
Sakana Fugu是由日本AI公司Sakana AI发布的多智能体编排系统,其本质并非基础大模型,而是能智能调度其他模型完成任务的“协调器”。它通过动态组合多个专家模型的优势,在复杂任务中实现接近或部分超越Anthropic Fable 5等顶尖模型的表现,解决单一模型的能力局限与供应链风险,而非单纯追求参数规模。
Sakana Fugu核心特点
1. 单一API封装的多智能体系统
- 用户无感调度:
对外表现为标准语言模型API,内部却能自动拆解任务、选择最优模型组合、验证结果并合成答案,全程无需用户配置编排逻辑。 - 动态模型池管理:
底层模型池完全可替换(如Claude、GPT等),当某模型因政策或故障无法访问时,系统自动切换替代方案,避免服务中断。
2. 双版本差异化定位
- Fugu(标准版):
平衡响应速度与性能,适合日常编码、聊天机器人等交互场景,轻量级调度策略减少延迟。 - Fugu Ultra(旗舰版):
专注复杂多步骤任务,强制调用深度专家模型池,通过多轮验证与递归协作提升结果可靠性,响应时间与Token消耗显著更高。
3. 供应链韧性设计
- 规避出口管制风险:
针对Anthropic Fable 5等模型因地缘政治限制访问的问题,Fugu通过多供应商模型池确保关键业务连续性,Sakana AI将其定义为 “AI主权”实践。 - 合规灵活性:
企业可自定义模型池范围(如剔除特定厂商模型),满足数据隐私与区域合规要求。
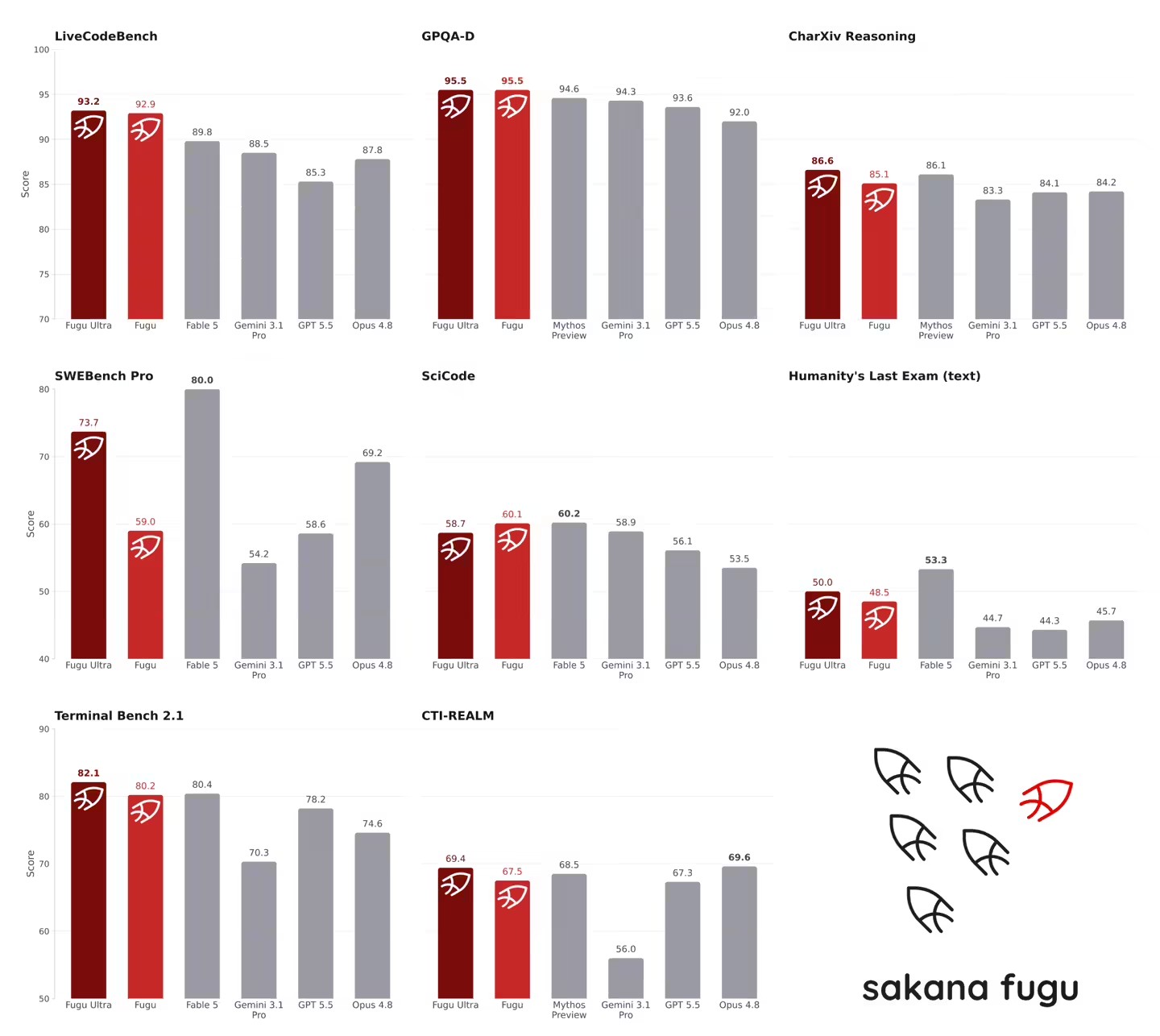
Sakana Fugu技术原理
1. 基于学习的动态编排机制
- 角色化任务分配:
将任务拆解为 Thinker(规划)、Worker(执行)、Verifier(验证) 三类角色,轻量级协调器通过强化学习动态分配模型,避免人工预设规则的僵化性。 - 递归式协作优化:
复杂任务中,系统自动触发多轮子任务调度(如先调用代码模型生成方案,再调用安全模型验证漏洞),结果经交叉验证后整合输出。
2. TRINITY与Conductor技术融合
- TRINITY框架:
通过进化算法训练协调器,使其在推理过程中动态调整模型角色分工,提升多智能体协作效率。 - Conductor强化学习:
训练协调器自主发现最优通信模式与提示策略,使模型池的集体表现超过单一最强模型,且无需暴露底层模型权重。
3. 性能与成本平衡设计
- 非叠加计费模式:
Fugu Ultra内部调用多个模型时,仅按参与模型中的最高费率计费(如调用GPT-5.5与Claude Opus,按Opus定价),避免隐性成本激增。 - 缓存优化机制:
对重复子任务自动缓存中间结果,减少冗余计算,长流程任务成本降低约30%。
Sakana Fugu核心功能
1. 复杂任务自动化处理
- 长链条任务执行:
支持端到端完成多步骤工作流(如“分析漏洞→生成修复代码→验证安全性”),减少人工干预环节。 - 跨领域知识整合:
自动调用数学、代码、安全等垂直领域专家模型,解决需多学科知识融合的问题(如科研论文中的公式推导与实验设计)。
2. 高可靠性结果保障
- 多模型交叉验证:
对关键输出(如金融分析结论)并行调用多个模型验证,显著降低单模型幻觉风险。 - 递归自我修正:
若Verifier角色检测到矛盾,系统自动回溯修正,而非直接输出错误结果。
3. 企业级定制能力
- 模型池白名单控制:
企业可限定仅使用合规模型(如仅调用欧盟境内部署的模型),满足数据主权要求。 - 角色稳定性强化:
在长会话中维持一致的人设与逻辑,避免单模型常见的“对话漂移”问题。
Sakana Fugu适用人群
1. 企业级技术团队
- 软件开发与安全团队:
用于复杂代码审查(可揪出单模型遗漏的深层漏洞)、自动化渗透测试等需多轮验证的场景。 - 金融与政务系统:
依赖高可靠性与供应链韧性的领域,规避单一模型断供导致的业务中断风险。
2. 科研与专业分析者
- 跨学科研究人员:
需整合数学推导、文献分析、实验设计的复杂课题。 - 长周期数据分析:
处理需多步骤迭代的任务,系统自动维持中间状态一致性。
3. 高风险决策支持场景
- 法律与合规部门:
生成需多方验证的结论,降低单模型误判概率。 - 关键基础设施运维:
依赖连续稳定AI服务的工业控制系统,模型池冗余设计保障7×24小时可用性。
最后想说
Sakana Fugu的核心突破在于将AI能力竞争从“单体模型规模”转向“智能调度效率”:
- 技术层面,它并非更强基础模型,而是通过动态编排现有模型实现复杂任务的更高可靠性与抗风险能力;
- 应用层面,其价值集中于长链条、高风险场景(如代码审查、科研分析),普通问答中优势不显著。
该系统主要面向企业级用户,需注意:性能上限受限于底层模型池,且复杂任务延迟较高。对于追求稳定性的专业场景,Fugu提供了一种规避单一供应商依赖的新路径,但需结合具体任务评估调度成本与收益。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...