
MusaCoder是摩尔线程推出的全球首个基于国产全功能GPU全栈训练的代码大模型,专为自动生成高性能GPU底层算子(CUDA/MUSA原生Kernel代码) 而设计,其完整训练与验证流程均在国产MTT S5000 GPU构建的夸娥智算集群上完成。
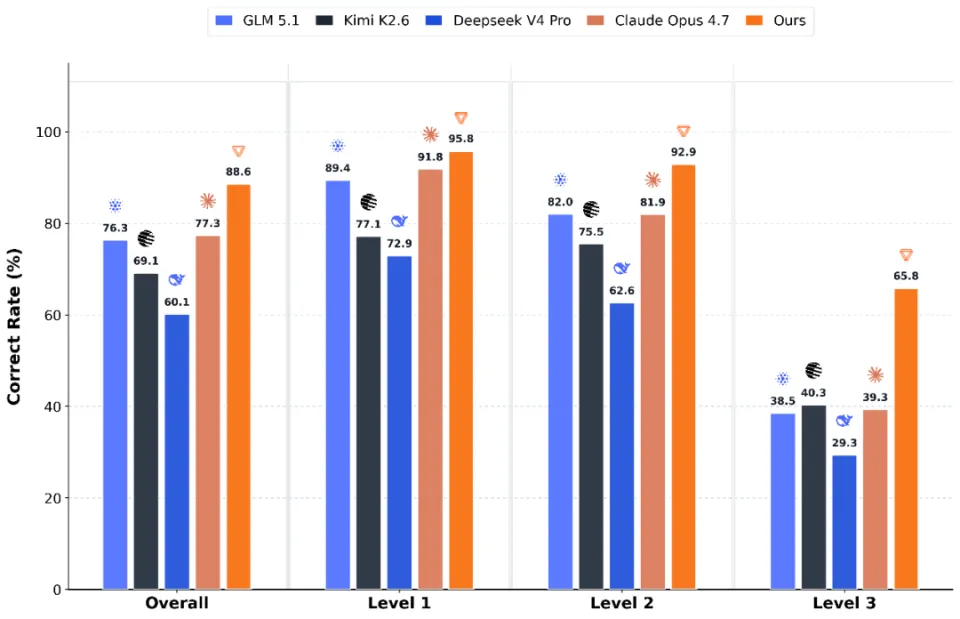
该模型在KernelBench评测中以Overall Pass@8 93.2%、Avg.@8 88.60%的准确率超越Claude Opus 4.7等国际主流代码模型,并首次验证了国产GPU可独立支撑代码大模型全周期后训练,标志着国产算力在AI基础设施领域的关键突破。
MusaCoder核心特点
1. 垂直领域专用化设计
- 聚焦GPU底层算子生成:专为从PyTorch标准算子自动生成CUDA/MUSA原生Kernel代码优化,而非通用编程任务,显著降低手写高性能算子的门槛。
- 双规模版本适配:提供9B与27B两种参数规模,兼顾轻量化部署与复杂任务性能需求。
2. 全流程国产化验证
- 全栈国产算力支撑:从数据构建、监督微调(SFT)、强化学习(RL)到代码编译执行验证的全链路训练,均依托国产MTT S5000 GPU完成。
- 硬件-软件深度协同:针对MUSA架构特性优化训练流程,解决国产GPU在代码生成任务中的编译栈、运行时兼容性问题。
MusaCoder技术原理
1. 全栈后训练方法论
- 结构化推理数据构建:通过显式注入张量形状(Shape)与内存布局信息,强化模型对GPU并行计算、线程组织等硬件特性的理解,解决通用代码模型迁移至Kernel生成的冷启动问题。
- 执行式验证闭环:基于MooreEval分布式系统实现代码自动编译、执行验证、性能测试与反作弊检测,将真实运行结果转化为训练反馈信号。
2. 强化学习优化机制
- 多轮修复能力增强:引入PrimeEcho(首论锚定多轮奖励)、MirrorPop(动态优先级采样)、BDR(缓冲动态重试) 等机制,提升模型在复杂任务中的调试与修复能力。
- 长尾样本针对性训练:对Level 3级高难度任务(涉及复杂shape推导、多算子组合)进行强化学习聚焦,显著缩小与简单任务的性能差距。
MusaCoder性能优势
1. 准确率与实用性能双领先
- 高难度任务突破:在KernelBench Level 3评测中,Pass@8与Avg.@8分别领先Claude Opus 4.7达18和26.5个百分点,体现对复杂GPU算子生成的强适应性。
- 真实性能收益:生成代码的Overall Faster Rate达15.0%(vs. PyTorch Eager)与9.2%(vs. torch.compile),不仅语法正确,更能通过性能验证。
2. 国产GPU训练能力验证
- 全周期算力承载:首次证明国产GPU可稳定支持代码大模型后训练的密集型任务(频繁编译、执行、验证),突破此前仅能支撑推理与微调的认知局限。
- 工程范式沉淀:形成可复用的国产GPU训练框架,涵盖硬件调度、评测系统与训练流程优化,为AI基础设施自主可控提供实践路径。
MusaCoder应用场景
1. GPU算子开发提效
- 自动化算子生成:开发者输入PyTorch算子定义,模型直接输出高性能CUDA/MUSA原生Kernel代码,大幅缩短手动调优周期。
- 算子修复与验证:对已有算子进行自动性能分析与代码修正,快速解决数值错误或硬件兼容性问题。
2. 国产GPU生态建设
- MUSA生态加速器:为基于摩尔线程GPU的开发者提供开箱即用的算子生成能力,降低国产硬件适配门槛。
- 研究与教学平台:高校及科研机构可基于其开源模型,开展异构计算编程、AI编译优化等方向的国产化技术研究。
3. AI基础设施创新
- 工具链整合基础:未来可与IDE插件、自动调试工具结合,形成从PyTorch参考实现到MUSA原生Kernel的完整生成-验证-优化闭环。
- 自主可控技术验证:为国产AI芯片在大模型训练全栈能力上提供关键实践案例,推动算力-算法-框架协同创新。
MusaCoder项目地址
HuggingFace模型库:https://huggingface.co/MooreThreads/MusaCoder-27B
arXiv技术论文:https://arxiv.org/pdf/2606.04847
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...