
Dubbing v2是ElevenLabs推出的AI配音模型,首次实现 跨语言情感迁移,能够将原始语音中的语调、节奏、停顿、情绪起伏等表演细节完整保留并自然映射到目标语言中。
其核心突破在于 摒弃传统“转录→翻译→合成”的流水线模式,转而 直接基于原始音频的声学特征进行条件建模,使翻译后的语音听感上如同原说话人亲口用目标语言表达,彻底解决多语种内容中“语气丢失”的行业痛点。
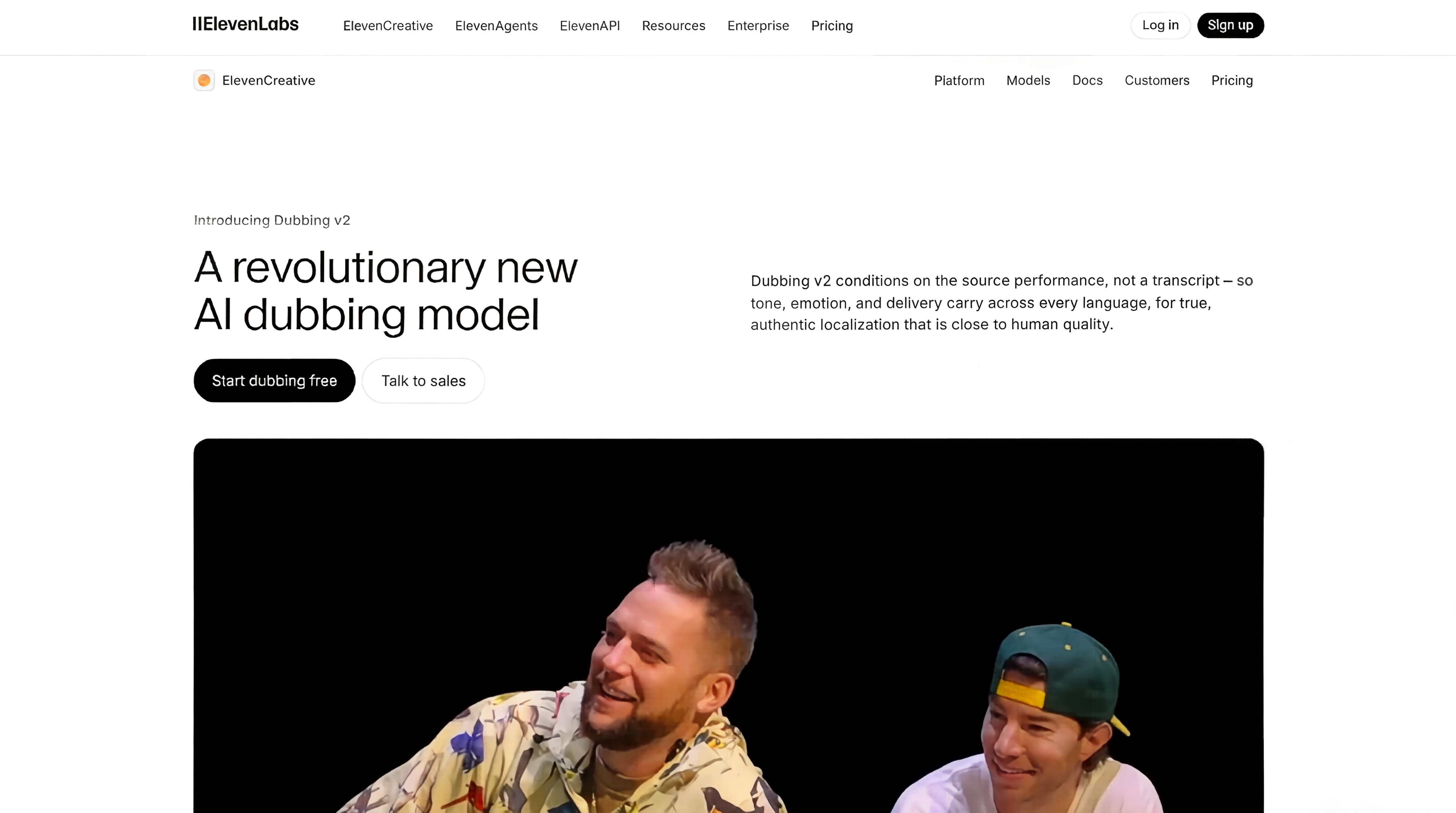
Dubbing v2核心特点
1. 本质创新
- 表演级配音范式:不再仅依赖文本脚本生成语音,而是 将原始音频的声学特征(语调、节奏、能量变化)作为生成条件,确保情感意图跨语言传递。
- 端到端音画对齐:直接输出 与原始视频口型、情绪起伏严格同步的配音,无需后期手动调整时序。
2. 与传统方案的关键差异
- 传统AI配音仅基于翻译后的文本生成语音,丢失原始表演的韵律细节;Dubbing v2则以原始音频为锚点,让目标语言语音“复刻”原说话人的表达风格。
Dubbing v2核心优势
1. 情感与表达保真
- 跨语言情绪一致性:原说话人的犹豫、重音、语速变化等 细微情感特征 能在目标语言中自然呈现,避免“机械朗读感”。
- 动态节奏适配:自动调整译文措辞与断句,匹配原始语音的节奏与停顿,确保声音起止点与画面动作精准同步。
2. 生产效率提升
- 自动化后期流程:口型同步与自然度校准 无需人工微调,后期处理时间减少 70% 以上。
- 多语种批量生成:单次输入可同步生成 90+ 语言版本,且各版本均保留原始表演特征。
3. 商业级可靠性
- 版权合规保障:生成内容 可直接商用,无法律风险。
- 高可用性:在影视级制作标准下,可用率超 90%,显著优于传统 AI 配音工具。
Dubbing v2技术原理
1. 原始表演条件建模
- 跨模态特征对齐:直接提取原始音频中的 韵律编码,作为生成目标语言语音的条件输入,跳过文本转录环节。
- 动态语序重构:模型自动优化译文的词汇顺序与句式结构,使其 符合目标语言的口语表达习惯,同时严格匹配原始语音的时间轴。
2. 帧级音画同步技术
- 时序约束生成:在扩散模型中引入时间对齐损失函数,强制生成的语音波形与原始视频的口型运动、肢体动作关键帧精准匹配。
- 静音段智能填充:保留原始音频中的自然停顿,避免翻译导致的节奏断裂。
3. 多语言情感迁移
- 情感向量解耦:将语音分解为语言内容与情感风格两个独立表征,仅替换语言部分,保留原始情感向量。
- 语种自适应调整:针对不同语言的音节密度、语调模式差异,动态校准语速与重音位置。
Dubbing v2核心功能
1. 情感保留配音
- 一键多语种转换:上传原始视频与翻译文本,自动生成 情感连贯的配音版本,支持 90+ 语言。
- 表演风格克隆:可指定保留原说话人的 特定情绪特征(如严肃、幽默、激动),无需额外标注。
2. 影视级制作支持
- 口型精准同步:生成语音的 音素边界与视频口型变化严格对齐,无需手动修正。
- 多角色分离处理:自动识别并独立处理 多人对话场景,确保角色声线与情绪区分度。
3. 工作流集成
- API 无缝对接:提供标准化接口,可嵌入Premiere Pro、DaVinci Resolve等主流剪辑软件。
- 批量任务处理:支持 长视频分段并行生成,单日可处理500+分钟内容。
Dubbing v2适用场景
1. 影视与流媒体本地化
- 纪录片/剧集多语种发行:保留原版解说的情感张力,避免“配音失真”导致的观众疏离感。
- 短视频全球化分发:快速将 YouTube/TikTok 内容适配至不同语言市场,维持创作者个人风格。
2. 企业级内容生产
- 跨国培训与营销视频:确保品牌宣传片、产品教程的 情绪传递一致性,强化跨文化认同。
- 实时会议同传配音:为国际会议生成 带情感的译制语音流,提升沟通效率。
3. 创作者生态
- 独立制片人工具:低成本制作 多语种版本内容,无需协调配音演员与后期团队。
- 教育内容本地化:保留讲师的 教学节奏与强调重点,提升非母语学习者的理解效果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...