
MMSkills是上海交通大学与小红书团队联合研发的多模态技能框架,旨在解决视觉智能体在操作图形界面时因缺乏视觉状态理解而导致的任务失败问题。将程序性知识从纯文本升级为图文结合的动态技能包,使AI能像人类一样通过实时观察界面状态执行任务,而非依赖固定坐标或机械套用指令。

MMSkills核心定义
1. 本质定位
- 多模态程序性知识表示框架:将操作流程、视觉状态线索与验证证据封装为可复用的技能单元,使AI能根据实时界面状态动态决策。
- 联合研发背景:由上海交通大学智能视觉实验室与小红书AI团队合作提出,聚焦真实场景中的视觉智能体落地瓶颈。
2. 关键特点
- 状态驱动决策:技能包明确标注关键视觉状态的触发条件与验证方式(例如“仅当检测到工作表标签高亮时才切换”),避免盲目操作。
- 多视角证据整合:每个状态关联全局界面、控件特写、操作前后对比图,帮助AI识别界面微小变化。
- 轻量化设计:仅保留诊断性状态(如“目标工作表切换完成”的视觉特征),剔除冗余信息以控制上下文长度。
- 动态适配能力:AI能根据实时屏幕内容自主匹配技能包中的状态,无需预设固定坐标或模板。
MMSkills技术原理
1. 技能包结构
每个MMSkills包含三要素:
- 文本操作流程:描述基础步骤(如“打开图表向导”)。
- 运行时状态卡片:定义触发条件(如“任务明确指定目标工作表时启用”)、视觉线索(如“关注标签栏高亮状态”)及验证方式(如“确认图表标题与指令完全一致”)。
- 多视角关键帧:为每个状态提供全局截图、局部特写、操作前后对比参考图。
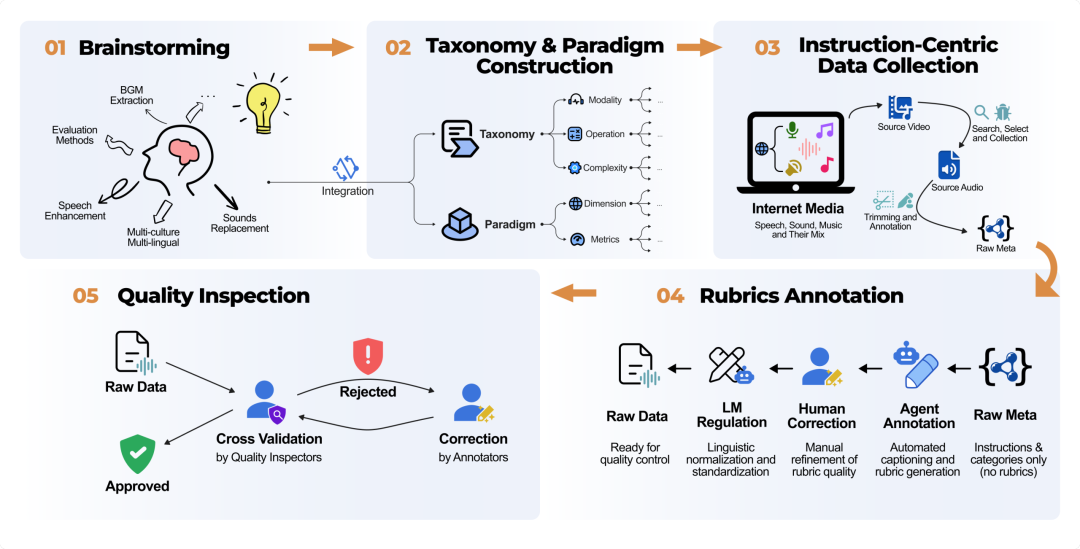
2. 自动化技能生成
- 轨迹聚类提炼:从公开操作录像中自动聚类相似任务,剔除原始演示噪声,提取可复用的状态转移逻辑。
- 五阶段生成流程:依次完成任务聚类、技能规划、合并去重、文本草案生成、视觉证据匹配与审计,全程无需人工标注。
- 非测试数据驱动:仅使用公开非评测轨迹生成技能,避免过拟合测试场景。
3. 分支加载机制
- 临时分支验证:当主AI调用技能时,开启独立分支检查状态卡片与参考图,避免主上下文被图像淹没。
- 结构化指导输出:分支仅返回精简指令(如“剪切图表→切换Sheet2→粘贴→验证标题”),不传递原始图片,防止AI锚定参考图。
- 动态证据筛选:根据当前屏幕智能选择最相关的视觉线索,忽略无关状态。
MMSkills主要功能
1. 提升任务成功率
- 在桌面自动化任务中,任务完成率最高提升近15个百分点(如Qwen3-VL-235B模型从21.34%升至39.17%)。
- 精准定位目标元素:例如创建图表时能识别当前激活工作表,避免因界面状态误判导致的错误。
2. 优化行为效率
- 降低无效操作比例:盲目点击行为从75.8%降至63.7%,键盘输入与任务完成动作比例显著上升。
- 消除重复动作:重复操作频率从21.8%骤降至6.2%,避免“反复点击同一位置”的死循环。
- 缩短任务路径:平均操作步数减少约35%,提升执行效率。
3. 增强状态感知
- 实时验证关键节点:通过状态卡片中的视觉验证线索(如“图表标题是否匹配指令”),AI能自主判断任务进度。
- 动态调整执行策略:若检测到状态异常(如命令行语法错误),可即时调用纠错技能包修正流程。
MMSkills适用人群
1. 开发者与企业
- 桌面自动化工具开发者:需构建能操作Excel、浏览器等GUI应用的智能体,无需人工编写复杂坐标规则。
- 企业IT管理系统:适用于需统一管理AI技能权限、用量审计的场景(如控制PDF解析、SQL优化等技能的调用范围)。
2. 行业应用场景
- 客服与运维系统:处理需截图验证的工单(如“指导用户定位软件报错弹窗”),降低人工介入成本。
- 知识沉淀与培训:将专家操作经验自动转化为图文并茂的可执行指南,避免因人员流动导致的知识流失。
3. 终端用户价值
- 降低使用门槛:用户只需说明目标,AI能自主解析界面状态,无需精确描述操作细节。
- 提升交互可靠性:尤其适用于界面频繁更新的软件环境(如办公套件、设计工具),减少因版本差异导致的AI失效问题。
MMSkills项目地址
项目官网:https://zkangning.github.io/MMSkills_for_Visual_Agents/
GitHub仓库:https://github.com/zkangning/MMSkills_for_Visual_Agents
HuggingFace模型库:https://huggingface.co/datasets/zhangkangning/mmskills
arXiv技术论文:https://arxiv.org/pdf/2605.13527
MMSkills的核心突破在于将AI的“操作能力”从依赖固定文本指令升级为基于视觉状态的理解与决策,使智能体真正具备人类“看图办事”的灵活性。其技术价值不仅限于桌面自动化,还可扩展至游戏交互、工业控制等需实时视觉反馈的领域,为多模态智能体在复杂环境中的落地提供关键支撑。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...