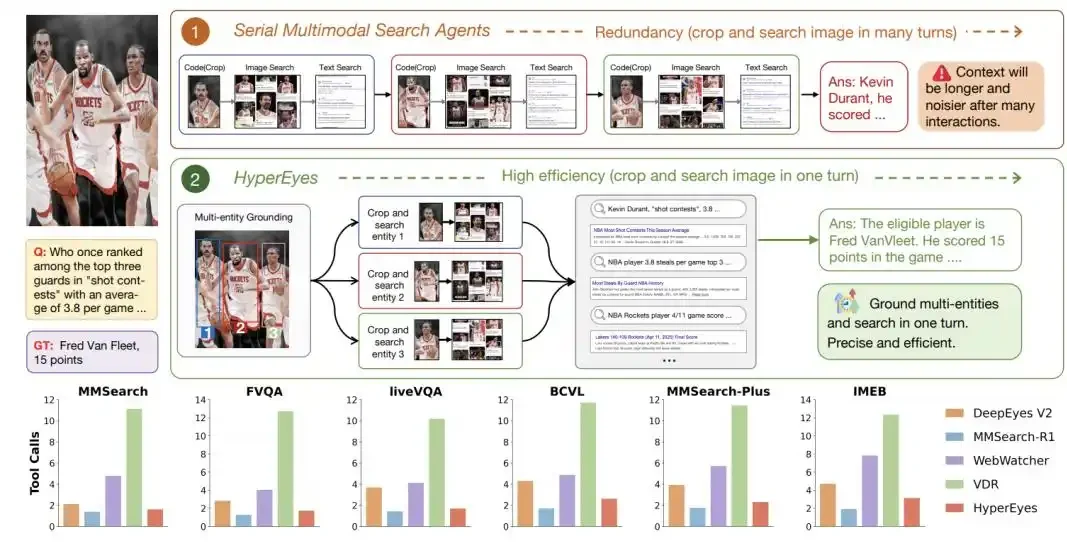
Qwen3.5-Omni是阿里巴巴通义千问正式发布的新一代端到端原生全模态大模型。
它打破了传统模型只能处理单一或特定组合模态的限制,实现了文本、图像、音频、视频四种模态的原生统一理解与生成,被誉为“听、看、说、做”一体化的智能引擎。

核心亮点:全模态与“Vibe Coding”
- 自然涌现的“Vibe Coding”能力
这是该模型最惊艳的创新。它并非经过专门训练,而是自然涌现出了音视频编程能力。- 怎么用: 你只需打开摄像头,对着手绘草图或实物,口述你的需求(例如“把这个草图变成网页”)。
- 效果: 模型能理解画面逻辑和语音指令,直接生成可运行的前端代码(如React、Vue)或Python原型,实现“动动嘴即可编程”。
- 极强的音视频理解与处理
- 超长上下文: 支持256K超长上下文窗口,可一次性处理10小时的音频或1小时的视频。
- 深度解析: 上传一段长视频(如50分钟美剧),它能在1分钟内完成全片解析,生成带时间戳的结构化笔记,精准标注人物关系、剧情转折点、背景音乐变化甚至镜头切换次数。
- 像真人一样的实时交互
- 语义打断: 在对话中,它能听懂你的意图。如果你只是咳嗽或随口附和(如“嗯嗯”),它会继续说;但如果你真正插话打断,它能瞬间接住话题。
- 情绪与音色控制: 支持指令控制声音的大小、语速和情绪(如“小声点”、“用开心的语气”)。
- 音色克隆: 上传一段录音,即可定制专属的 AI 助手音色,打造“数字分身”。
- 卓越的语言能力
- 支持113种语言及方言的语音识别(包括闽南语、海南话、毛利语等小众语种)。
- 支持36种语言的语音生成。
性能与架构
- 架构升级: 采用Hybrid-Attention MoE(混合注意力专家)架构,包含Thinker(负责推理)和Talker(负责生成语音)双模块。Thinker处理超长上下文,Talker基于ARIA 技术生成自然、稳定的语音。
- 性能表现: 在215项全模态评测中取得 SOTA(当前最佳)成绩。在音频理解、推理、翻译等任务上全面超越 Gemini-3.1 Pro,音视频理解能力总体达到其水平。
模型规格与使用
Qwen3.5-Omni提供了三种不同尺寸的版本,以满足不同场景的需求:
表格
| 版本 | 定位 | 适用场景 |
|---|---|---|
| Plus | 性能最强 | 复杂任务推理、长视频深度解析、高精度编程 |
| Flash | 速度与成本平衡 | 实时语音交互、直播字幕、快速内容审核 |
| Light | 轻量级 | 移动端部署、简单指令响应 |
如何体验:
- 普通用户: 可以前往Qwen Chat官网免费体验。
- 开发者/企业: 可通过 阿里云百炼 平台调用 API。目前新用户提供约7000万Tokens的免费额度,且输入价格极具竞争力(每百万 Tokens 输入不到 0.8 元)。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...