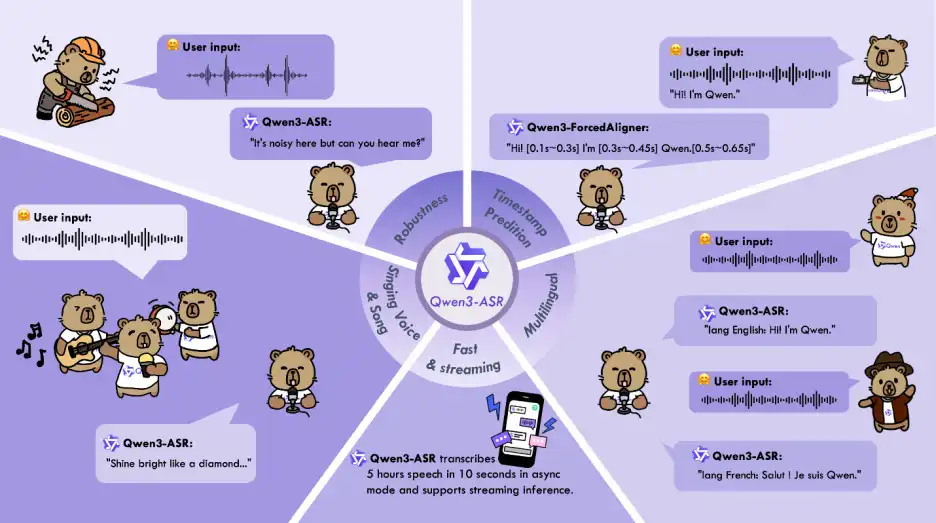
Qwen3-ASR-1.7B是阿里云通义千问团队开源的17亿参数多语言语音识别模型,在中文、英文等52种语言及方言的识别任务中达到开源模型SOTA水平(中文词错率低至5.2%,显著优于Whisper-v3的9.86%)。
其核心优势在于高精度、强抗噪能力及多语言无缝切换,尤其适合会议转录、客服系统等需处理复杂声学环境的场景,且支持私有化部署保障数据安全。
Qwen3-ASR-1.7B核心性能与技术特点
1. 行业领先的识别精度
- 中文场景:词错率(WER)5.2%,比Whisper-v3低4.66个百分点,比GPT-4o低10.1个百分点。
- 英文场景:词错率(WER)7.8%,优于Whisper-v3(9.76%)和GPT-4o(25.50%)。
- 专业术语识别:在技术会议、医疗问诊等场景中,对“Kubernetes”“零信任架构”等术语的识别准确率超过95%。
2. 多语言与方言支持能力
- 覆盖52种语言及方言:
- 30种主流语言:中、英、日、韩、法、德、西语等;
- 22种中文方言:粤语、上海话、四川话、闽南语等;
- 多口音英语:美式、英式、印度式等16国口音。
- 自动语言检测:无需手动指定语言,实时切换中英混杂内容。
3. 复杂环境鲁棒性
- 抗噪能力:在信噪比10dB的重度嘈杂环境中,识别准确率仍达89.7%。
- 多人对话处理:对会议中短暂语言重叠、背景键盘声等干扰,自动过滤非语音噪声并保持语义连贯。
- 歌唱识别:中文歌曲识别词错率13.91%,显著优于同类模型。
Qwen3-ASR-1.7B关键架构与功能创新
1. 三段式模型架构
- AuT音频编码器(300M参数):将原始音频转换为声学特征,支持100Hz帧率输入;
- 投影器:对齐声学特征与文本嵌入空间;
- Qwen3-1.7B语言模型:基于Qwen3-Omni基座,解码生成高连贯性文本。
2. 强制对齐技术突破
- 毫秒级时间戳:支持11种语言的词级时间戳标注,单次处理最长5分钟音频;
- 精度优势:时间戳预测误差低于WhisperX和NeMo-Forced-Aligner,实时因子低至0.0089。
3. 高效推理优化
- 流式/离线统一支持:最长处理60分钟音频,实时因子0.3x;
- 批量吞吐能力:通过vLLM框架实现高并发推理,128并发时吞吐量达单并发的2000倍。
Qwen3-ASR-1.7B典型应用场景与部署建议
1. 高价值落地场景
- 会议纪要自动化:发言人区分准确率89%,专业术语识别率92%,大幅减少人工校对工作量。
- 多语言客服系统:在保险行业客服录音测试中,术语识别准确率达91%,错误率比普通工具低60%。
- 车载语音控制:80km/h行驶速度下识别准确率85%+,支持离线运行避免网络依赖。
2. 部署资源需求
表格
| 场景 | 最低配置 | 推荐配置 |
|---|---|---|
| 个人测试 | NVIDIA GPU显存≥6GB | RTX 3060 12GB显存 |
| 中小企业日常使用 | 显存≥8GB | RTX 4060 12GB显存+32GB内存 |
| 企业级高并发 | 显存≥16GB | Tesla T4+64GB内存 |
| 关键限制 | 显存占用约12GB | 流式处理可降低长音频内存压力 |
3. 开源生态支持
- 部署方式灵活:支持Docker一键部署、vLLM批量推理、Gradio交互界面;
- 商用友好:Apache-2.0协议开源,允许商业用途且无需回传数据。
- 微调扩展性:可通过领域自适应微调提升专业场景表现(如医疗术语识别)。
Qwen3-ASR-1.7B在精度、多语言支持和抗噪能力上显著优于主流开源模型,尤其适合对数据隐私要求高或需处理混合语言的专业场景。
若硬件资源充足(显存≥12GB),推荐优先选择1.7B版本以获得最佳识别质量;若资源受限,可搭配0.6B轻量版或Qwen3-ForcedAligner-0.6B实现功能互补。对于企业用户,结合音频预处理(如降噪)和领域微调,可进一步将关键场景准确率提升至95%以上。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...