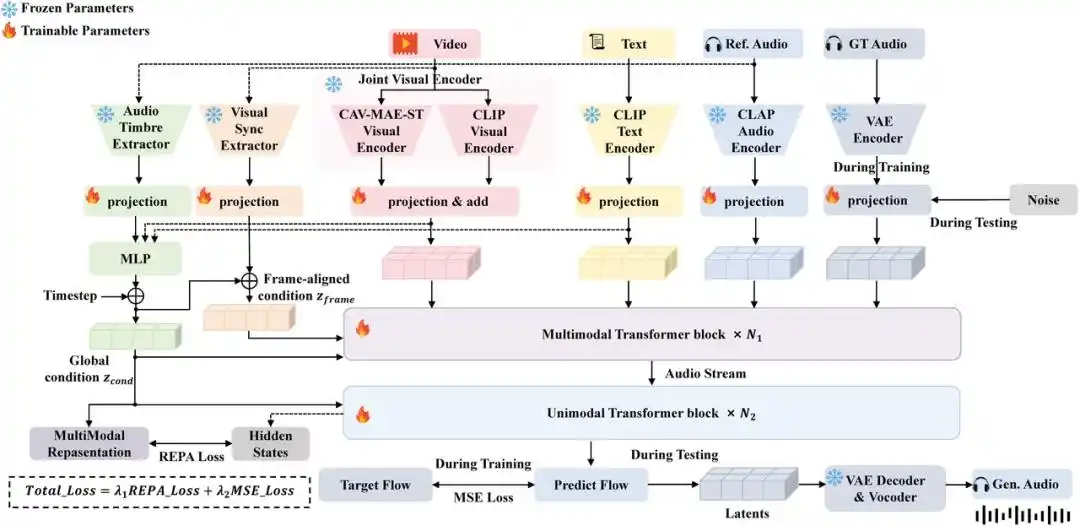
ControlFoley技术原理
1. 联合视觉编码:CAV-MAE-ST时空音视频理解
- 替代传统CLIP:自研的时空音视频编码器CAV-MAE-ST专为音效生成任务优化,聚焦”动作何时发生”而非通用语义,通过视频帧与音频特征的联合建模,精准捕捉动作节奏与时间同步线索。
- 解决视觉信息压制问题:在多模态融合中,视觉信号常过度主导文本控制。CAV-MAE-ST通过强化音视频时空对齐能力,使模型在画面与文本冲突时仍能响应文本指令。
2. 时间-音色解耦策略
- 分离冗余时间信息:参考音频同时包含”何时发声”和”音色如何”两类信息。ControlFoley通过抑制参考音频中的时间结构,仅提取全局音色特征,确保视频动作节奏不受干扰。
- 双路径生成机制:
- 视频流:控制音效发生的时间点与节奏;
- 音色流:控制声音的频谱特征与风格,二者解耦后融合输出。
3. 模态鲁棒训练框架
- 随机模态Dropout:训练中随机屏蔽文本或参考音频输入,强制模型适应不同条件组合。
- 统一REPA对齐目标:将生成音频的内部表示与聚合后的多模态条件对齐,提升语义一致性与控制稳定性,避免多输入条件下的效果波动。
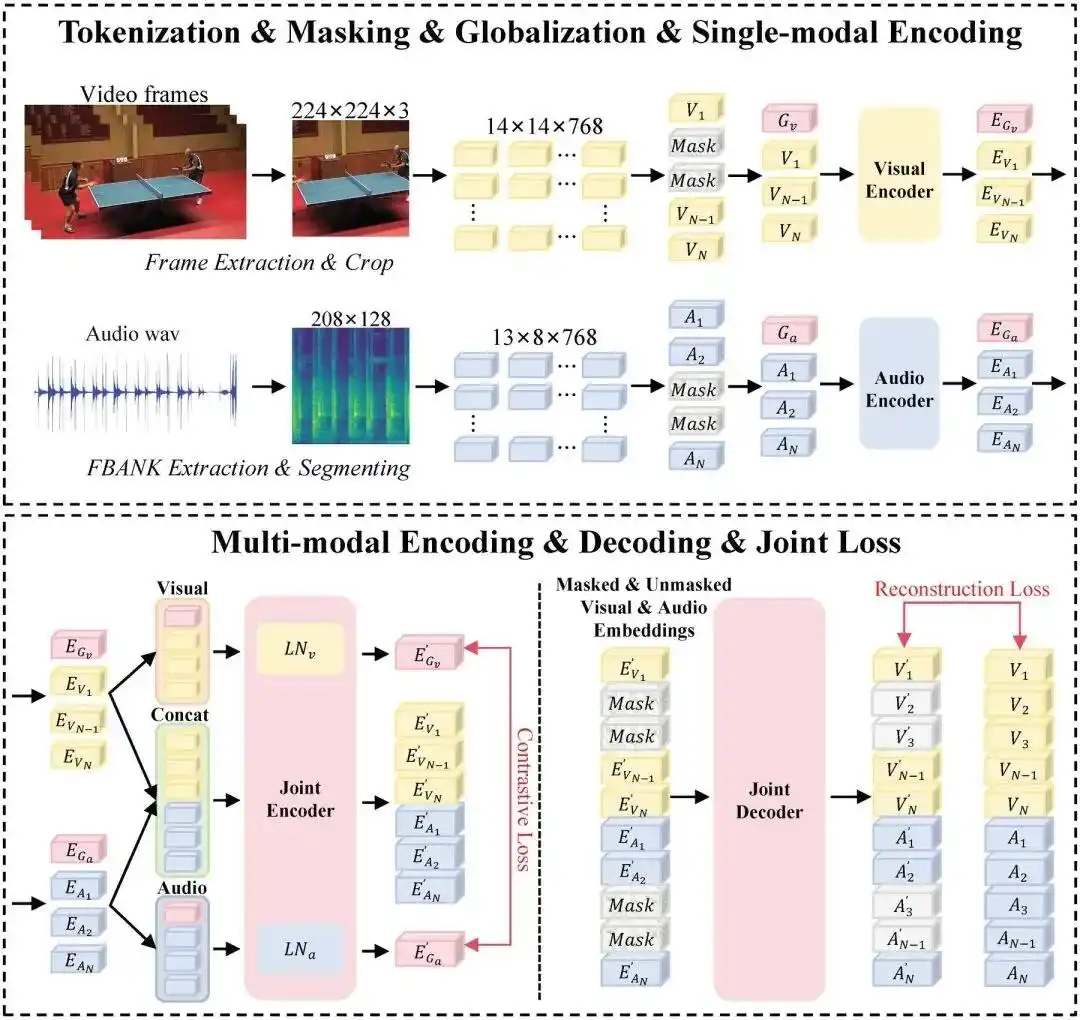
ControlFoley核心功能
1. 冲突场景下的精准控制
- 文本优先级机制:当启用
Mask Away Clip参数时,模型以文本指令为最高优先级,即使视频内容与文本矛盾(如画面为雨夜街道,文本要求”沙漠风声”),仍生成符合文本的音效。 - 负面提示词支持:可指定排除特定声音(如输入
-music避免AI生成无序配乐),显著提升输出可控性。
2. 参考音效迁移
- 风格克隆与动作绑定:输入参考音频(如小提琴独奏片段)后,模型能提取其音色特征并严格匹配视频动作时序。例如,视频中人物敲击桌面的动作,会生成具有小提琴音色的”敲击声”,而非简单循环参考音频。
3. 多粒度语义理解
- 环境-材质-动作分层解析:自动拆解视频中的:
- 环境要素(如”雨夜”触发雨声+雷鸣);
- 材质属性(如”金属台阶”使用高频反射音效);
- 动作细节(如”快速滑动+撞击”合成摩擦+闷响混合音)。
- 情绪氛围感知:通过提示词(如
sci-fi horror, eerie echo)自动添加匹配的低频嗡鸣与空间回响。
ControlFoley应用场景
1. 影视与游戏开发
- 自动化Foley拟音:为动画片段实时生成脚步声、物体交互音效,替代传统人工拟音。独立开发者可用消费级显卡产出接近专业水准的结果,成本降至传统方案的1/10。
- 风格化音效定制:在游戏过场动画中启用”增强版”模式,让拔剑声更具冲击力;纪录片中切换至”自然主义”风格避免过度渲染。
2. 短视频与内容创作
- 一键环境音补充:为口播视频自动添加匹配场景的背景音,无需手动匹配音效库。
- 冲突内容精准控制:创作者可要求”画面是城市街道,但生成森林鸟鸣”,用于制作隐喻性内容或创意短片。
3. 实时交互系统
- VR/AR场景适配:根据用户动作实时生成脚步声,无需预置音效库。
- 直播动态音效:结合直播画面内容,自动生成匹配当前场景的氛围音。
ControlFoley的项目地址
项目官网:https://yjx-research.github.io/ControlFoley_web_page/
GitHub仓库:https://github.com/xiaomi-research/controlfoley
HuggingFace模型库:https://huggingface.co/YJX-Xiaomi/ControlFoley
arXiv技术论文:https://arxiv.org/abs/2604.15086
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...