MiniMax M3是国产大模型公司MiniMax正式发布的新一代旗舰通用大模型。MiniMax M3是国内首个同时集齐“前沿编程与智能体能力、百万级超长上下文、原生多模态”三大核心能力的模型,也是目前全球唯一具备这一完整能力组合的开源选项。
MiniMax M3核心特点
- 顶尖的编程与智能体(Agent)能力:M3 在编程和复杂智能体任务上达到了行业顶尖水平,具备自主任务拆解、工具调用与多步推理的能力。官方表示,M3 生成的代码目标是“直接可交付”,而不仅仅是“能跑但需要人工修改”。
- 百万级超长上下文:M3最高支持 100万(1M)tokens 的超长上下文窗口,并保障至少512K tokens的稳定可用。这使得它能够一次性处理整本小说、复杂的代码仓库或长篇行业研报。
- 原生多模态与桌面操作:M3是一个从训练起点就开始进行文本、图片、视频混合训练的原生多模态模型。它不仅支持图片和视频的输入与理解,还具备操作电脑桌面的能力,可以在复杂的跨应用环境中执行任务。
MiniMax M3技术原理
M3 的强大能力主要得益于其底层的技术架构创新:
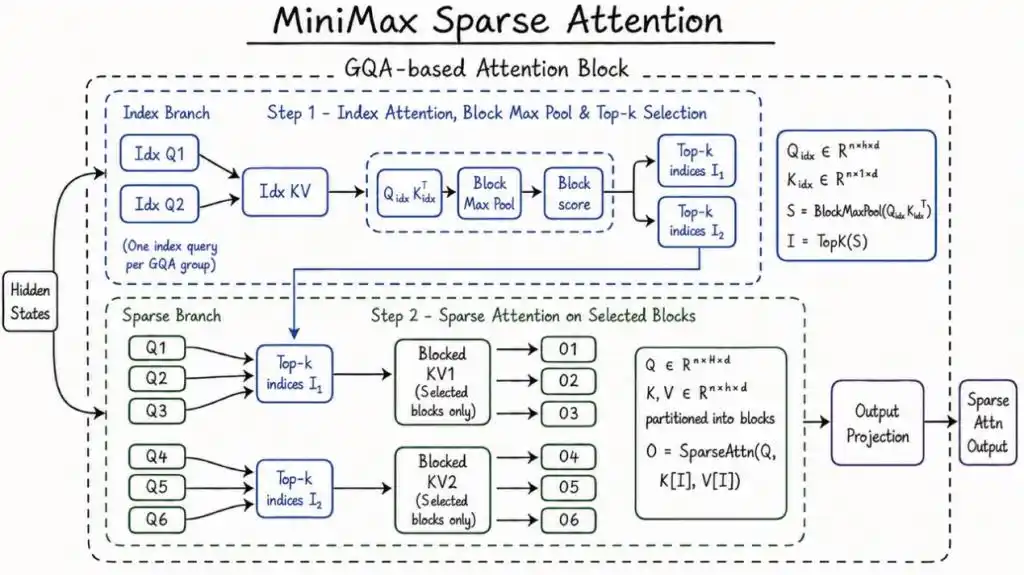
- 自研 MSA 稀疏注意力架构:M3 采用了 MiniMax 自研的全新稀疏注意力架构 MSA(MiniMax Sparse Attention)。传统Transformer架构在处理长序列时计算复杂度呈平方级增长(O(n²)),而 MSA 通过“索引分支”快速筛选关键信息,再由“稀疏分支”进行精准计算,将计算复杂度大幅降低至接近线性(O(n)),从底层解决了长文本处理的效率瓶颈。
- 交互式用户模拟器框架:为了提升编程和智能体能力的实用性,M3 在训练中引入了交互式用户模拟器。通过模拟真实开发者在协作过程中的需求补充、方案讨论和反馈修正等行为,让模型在训练阶段就接触到接近真实生产环境的复杂交互场景。
- 原生多模态混合训练:M3 重构了整套数据管线,将预训练数据规模扩充至百T量级,并从第零步开始进行多模态混合训练,使文本和视觉的语义空间实现了高度对齐。
MiniMax M3核心优势
- 极致的推理效率与成本优势:得益于 MSA 架构,在百万级上下文规模下,M3 的单 token 计算量仅为上一代模型的约 1/20。其预填充(Prefill)阶段速度提升近 10 倍,解码生成(Decoding)阶段速度提升超 15 倍。这意味着企业处理超长文档的算力成本可降低 80% 以上。
- 权威评测表现卓越:在多项国际权威评测中,M3 的表现均达到领先水平。例如,在衡量编程能力的 SWE-Bench Pro 上,M3 超过了GPT-5.5和Gemini 3.1 Pro;在多模态测试集 OmniDocBench 上,其得分超过 Gemini 3.1 Pro;在面向自主 Agent 的端到端评测框架 Claw-Eval 上,M3 拿到了最高分。
- 开源生态与开放性:作为目前全球唯一具备“百万上下文+顶尖编程+原生多模态”完整能力组合的开源模型,M3即将在HuggingFace和GitHub上完成开源,支持私有集群部署和微调,为开发者和企业提供了不依赖闭源API的高性能基础选项。
MiniMax M3同类产品对比
表格
| 对比维度 | MiniMax M3 | GPT-5.5 / Claude 3 Opus / Gemini 3.1 Pro |
|---|---|---|
| 长上下文能力 | 1M tokens,且计算效率极高(复杂度接近线性),算力成本降低80%以上。 | 目前均不支持1M tokens(如GPT-5.5为128K,Claude 3 Opus为200K),依赖分段拼接或外接RAG系统。 |
| 编程能力 | SWE-Bench Pro 得分 59.0%,超越 GPT-5.5 和 Gemini 3.1 Pro,接近 Claude 3 Opus。 | GPT-5.5 和 Gemini 3.1 Pro 得分低于 M3;Claude 3 Opus 略高于 M3(约60%-69%)。 |
| 多模态能力 | 原生多模态,从训练初期就混合文本、图片、视频,支持桌面操作,跨模态融合效率高。 | 多模态能力通常需要插件扩展,跨模态融合效率相对较低。 |
| 开源与部署 | 完全开源,模型权重和技术报告开放,企业可免费私有化部署,满足数据安全要求。 | 均为闭源产品,仅支持 API 调用,成本较高且无法满足敏感数据的私有化需求。 |
| 智能体能力 | 在 Claw-Eval 端到端评测中获得最高分,具备极强的自主任务拆解与多步推理能力。 | 在长链路 Agent 的连贯性上偶有断点,且均未披露同类端到端评测的具体成绩。 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...