Polar是英伟达(NVIDIA)开源的强化学习训练框架,专为解决代码智能体(如Codex、Claude Code、Qwen Code等)接入强化学习时的高成本与信号丢失问题而设计。
其核心突破在于无需修改智能体原生代码,即可通过API边界拦截技术 实现GRPO训练,显著提升性能并 缩短训练时间5.39倍。该框架通过保留原生执行细节与优化资源效率,推动智能体训练从实验室调优迈向工程化生产。
Polar核心定义与定位
1. 本质特征
- 非侵入式训练框架:在智能体与模型推理服务器之间插入 透明代理层,无需重写Codex CLI、Claude Code等现有执行框架的逻辑。
- 训练边界创新:将强化学习的训练入口从传统环境接口(
env.init()/env.step())转移至模型 API 边界,避免因框架改造导致的关键信息丢失。 - 目标场景聚焦:专为复杂长流程任务设计,解决单步任务向多步决策演进中的训练瓶颈。
2. 与传统方案的关键差异
- 传统方法需强行将智能体逻辑改写为标准环境接口,而 Polar 完全保留原生执行细节(工具调用链、上下文压缩、子智能体协作),仅通过代理层捕获训练信号。
Polar核心优势
1. 零成本接入现有框架
- 无需代码改造:兼容Anthropic、OpenAI、Google等主流API风格,智能体开发者无需调整原生逻辑即可接入 GRPO 训练。
- 避免信号丢失:直接记录原始提示词、采样 Token 及对数概率,完整保留多轮对话上下文与工具调用细节,确保训练信号高质量。
2. 性能与效率飞跃
- 任务性能突破:基于Qwen3.5-4B模型,在 SWE-Bench Verified 基准测试中:
- Codex 框架的 pass@1 分数从 3.8% 飙升至 26.4%。
- Pi 框架从 34.2% 提升至 40.4%,显著超越其他框架。
- 训练效率革命:
- 引入 prefix_merging 策略 后,训练墙钟时间 缩短 5.39 倍(从 189.5 分钟降至 35.2 分钟)。
- GPU 利用率从 20.4% 跃升至 87.7%,大幅降低算力门槛。
3. 工程化友好设计
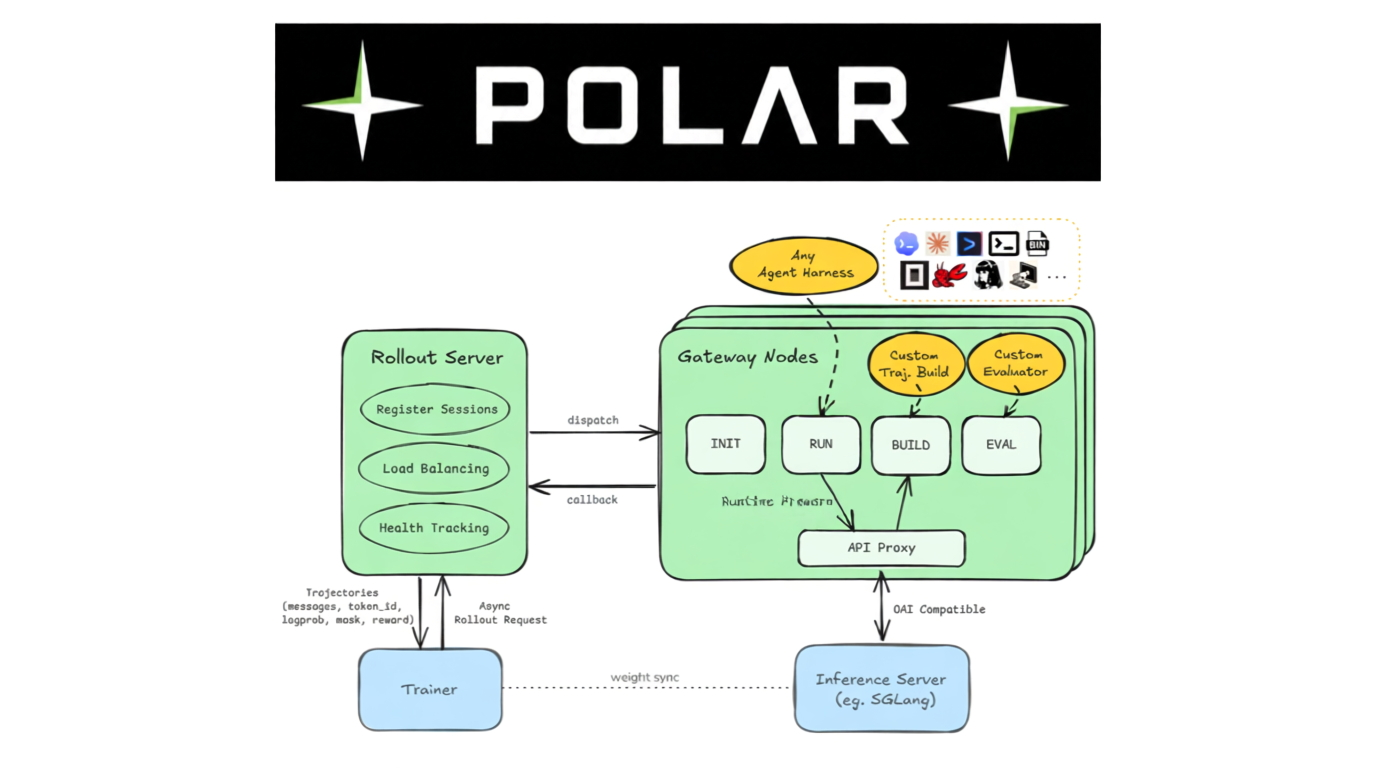
- 解耦式架构:Rollout Server 与 Gateway Node 分离职责,支持任务调度与资源回收的并行化。
- 长尾任务优化:通过 READY 缓冲区 实现运行时预热与评测预热的后台并行,消除 GPU 训练阻塞。
Polar技术原理
1. API 边界代理机制
- 透明拦截与转发:在智能体执行框架与模型推理服务器间部署 Gateway,自动转发请求 并记录关键数据(提示词、Token 采样、响应内容)。
- 轨迹动态重建:将拦截的零散数据 实时重构成强化学习所需的完整轨迹,供 GRPO 训练器直接消费。
2. 分布式系统架构
- Rollout Server:负责任务提交、会话调度、状态持久化及回调接收,充当训练流程的指挥中心。
- Gateway Node:管理会话全生命周期,包括运行时启动、执行框架准备、轨迹构建与资源回收,作为执行层的“管家”。
- 独立工作池设计:将初始化、运行中、后处理拆分为独立任务流,通过READY 缓冲区实现并行预热,减少长尾任务延迟。
3. 高效训练策略
- prefix_merging 优化:合并相似请求的前缀计算,将单步更新次数从 1185 次降至 218 次,避免重复计算。
- GRPO 算法适配:基于奖励信号动态调整策略,专为多步决策任务优化,使智能体在复杂流程中学习最优动作序列。
Polar核心功能
1. 无缝集成现有智能体
- 多框架兼容:原生支持Codex、Claude Code、Qwen Code、Pi等主流代码智能体框架,无需适配层开发。
- 黑盒化训练:将智能体视为 “黑盒环境”,仅需 API 交互即可采集训练数据。
2. 高效轨迹管理
- 自动化数据记录:实时捕获提示词、Token 级响应及对数概率,重建符合强化学习标准的轨迹格式。
- 动态资源调度:根据任务复杂度自动分配计算资源,优先保障高优先级训练任务。
3. 性能优化工具链
- 训练加速套件:集成 prefix_merging、异步预热等策略,最大化 GPU 利用率。
- 标准化接口:提供统一 API 供研究人员快速部署 GRPO 训练流程,降低工程复杂度。
Polar适用场景
1. 代码智能体强化学习
- 复杂软件工程任务:适用于需跨文件修改、依赖外部工具调用的仓库级代码生成。
- 多工具协作场景:保留子智能体协作逻辑,支持浏览器操作、操作系统交互等 长流程自动化任务。
2. 工业级模型训练
- 企业级开发环境:直接集成到现有代码智能体生产流程,避免因训练改造导致的稳定性风险。
- 资源受限场景:通过 87.7% 的 GPU 利用率 降低训练成本,适合算力有限的中小企业。
3. 研究与创新领域
- 智能体架构探索:为新型代码智能体提供 标准化训练基线,加速算法迭代。
- 多模态任务扩展:框架设计可迁移到图像生成、机器人控制等需长序列决策的领域,验证跨领域泛化能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...