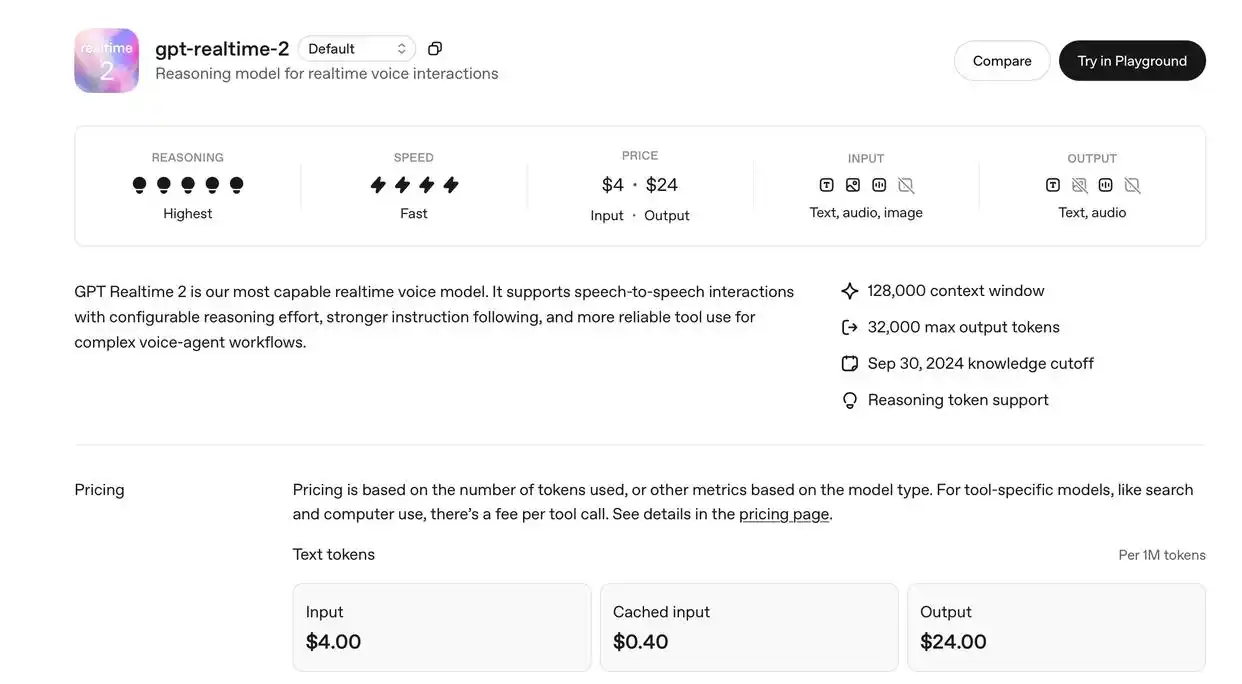
Confucius4-TTS是网易有道发布的开源语音合成引擎,属于“子曰4.0”大模型体系的核心组件。实现了3秒极速语音克隆、14种语言跨语种无口音合成,且无需参考文本即可完成音色与情感迁移。该模型采用全量开源策略(Apache 2.0协议),提供54GB完整资源包支持本地离线部署,显著降低了多语种语音克隆的技术门槛,主要面向内容创作、数字人、教育等场景提供高自然度的语音合成能力。

Confucius4-TTS核心定义
1. 行业首创性
- 作为全球首个支持14种语言跨语种无口音、免参考文本语音克隆的开源TTS模型,解决了传统语音合成中长期存在的三大技术瓶颈:克隆依赖大量样本、跨语种合成附带母语口音、情感表达生硬刻板。
- 定位为生产力工具,而非单纯的技术演示,直接服务于短视频出海、数字人配音等产业级需求。
2. 开源策略
- 采用全量开源模式,开放完整模型权重与工具链(非仅API接口),开发者可下载54GB资源包进行本地部署,商用无限制。
- 支持在普通服务器或高性能PC上离线运行,兼顾数据安全与定制化需求。
Confucius4-TTS核心特点
1. 极速零样本语音克隆
- 仅需3秒音频输入即可完成音色克隆,无需提供参考文本或额外训练,大幅降低素材门槛。
- 克隆音色与原声相似度超过85%,克隆任务准确度达97%,接近真人复刻水平。
2. 跨语种无口音合成
- 支持中、英、日、韩、德、法、西、印尼、意、泰、葡、俄、马来、越南语等14种语言无缝切换。
- 彻底消除跨语种口音违和感,例如用中文原声音色输出英语时,发音地道自然,无中式外语腔调。
3. 情感韵律精准迁移
- 区别于传统TTS依赖文本标签控制情感的方式,可自动提取参考音频中的情感特征(如语调、语速、韵律),实现跨语种无损迁移。
- 例如生气语句的中文输入,合成后的外语输出仍保留愤怒情绪,适配复杂情感表达场景。
Confucius4-TTS技术原理
1. 底层架构革新
- 摒弃传统声码器方案(如初代EmotiVoice的HiFi-GAN声码器+Speaker ID查表),转向GPT式语义大模型主干架构。
- 采用语音编码器+大语言模型(LLM)的端到端框架,结合SSL预训练特征提取与ECAPA-TDNN可学习说话人编码器,通过Flow Matching流匹配生成高保真语音。
2. 跨语种无口音实现机制
- 通过声学特征解耦技术,将音色、语言、情感三要素分离建模,确保目标语言合成时仅保留原声音色特征,剥离母语发音习惯。
- 利用多语言预训练数据优化音素映射,使非母语发音符合目标语言的音系规则与韵律模式。
3. 零样本克隆关键创新
- 可学习说话人编码器直接从短音频中提取音色嵌入向量,无需语言适配训练。
- Flow Matching生成框架高效对齐声学特征分布,避免传统方案因样本不足导致的失真问题。
Confucius4-TTS核心功能
1. 基础能力
- 支持语言:14种(中文、英语、西班牙语、法语、德语、韩语、泰语、越南语等)。
- 克隆速度:3秒内完成音色复刻,无需参考文本。
- 情感迁移:支持跨语种语调、韵律同步迁移,保留原始情绪表达。
2. 性能表现
- 跨语种自然度:实测中,中文音色输出英语时无机械感或口音残留,听感接近母语者。
- 场景适应性:在新闻播报、情感叙事、企业宣传等复杂语境下保持稳健性,避免传统TTS的生硬断句。
Confucius4-TTS应用场景
1. 跨境内容生产
- 短视频/短剧出海:创作者单次录制原声,即可批量生成14国语言配音,无需多语种演员。
- 降低制作成本:数字人虚拟主播统一跨语种音色,避免为不同语言重新录制声线。
2. 智慧教育
- 多语种AI外教:生成地道发音素材,支持精准模仿教师音色与情感,提升语言学习沉浸感。
- 个性化教学:学生可上传教师语音,生成定制化习题讲解音频。
3. 企业级应用
- 出海品牌本地化:快速完成多语种语音播报、宣传片配音,保持品牌声纹一致性。
- 客服与数字人:为虚拟客服提供情感化、多语言响应能力,增强用户交互体验。
Confucius4-TTS项目地址
GitHub仓库:https://github.com/netease-youdao/Confucius4-TTS
HuggingFace模型库:https://huggingface.co/netease-youdao/Confucius4-TTS
在线体验Demo:https://confucius4-tts.youdao.com/gradio/
Confucius4-TTS的核心意义在于将语音克隆技术从“实验室演示”推进至“产业可用”阶段,其3秒克隆、跨语种无口音、情感迁移三大能力直击内容全球化生产的核心痛点。尽管在硬件门槛和语言覆盖上存在局限,但作为首个实现全栈开源的高性能跨语种TTS方案,它为开发者提供了可快速集成的国产化技术底座,尤其适合短视频出海、数字人等对多语种配音效率要求严苛的场景。未来随着社区生态完善,其在教育、文旅等领域的应用潜力将进一步释放。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...