GLM-5.2核心特点
1. 真实可用的100万token上下文
- 非参数虚标:不同于多数模型仅纸面支持长上下文,GLM-5.2在实际加载整本技术文档、中型代码仓库(如10万行级项目)时仍保持逻辑连贯性,无信息丢失或“失忆”问题。
- 长任务稳定性:连续自治时长从GLM-5.1的8小时提升至12小时以上,可完成跨文件批量修改、工具调用与项目交付的闭环任务。
2. 专注编程与工程化场景
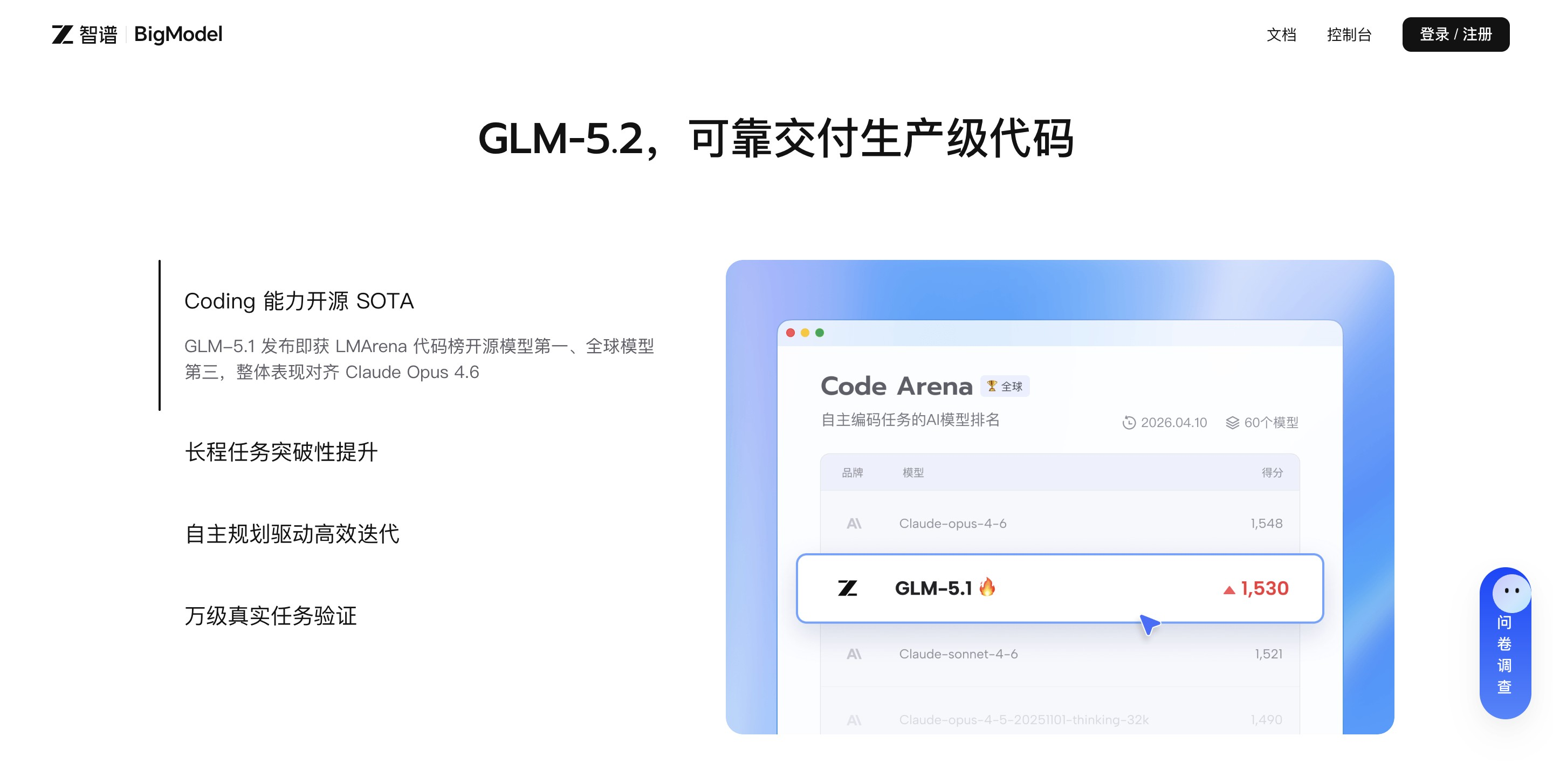
- 代码能力全球前列:在SWE-bench Pro权威测试中得分58.4%,超越GPT-5.2(55.6%)和Claude Opus 4.6(57.3%),被开发者称为国产最强Coding模型。
- 全流程工程支持:不仅能生成代码片段,更能自主完成排错、调试、重构、测试验证,交付可直接运行的完整项目。
3. 完全开源与商用自由
- MIT协议开源:模型权重允许免费商用、二次修改、闭源衍生,无版权捆绑或分成限制,彻底规避闭源模型“随时下架”风险。
- 取消订阅壁垒:GLM Coding Plan所有档位(含Lite入门版)均开放完整版100万token能力,无需额外付费解锁。
GLM-5.2技术优势
1. 长上下文处理能力
- 低幻觉率:在百万级token输入下,关键信息保留率显著高于同类模型,例如能精准定位1个月前日志中的第661行错误根源。
- 动态注意力优化:通过DSA稀疏注意力机制,聚焦关键代码逻辑,避免长文本推理时的性能衰减,1M上下文推理成本仅比200K增加20%。
2. 高效推理与成本控制
- 轻量化MoE架构:744B总参数中仅激活40B有效参数,推理速度达500+ tokens/s(比GLM-5.1提升25%),兼顾高性能与低显存占用。
- 国产算力适配:全程基于华为昇腾芯片训练与部署,无需依赖NVIDIA生态,企业可私有化部署涉密项目。
3. 工程级任务可靠性
- 多轮工具调用稳定性:在连续700次工具调用中保持输出一致性,状态管理能力支撑复杂Agent工作流(如自动生成测试用例并修复18个Bug)。
- 代码结构感知:能区分A*、Dijkstra等算法的逻辑差异,独立实现优先队列等底层模块,避免直接调用现成库的“糊弄式”输出。
GLM-5.2技术原理
1. 架构设计
- MoE混合专家系统:256个专业“模型专家”分工协作,推理时动态激活40B参数,平衡能力与效率。
- Slime异步强化学习:通过代码执行反馈循环持续优化生成逻辑,例如自动运行Headless Chrome验证音频链路。
2. 长上下文优化
- 真实场景训练:基于28.5万亿Token工程化语料(含完整代码仓库),强化对跨文件依赖、项目结构的理解。
- 注意力层创新:DSA机制动态压缩冗余上下文,确保长序列中关键信息不被稀释,实测1M长度下性能衰减低于同类模型。
3. 推理加速技术
- 两级思考模式:提供“常规”与“最大努力”模式,复杂任务自动延长推理时间以提升准确性。
- 缓存复用机制:对项目结构、依赖库等静态上下文哈希缓存,减少重复请求的计算开销。
GLM-5.2核心功能
1. 项目级代码生成
- 端到端交付能力:输入需求描述即可生成900行以上完整项目代码,包含交互逻辑与测试验证。
- 多算法协同实现:能同时处理A*、Dijkstra等算法的独立逻辑,避免状态混淆,支持分屏对比与统计功能。
2. 自主Agent工作流
- 长程任务闭环:自主规划从需求分析到部署的全流程,例如4小时内完成177,000 token工作量,包含29轮自我审查与18次Bug修复。
- 工具链深度集成:与ZCode 3.0等工具联动,实现Git分支管理、项目知识库调用等工程化操作。
3. 文档与日志分析
- 百万字级文档处理:可解析整本技术手册或服务器日志,精准定位跨时间线的根因。
- 中文场景优化:对中文注释、变量命名的解析能力显著优于海外模型,适配本土开发环境。
GLM-5.2应用场景
1. 大型工程开发
- 代码库级重构:一次性加载中型项目全量代码,自主完成跨文件依赖调整与性能优化。
- 遗留系统迁移:分析旧系统日志与文档,生成适配新架构的迁移方案,降低人工排查成本。
2. 自动化开发流水线
- CI/CD增强:集成至开发流程,自动修复测试失败用例并提交合规代码。
- 低代码平台支撑:为无代码工具提供逻辑生成引擎,将自然语言需求转化为可执行工作流。
3. 企业级知识管理
- 私有化部署分析:在企业内网解析涉密文档或代码库,避免数据外泄风险。
- 技术文档智能生成:基于代码库自动生成API文档与架构说明,保持与源码同步更新。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...