
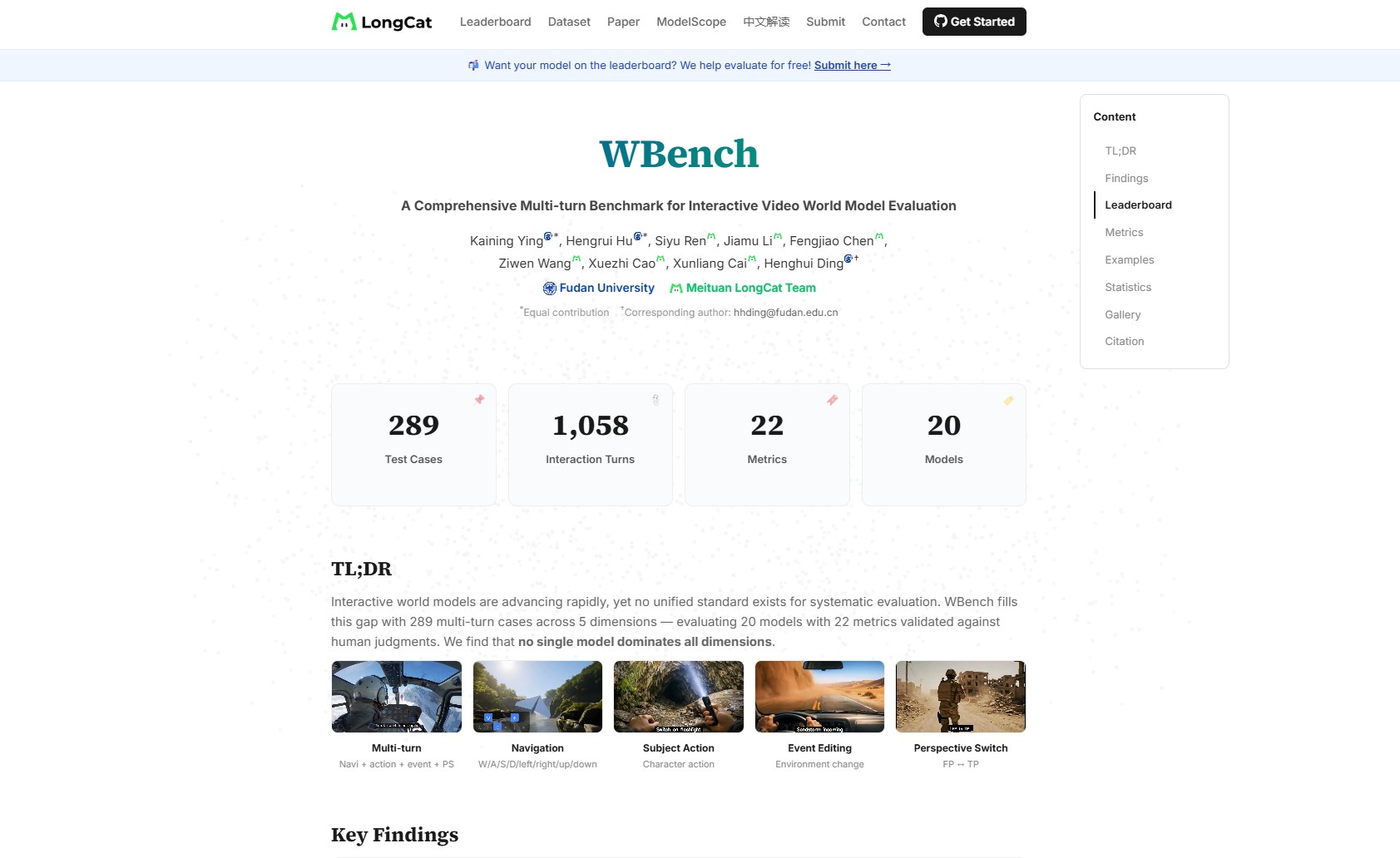
WBench是美团LongCat团队与复旦大学联合发布的首个面向交互式视频世界模型的系统性多轮评测基准,首次实现对世界模型在连续交互、多维度能力上的统一量化评估,而非仅关注单次生成的视频质量。当前研究发现,所有主流模型在多轮交互中均存在性能衰减问题,且导航能力与视频画质无直接关联,揭示了世界模型从”生成世界”到”稳定维护可交互世界”的关键差距。
WBench核心定义
- 本质属性:
WBench是专为交互式视频世界模型设计的多轮闭环评测系统,通过模拟用户与虚拟世界的连续交互过程(如多轮导航、动作指令),评估模型对世界状态的长期维护能力,而非仅测试单次视频生成质量。 - 关键突破:
- 填补评测空白:现有基准(如VBench)侧重视频审美指标(画质、流畅度),而WBench聚焦世界模型特有的交互稳定性、物理一致性等能力。
- 统一评估框架:首次支持文本指令、相机位姿、离散按键等不同控制范式的模型公平对比,解决碎片化评测问题。
WBench技术原理
1. 基准结构设计
- 测试规模:包含289个测试用例、1058轮交互,覆盖城市、自然、室内等6大类场景,支持第一/第三人称双视角及动物、人类等多类主体。
- 交互类型:定义四类可组合的核心交互方式:
- 导航(前进、转向等空间移动)
- 主体动作(角色行为控制)
- 事件编辑(修改场景事件逻辑)
- 视角切换(动态调整观察角度)
2. 五大评估维度
- 视频质量:评估基础渲染能力,包含美学质量、时序闪烁等5项指标,但仅反映表层生成效果。
- 设定遵循度:检验模型是否严格遵守初始世界设定,文本驱动模型普遍表现更优。
- 交互执行精度:衡量多轮指令的准确执行能力,导航类任务衰减最显著(第1轮到第4轮平均下降33分)。
- 一致性维护:检测空间参考系、物体外观等在交互中的稳定性,开源模型HY-World 1.5在此维度最突出。
- 物理合规性:验证是否符合物理规律,当前模型普遍仅依赖视觉先验,缺乏可控物理推理能力。
3. 自动化评测流程
- 无需人工标注:通过专业视觉模型与视觉大语言模型(VLM)自动计算所有指标,确保效率与客观性。
- 双轨协议设计:所有模型必须在158个共享导航用例上对比,文本驱动模型可扩展至全基准评测。
WBench核心优势
1. 诊断级细粒度分析能力
- 精准定位短板:例如发现”导航能力”与”视频画质”相关系数接近零,证明高画质模型未必具备空间控制能力。
- 多轮衰减量化:所有模型在连续交互后性能下降,导航任务从第1轮到第4轮平均衰减33分,揭示迭代生成范式的结构性缺陷。
2. 颠覆性研究结论
- 不存在全能模型:文本驱动模型(如Kling 3.0)擅长场景理解与设定遵循,专用世界模型(如HY-World 1.5)在导航控制上更优。
- 视角切换是最大挑战:所有模型在此任务平均分仅30.7,远低于其他交互类型。
- 开源模型潜力显著:HY-World 1.5的导航能力超越多数闭源模型,证明开源生态可推动关键能力突破。
3. 结构化难度差异
- 第一人称视角使导航更简单但设定维持更难,动物主体因动态复杂度成为导航最大难点。
- 物理合理性与导航控制呈弱负相关(r=-0.15),表明当前模型的物理表现多源于数据先验,非主动建模能力。
WBench适用人群
1. 核心用户群体
- 世界模型研发团队:通过细粒度指标定位技术瓶颈,针对性优化导航或物理模块。
- 具身智能/自动驾驶研究者:评估模型在模拟环境中的交互可靠性,筛选适配长时序任务的基座模型。
- 学术评测标准制定者:提供首个覆盖交互闭环的基准框架,推动评测体系从”单次生成”向”持续交互”演进。
2. 应用场景
- 模型选型参考:根据任务需求选择特长模型。
- 技术路线验证:检验新方法是否真正提升多轮交互稳定性,避免仅优化单次生成指标的局限。
- 开源生态建设:基准已全面开源,支持研究者快速复现结果并贡献新测试用例。
WBench项目地址
项目官网:https://meituan-longcat.github.io/WBench/
GitHub仓库:https://github.com/meituan-longcat/WBench
HuggingFace模型库:https://huggingface.co/datasets/meituan-longcat/WBench
技术论文:https://huggingface.co/papers/2605.25874
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...